Behind the Scenes at Five Blocks: Moshe
In this next edition of our employee spotlight series introduces Moshe, who started out studying education before realizing he preferred being the student rather than the teacher. That pivot eventually led him into tech, where he combined curiosity, business thinking, and a love of learning into a career.
Outside of work, you’ll likely find him hiking, reading, or searching for the perfect coffee spot.
Let’s get to know him.

How would you describe your job in a single sentence (or two or three)?
My role really varies week to week depending on what my teams need. I spend a lot of time researching the industry, tracking competitors, and looking for upcoming events and trends, then turning those insights into content or reports. Part of my work is to learn different industries and their specific digital reputation management needs so I can create tailored deliverables for BizDev. I also contribute to Five Blocks’ AIQ, where I help write, test, and improve prompts and user content. Right now, I’m also focused on cleaning up our HubSpot data to make sure everything is organized and accurate.
If your role had a theme song, what would it be?
If my role had a theme song, it would be “Don’t Stop Me Now” by Queen. Every week I’m diving into new information and getting to know new tools, always learning and moving full speed ahead. (Also I just like that song).

If you could master a skill, what would it be?
I’m a pretty slow reader, it would be cool to get through books faster.
Sweet, salty, or spicy – which snack can you not resist?
Is “all of the above” an option?

What’s your go-to karaoke song (even if you’d never sing it in public)?
I’d have to go with “Don’t Stop Me Now” again. but definitely not in public, for everyone else’s sake.
What’s the weirdest or most random thing on your desk right now?
The weirdest thing on my home desk right now is a fidget cube I “borrowed” from my brother years ago… and never gave back.

What is your absolute favorite snack?
Anything with peanut butter in it!

Coffee, tea, or something else to start the day?
Filter coffee and a book

A small thing that always makes your day better:
Going on a walk while listening to music or something interesting.

What is your favorite quote?
“You do not rise to the level of your goals. You fall to the level of your systems.” – James Clear
Thank you, Moshe! It’s clear that someone who thrives on a good book and a steady cup of filter coffee can handle any challenge with total focus. More spotlights are on the way. And if you are searching for your next great read or some stellar coffee house recommendations, Moshe is definitely worth a conversation.
Digital Reputation Management
Reputation is no longer a media problem. It’s an infrastructure problem.
What Google and AI say about your brand is your reputation. We manage it.

