How do AI models handle disambiguation for people and companies with common names?
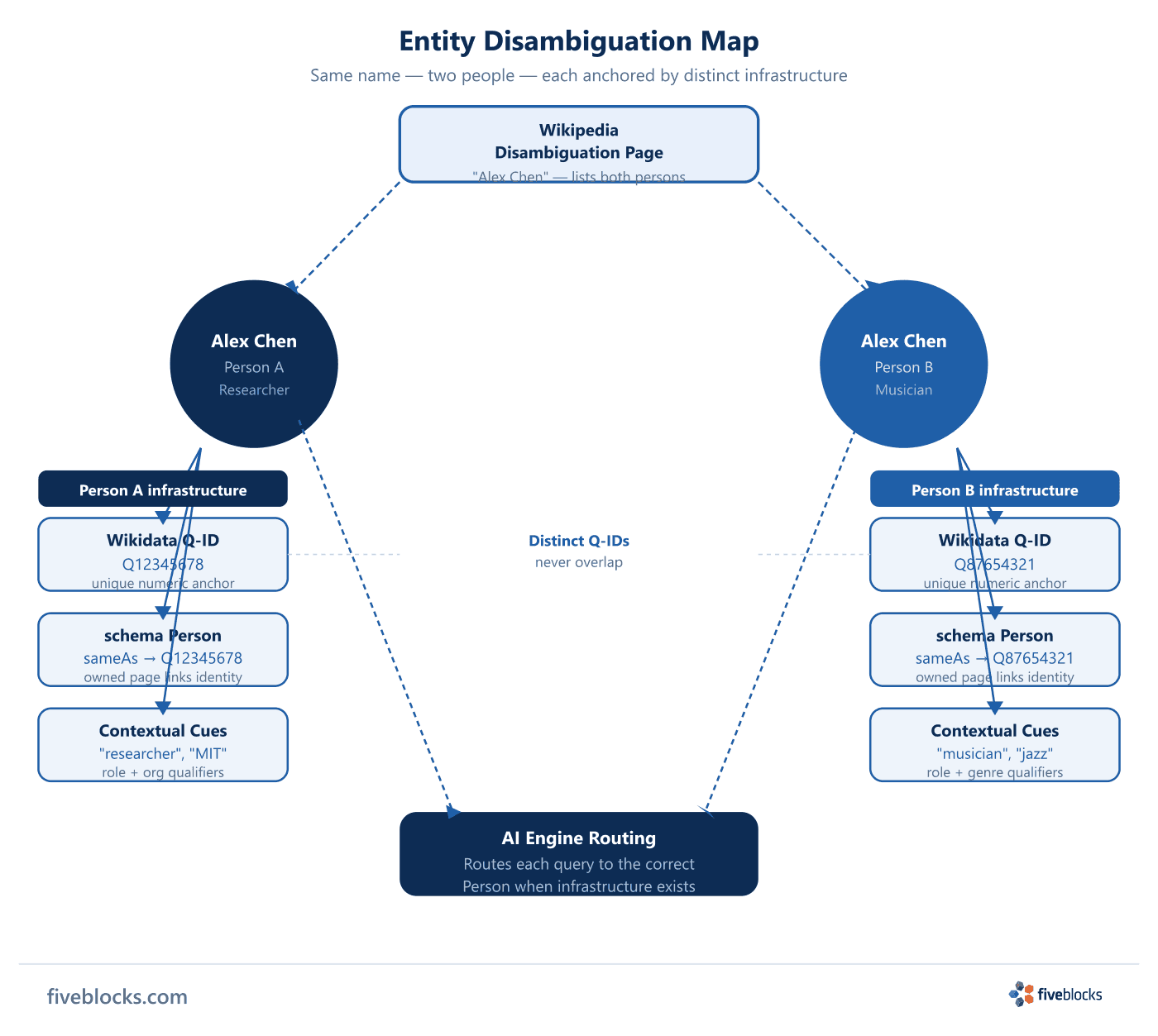
AI engines separate entities with common names through four infrastructure layers: a Wikipedia disambiguation page that explicitly lists distinct subjects, a unique Wikidata Q-ID that anchors each entity unambiguously, schema.org Person markup with sameAs links connecting owned pages to canonical identifiers, and contextual cues in the user’s query. When these layers are present, engines route correctly; when they are absent, conflation is the predictable result.
AI engines handle common-name disambiguation through entity infrastructure, not through guesswork. When the infrastructure is strong, the engines route a query about one person to that person and not to anyone who shares the name. When the infrastructure is absent or incomplete, the engines guess, and the guesses can be wrong in damaging ways.
The four disambiguation layers
-
Wikipedia disambiguation pages
When multiple distinct subjects share the same name, Wikipedia creates a dedicated disambiguation page that lists each subject and links to its article. This is one of the primary signals engines use to distinguish entities with identical or near-identical names. Without a disambiguation page or a clearly differentiated article title, the entity becomes harder for an engine to separate from its namesake. Wikipedia’s own documentation describes a disambiguation page as a non-article page that lists the various meanings attached to a name and links to the articles that cover each one.
-
Wikidata unique identifiers (Q-IDs)
Every Wikidata item carries a unique Q-ID, a number prefixed with the letter Q, such as Q42 for Douglas Adams, that anchors the entity unambiguously regardless of how many other entities share a similar name. Wikidata’s own introduction defines items as uniquely identified by Q-numbers. Each language-version Wikipedia article for that entity is linked as a sitelink on the same Wikidata item, creating a machine-readable identity anchor that AI engines and the Google Knowledge Graph can query directly. A missing or incomplete Wikidata entry removes this anchor and forces the engine to rely on weaker, more ambiguous signals.
-
Schema.org Person markup with sameAs links
Schema.org’s
sameAsproperty lets a brand’s owned web pages declare a reference URL that “unambiguously indicates the item’s identity”, typically the entity’s Wikipedia article, Wikidata entry, or official website. When this markup is present on a Person or Organization page, it gives AI engines and the Knowledge Graph an explicit machine-readable signal connecting the page to the canonical entity. This is the layer where owned infrastructure actively asserts identity rather than waiting for engines to infer it from surrounding text. -
Contextual cues in the query
Industry descriptors, geographic qualifiers, role titles, and co-mentioned related entities in the user’s query all act as soft disambiguation signals. These cues help when the structural infrastructure above is strong; they cannot fully compensate for absent Wikidata entries or missing schema markup when name overlap is close. Contextual cues are the layer the engine leans on when the machine-readable layers do not resolve the ambiguity cleanly.
The conflation failure mode
When entity infrastructure is weak, no Wikidata entry, no schema markup, no clean Wikipedia disambiguation page, AI engines are more likely to conflate the target with another entity sharing the same or a similar name. Research on large language models confirms that models can consistently mishandle broad classes of human names when disambiguating contextual cues are absent. The fix is upstream: a complete Wikidata item with sourced statements and sitelinks, schema markup with sameAs pointing to Wikipedia and Wikidata, and a clear Wikipedia disambiguation page or distinct article title. These are infrastructure interventions; prompt-layer workarounds do not address the root cause.
Last reviewed: 19/05/2026