What is the difference between AI training data and AI retrieval data?
Quick answer
Training data is the fixed corpus a model learned during pre-training; retrieval data is what it fetches live at query time. Reputation work targets both: training influence is slower to land but durable, while retrieval is near-real-time but only holds while the strong sources stay prominent.
Training data and retrieval data are two ways to shape what AI engines say about you, and they work on different timescales. A reputation program has to address both.
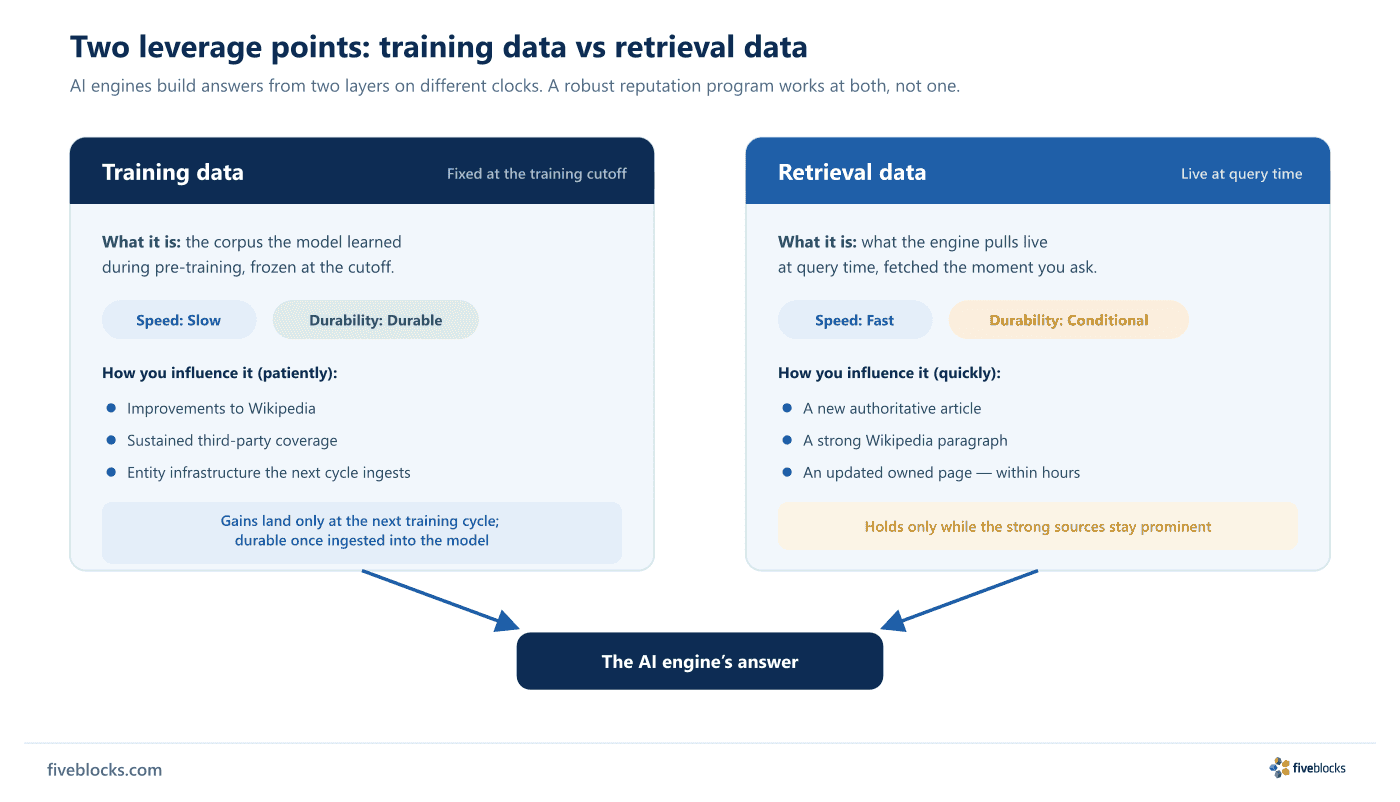
| Training data | Retrieval data | |
|---|---|---|
| What it is | The corpus the model was built on, fixed at the training cutoff. | What an engine pulls live at query time. |
| How you influence it | Patiently: improvements to Wikipedia, sustained third-party coverage, and entity infrastructure that the next training cycle will ingest. | Quickly: a new authoritative article, a strong Wikipedia paragraph, or an updated owned page can affect answers within hours. |
| Speed | Slow, gains land only at the next training cycle. | Fast, near-real-time. |
| Durability | Durable: once ingested, it becomes part of the model’s baseline understanding. | Conditional: gains hold only as long as the strong sources stay prominent. |
The two layers cover different needs and move at different speeds, which is why a reputation program works at both rather than picking one.
Last reviewed: 19/05/2026