For most of the last two decades, “reputation” lived inside the communications function. A CCO managed the narrative through earned media, owned channels, and relationships with reporters. The story was the product.
That world still exists. But it now runs on top of a second, deeper layer – one that determines whether the story actually reaches anyone.
When a board member, a regulator, an LP, a journalist, a recruit, or a customer wants to understand a company or an executive, they do not start with a press release.
They typically start with Google, and increasingly, they are moving to ChatGPT, Gemini, Claude, Perplexity, or Copilot. What those systems return – the ten blue links, the knowledge panel, the AI-generated summary – is the reputation. Everything else is upstream of it.
Most PR firms are not built to manage that layer. We are. It is the only thing we do, and we have been doing it since 2003.
What “Digital Reputation Management” actually means at Five Blocks
The phrase gets used loosely. In our work, it has a precise meaning: the disciplined, ongoing management of every signal that Google and AI models use to construct a picture of a brand or an individual.
That includes, at minimum:
- Google search results for branded and reputational queries – the first three pages, every SERP feature (knowledge panel, People Also Ask, Top Stories, AI Overviews, sitelinks), and how they shift over time.
- AI-generated narratives in ChatGPT, Gemini, Claude, Perplexity, Copilot, Grok, and Google’s AI Mode – what the model says, which sources it draws from, and how the story compares to peers.
- Wikipedia – the single most influential third-party source on the open web, cited heavily by AI models and surfaced prominently in Google.
- Knowledge graphs and entity signals – Wikidata, Crunchbase, schema markup, structured data, and the dozens of signals that tell machines who a company or person is.
- Owned content – corporate sites, executive bios, FAQ pages, leadership content – structured to be readable by both humans and AI.
- Earned and third-party content – the press, directories, and reference sites that AI treats as authoritative.
Each of these is a discipline. Most firms work in one or two of them. We work in all of them, in-house, and we treat them as a single connected system – because that is how Google and AI treat them.
Why this is different from PR, SEO, or traditional ORM
We get asked this constantly, so it is worth being direct.
We are not a PR firm. We do not pitch reporters, place stories, or manage media relationships. We work alongside the firms that do – including most of the major strategic communications and IR firms in New York, London, and globally. They handle narrative and media. We handle the technical and content infrastructure that determines whether that narrative actually reaches people through Google and AI.
We are not an SEO agency. Traditional SEO optimizes for traffic and conversion – keywords, backlinks, technical performance. Reputation work optimizes for what specific people see when they search a specific name or brand. Different goals, different toolkit, different success metric.
We are not a traditional ORM or “suppression” firm. Most firms in that category fight the algorithm – they build networks of low-quality content, spin up profiles, and try to push negative results down through volume. The work is brittle, often unethical, and increasingly ineffective as Google and AI get better at recognizing manipulation.
We do the opposite. We work with the platforms – studying how Google ranks, how AI models source their answers, what Wikipedia accepts as credible – and we curate a client’s broader digital presence so that the preferred narrative is the one those systems naturally elevate. The work is durable because it is built on the same logic the platforms themselves use.
Our approach
Every engagement starts with the same conviction: you cannot manage what you have not measured, and you cannot fix what you do not understand.
1. We lead with data
Before we recommend anything, we audit. Across Google search results for every reputational query that matters, across all major AI models, across Wikipedia and Wikidata, across knowledge panels and structured data, across third-party citations. We map the full landscape – what is there, where it is coming from, and why the systems are surfacing it.
This produces two things our clients consistently tell us they cannot get elsewhere: a clear, evidence-based picture of the actual problem, and an internal alignment tool that gets stakeholders to agree on what to do.
Our proprietary platforms make this possible at depth:
- IMPACT™ tracks Google search results daily across tens of thousands of queries for every client. We have monitored more than 100,000 brand search footprints over the platform’s history. Clients see, in real time, which results dominate, how rankings shift, and where the leverage points are.
- AIQ is the only platform of its kind built specifically to monitor AI narratives. It tracks how ChatGPT, Gemini, Claude, Copilot, Perplexity, and Grok describe a brand – sentiment, sources cited, peer comparisons, narrative drift over time. Continuously updated.
- WikiAlerts monitors every relevant Wikipedia page and edit, in real time, across all language editions.
- GeoSearch tracks how results shift across geographies – critical for multinationals and for executives whose stakeholders are spread across markets.
2. We work every layer that matters, in-house
Five Blocks does not outsource. Every piece of work, Wikipedia research and editing, technical structured data implementation, AI content strategy, owned content development, entity optimization, is executed by our own team, in our offices in New York and Jerusalem.
Our staff averages well over a decade of experience in digital reputation. We have 10+ people dedicated exclusively to Wikipedia, with a depth of platform knowledge that is not matched anywhere in the industry. Our turnover is low. The senior practitioner assigned to a client in month one is the same one accountable in month twelve.
This matters because reputation work, done correctly, is highly contextual. There is no playbook that substitutes for someone who knows the case, the industry, the personalities, and the platforms intimately. We build that institutional knowledge inside the engagement, and we keep it there.
3. We use peer analysis as a methodology, not a sales pitch
One of our operating principles: do not reinvent the wheel. In every engagement, we study what is working for a client’s peers and competitors – which content AI models are citing, which Wikipedia structures are most defensible, which third-party sources are driving positive narratives, which owned content is breaking through.
Our AIQ platform makes this systematic. We can tell a client, with data, which sources are shaping how they are described in ChatGPT versus how a peer is described – and what to do about the gap. It accelerates results and grounds every recommendation in what is actually working in that competitive context.
4. We build for durability, not for the dashboard
There is a temptation in this industry to optimize for what looks good in a monthly report. We optimize for what holds up six, twelve, twenty-four months out – through algorithm changes, news cycles, and the rapid evolution of AI models.
That means investing in the structural assets that compound: a strong Wikipedia presence, well-architected owned content, accurate entity data, durable third-party citations. The work is slower than vanity tactics. It is also why our client relationships average many years.
What ongoing digital reputation management looks like
Most of our engagements are not crisis work. They are ongoing programs designed to keep a brand or an executive in a strong position – so that when something does happen, the foundation is already there.
A typical program includes:
Continuous monitoring. IMPACT™ and AIQ run daily. Clients have real-time visibility into where they stand in Google and across AI models. Anomalies, ranking shifts, narrative drift, new negative content – we see it as it happens, often before the client does.
