How does Google handle duplicate content across multiple sources?
Google identifies duplicate content through content fingerprinting, canonical tag resolution, and link-graph authority signals, then clusters duplicates so only one canonical version ranks. For reputation work this means mass syndication no longer amplifies reach; original content on authoritative outlets, or quality syndication with correct canonical signals, is what moves the needle.
Google’s duplicate-handling pipeline has three stages: content fingerprinting hashes each page and flags near-identical copies; canonical tag resolution reads the rel=canonical signal to identify the publisher’s intended original URL; and link-graph clustering groups all copies and picks the single version best supported by inbound authority. Only that canonical version competes for rankings, the rest are filtered from results or shown as clustered alternates.
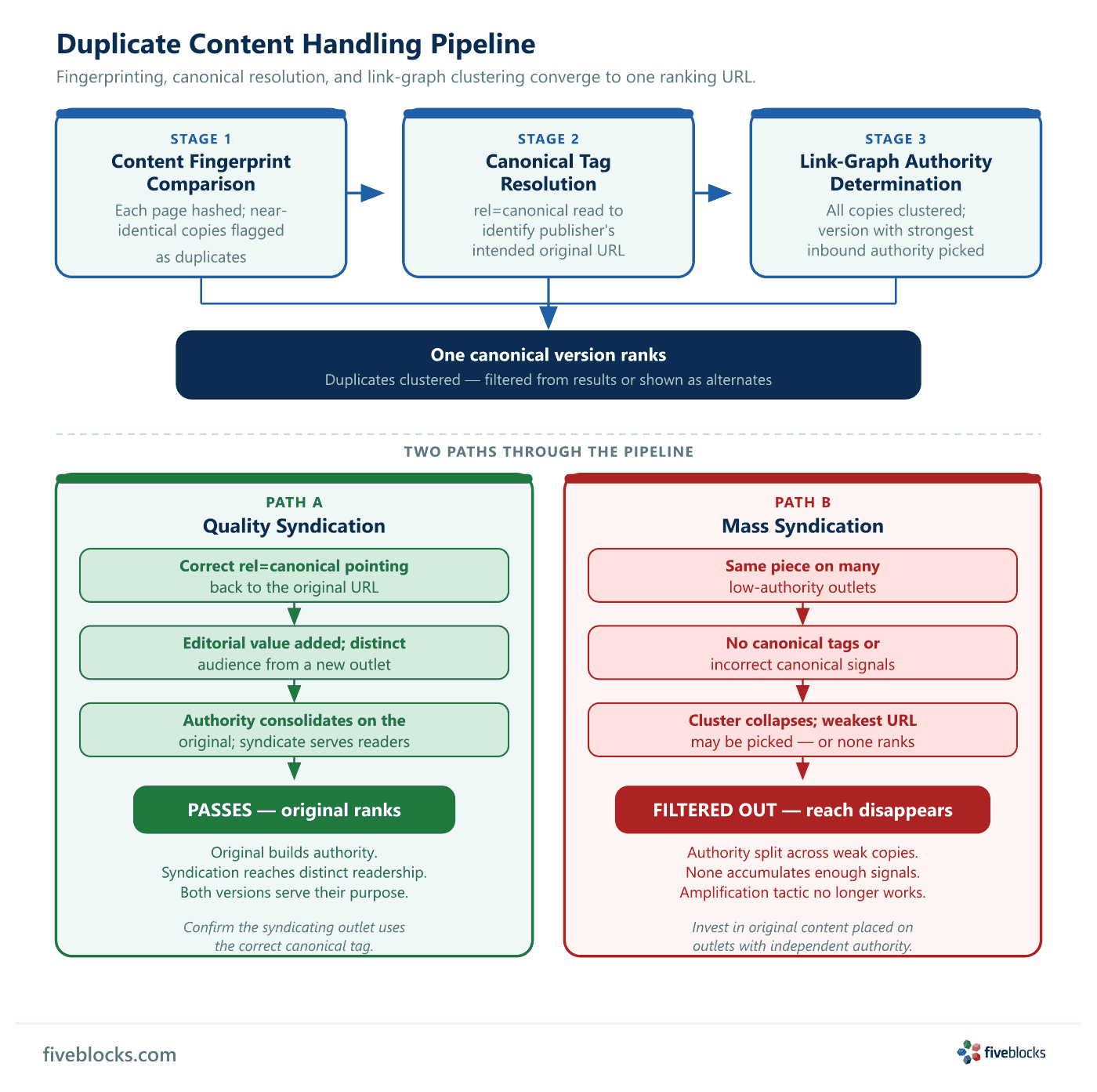
Two paths through the duplicate pipeline
- Quality syndication, the syndicating outlet adds genuine editorial value, its audience and authority are different from the source’s, and it uses the correct
rel=canonicalpointing back to the original. This can work: the original builds authority while the syndicated version serves a distinct readership. - Mass syndication, the same piece lands on many low-authority sites with no canonical signals or incorrect ones. Google collapses the cluster, picks the weakest candidate (or the wrong one), and filters the rest. Reach does not multiply; it disappears.
Implication for reputation management
The classic “publish everywhere” amplification tactic largely stopped working when Google closed the canonicalization gap. The practical conclusion:
- Invest in genuinely original content placed on outlets with their own independent authority.
- If syndication is part of a placement plan, confirm the syndicating outlet uses the correct canonical tag and adds real editorial framing, otherwise the original may not be the version Google picks.
- Track which URL Google treats as canonical for important placements; tools like Google Search Console’s URL Inspection report the chosen canonical directly.
Last reviewed: 19/05/2026