How do large language models like ChatGPT form opinions about companies?
LLMs do not form opinions. They synthesize a response from two streams, a training corpus fixed at a cutoff date and live retrieval from the web at query time, weighting sources by authority. To change what an AI engine says about your company, improve the sources it draws on: independent media coverage and Wikipedia carry more weight than additional owned pages.
Large language models like ChatGPT do not form opinions in the human sense. When you ask one about a company, it does not consult a stored view; it assembles an answer on the spot from the sources available to it, weights them by authority, and renders the result in confident prose.
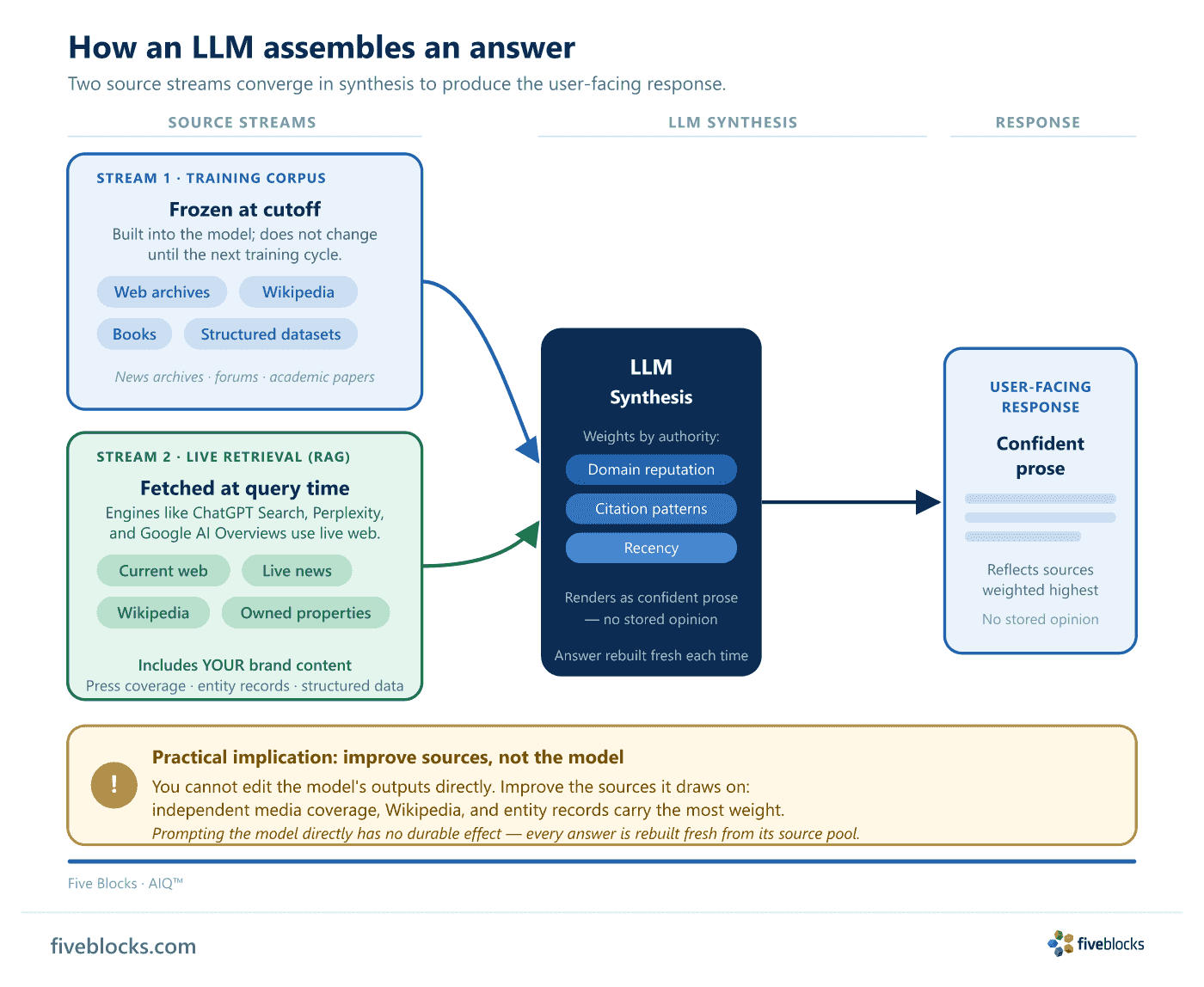
The two streams an LLM synthesizes from
- Training corpus, the body of text the model was built on, fixed at its training cutoff: web pages, news archives, books, Wikipedia, and structured datasets. Once a model is trained, this layer does not change until the next training cycle.
- Live retrieval (RAG), at query time, retrieval-augmented generation lets the engine fetch current content from the live web rather than relying on training data alone. Engines such as ChatGPT Search, Perplexity, and Google AI Overviews use this approach, so they can incorporate content published after the training cutoff.
From these two streams the engine identifies relevant sources, weights them by signals such as domain reputation, citation patterns, and recency, and synthesizes a single answer. A reputation program cannot edit the model’s outputs directly; what can be changed is the quality and authority of the sources those outputs are drawn from.
Which source types to prioritize
Not all sources carry equal weight. Based on how engines weigh their inputs when answering questions about a company, the highest-leverage source types are:
- Independent media coverage. Search and AI engines weight credible third-party outlets more heavily than additional owned pages. A fact reported by an authoritative, independent outlet is a stronger signal than the same fact in a press release or on the company’s own website.
- Wikipedia. Wikipedia is treated as a foundational reference for entity questions by ChatGPT and other major AI engines, drawing on it from both training data and retrieval. Google’s AI Overviews and Gemini weight it as a primary source when summarizing a subject.
- Structured entity records (Wikidata, Knowledge Graph, schema markup). AI engines query structured sources such as Wikidata and the Knowledge Graph for entity facts, and schema markup with sameAs links helps engines attach a page to the correct entity. Accurate entity infrastructure gives every other source layer a stronger anchor.
- Owned properties with clear authorship and schema markup. A company’s official site contributes to the source pool, but its weight is lower than independent coverage. Structured data on owned properties increases the chance content is surfaced and attributed correctly.
- Forum and community content (e.g. Reddit). Forum content has become a mainstream AI source. Reddit ranks among the most-cited domains in AI-generated answers in recent citation studies, so brand narratives that circulate in community discussions can influence AI outputs, for better or worse.
Press releases and wire-only distribution carry less weight than earned media; AI engines downgrade wire releases that lack independent third-party coverage. Prompting the model directly has no lasting effect: the engine rebuilds every answer fresh from its source pool and does not retain what a user tells it between sessions.
Last reviewed: 19/05/2026