Active curation of search results. We work the queries that matter, branded searches, executive names, reputational queries, industry-specific terms – and we manage what surfaces on them. That means strengthening preferred content, building new assets where gaps exist, and addressing problematic results through the structural levers that actually move rankings.
Wikipedia stewardship. For clients with Wikipedia presence (or who should have one), we manage notability, accuracy, sourcing, and the ongoing editorial process – transparently, with disclosed conflict-of-interest editing per Wikipedia’s terms of service. For clients without a Wikipedia page, we assess whether one is appropriate and, if so, build it correctly the first time.
AI narrative management. We monitor how each major AI model describes the client, identify the sources driving the narrative, and shape those sources – corporate site content, Wikipedia, earned media, structured data – so that the AI-generated story is accurate, complete, and favorable. This is the newest discipline in reputation, and the one most firms have not figured out.
Entity optimization. Wikidata entries, Google Knowledge Graph signals, schema markup on the corporate site, executive entity hygiene across the open web. The unglamorous infrastructure that determines whether AI and search engines correctly understand who the client is.
Owned content development and optimization. We help clients build the kind of content, executive bios, leadership pages, FAQ structures, thought leadership architecture, that performs in both human search and AI synthesis. Often this is the highest-leverage work we do.
Reporting and review. Formal monthly reports, weekly check-ins where appropriate, ad-hoc updates as activity warrants, and continuous platform access through IMPACT™ and AIQ. Clients are never guessing where they stand.
How we work with PR and communications partners
The majority of our engagements involve a PR or strategic communications firm working alongside us. That is by design. PR teams shape narrative; we shape the infrastructure that determines whether the narrative is what people actually find.
In practice this looks like:
- Joint stakeholder mapping. Comms identifies the audiences and moments that matter; we identify the queries, platforms, and signals that audience will actually encounter.
- Coordinated content strategy. When the comms team places earned media, we ensure the placements are structured to be discoverable and citable by AI. When we recommend owned content, the comms team owns voice and message; we own architecture and discoverability.
- Crisis preparation, not just response. We map vulnerabilities before they become incidents, exposed search queries, weak entity data, Wikipedia risk, AI narrative gaps – and the PR partner builds the messaging playbook against that map.
- Clear lines. No turf wars. We do not pitch reporters; PR partners do not edit Wikipedia. The collaboration works because the disciplines do not overlap.
Why this matters now
Two things have changed in the last twenty-four months.
First, AI-generated answers are rapidly replacing the search query as the primary way people get information about brands and individuals. The narrative those models produce is built from a specific set of sources – Wikipedia, corporate websites, earned media, structured data – and it is being formed right now, whether the subject is paying attention or not.
Second, the cost of getting it wrong has gone up. A flawed AI summary that gets cited by a journalist, repeated by an analyst, or surfaced to a board member becomes the working version of the story. Correcting it after the fact is far harder than shaping it correctly in the first place.
Five Blocks has spent twenty-plus years working on exactly the building blocks AI models now read. We were doing this work before AI made it urgent. The firms that figure out the AI layer will be the firms that already understood the search and Wikipedia layers – because they are the same problem, in a new wrapper.
Frequently Asked Questions
How is Five Blocks different from a traditional ORM or “suppression” firm? Traditional ORM fights the algorithm – building low-quality content networks to push results down. We work with the platforms. We study how Google and AI models source and prioritize content, and we curate a client’s broader digital presence so the preferred narrative is the one those systems naturally surface. The work is durable because it is built on the same logic the platforms use.
How is Five Blocks different from a PR firm doing digital reputation? PR firms manage narrative and media relationships. We manage the technical and content infrastructure that determines what Google and AI actually return. Different skills, different tools, different success metric. Most major PR firms partner with us rather than compete with us.
Do you outsource any work? No. All Five Blocks work is done in-house, by our team. No white-label vendors, no offshore execution.
How long do engagements typically last? Most clients work with us on an ongoing basis. Reputation infrastructure is not a one-time project – search results shift, AI models evolve, news cycles change, executives transition. Programs are designed to maintain and strengthen the foundation over time. Crisis-only engagements are usually two to six months; broader programs run for years.
Can Five Blocks actually change what AI models say about a client? Yes – through structural means. We improve the sources AI models read: Wikipedia, corporate website content, earned media, entity signals. When those sources improve, the AI-generated narrative improves. Our AIQ platform measures the change directly. This is not a workaround; it is how AI reputation management works.
Does Five Blocks remove negative content? Where it is possible and appropriate, yes – through direct outreach, factual correction requests, legal angles where they exist, and in some cases acquiring defunct sites that host defamatory content. Removal is not always feasible, which is why our broader methodology focuses on shaping what surfaces in Google and AI regardless of whether any individual piece comes down.
How do you report to clients? Formal monthly reports, weekly check-ins where the engagement warrants, ad-hoc updates as activity requires, and continuous real-time access to IMPACT™ (search) and AIQ (AI). Clients are never guessing where they stand.
Do you work confidentially through PR partners? Yes. Many of our engagements run through strategic communications and PR firms. We also work directly with end-clients. Either model is standard.
How much does an engagement cost? Programs are structured as monthly retainers, scoped to the work required. Crisis engagements typically run $15,000 to $30,000 per month. Ongoing programs vary based on scale – a single executive looks different from a multi-brand corporate mandate. We will scope and price transparently after an initial audit.
Do you work outside the United States? Yes. We work across many languages and geographies.
Is the work confidential? Always. No exceptions.
Where to start
The right entry point for almost every prospective client is the same: a Digital Brand Audit. It is fast, it is concrete, and it produces a clear, evidence-based picture of where the client stands across Google, AI models, Wikipedia, and entity signals – along with a prioritized roadmap for what to do about it.
For active situations, we begin a crisis engagement within 24 to 48 hours.
For ongoing programs, we typically scope, audit, and launch within two to three weeks of engagement.
Contact us to discuss your situation – whether you are evaluating partners, building defenses before a crisis, or already in one.
Behind the Scenes at Five Blocks: Gavi
Next up in our employee spotlight series: Gavi, an Account Manager who has backpacked across six continents, played volleyball at a national level, and jumped out of a plane twice. Somewhere in between all of that, she built a career in communications.
Let’s get to know her.

If you could instantly master a new skill, what would it be?
I wish I were a master at cleaning and organizing quickly at home. It’s not my strong point, and I wish I could download that quality for instantaneous results. I’d also appreciate having instant access to a new language or two.

What’s the best piece of advice you’ve ever received?
Be your biggest and best advocate.
What’s your favorite weekend ritual?
Not sure if it’s a ritual, and doesn’t always fall out on the weekend, but always fun when you hit that elusive “I see the bottom of the laundry basket” moment!
What food best matches your work style?
If my work style were a food, it would be a home-cooked meal prepared by a personal chef, thoughtfully tailored to individual needs, made with high-quality ingredients, and delivered with a personal touch.

What’s your “controversial” food opinion?
I will NEVER mix ketchup with cheese – now, I love pizza, and any combination of tomato sauce and cheese, but ketchup is VERY different from tomato sauce and has no business coming anywhere near cheese. I appreciate ketchup with other foods, mainly meats. NOT with cheese. I’ll also never mix ketchup with eggs, but I wouldn’t mix tomato sauce with eggs either. Actual tomatoes with eggs are just fine.
What’s a small thing that always makes your day better?
A kind word or gesture of appreciation always makes me feel good. And a greeting with a genuine smile.

If you could have dinner with any historical or fictional character, who would it be?
Ideally, I would love to sit down for a meal with my late grandparents, both of those I was fortunate enough to know and the grandfather I’m named after. It would be incredibly meaningful to interact with them as an adult.
What makes you laugh the hardest?
I’ve gotten to the sweet spot where my Instagram Reels algorithm has gotten to know me to a T, and if I’m scrolling in the evening hours, it will show me exactly what will have me crying tears of laughter – sometimes VR fails and funny memes of all kinds…
What are you currently learning about (either professionally or personally)?
I’m currently re-learning first-grade math and reading skills… It’s a trip!

Thank you, Gavi! It is clear that someone who has navigated six continents on her own can handle just about anything a client throws at her. More spotlights are on the way. And if you are mapping out your next adventure anywhere in the world, Antarctica excluded, Gavi is probably worth a conversation.
Five Blocks Launches AIQ: The First Platform That Shows PR Teams What AI Says About Their Brand – and Why
AIQ tracks narrative, source influence, and brand messaging across ChatGPT, Gemini, Claude, Perplexity, and four other major AI models – giving communications teams the intelligence layer that traditional SEO and GEO tools don’t provide
![]()
New York – Five Blocks today launched AIQ (https://aiq.fiveblocks.com), a self-serve SaaS platform that gives communications teams on-demand visibility into how AI answer engines represent their brands.
Starting at $99 per month, the platform lets PR professionals monitor and analyze how eight major AI models – ChatGPT, Copilot, Gemini, AI Overview, Perplexity, Grok, Claude, and Google AI Mode – represent their brands, executives, and narratives in real time.
Unlike traditional GEO platforms focused on rankings and visibility metrics, AIQ is built around a different question: what is AI actually saying about your brand, and where is that narrative coming from? The platform tracks narrative themes, identifies which sources each AI model trusts, and reveals how AI constructs its understanding of companies and executives across multiple models simultaneously.
AIQ currently tracks more than 5,000 topics across industries – from corporate brands and C-suite executives to product launches, crisis situations, and employer reputation – giving communications teams a window into the AI ecosystem that is rapidly becoming the primary way stakeholders find and form opinions about brands.
“Search engine optimization taught us to chase rankings. AI optimization requires something entirely different,” said Sam Michelson, CEO of Five Blocks. “You can’t game AI with keywords or backlinks. You need to understand which sources AI trusts, which narratives are forming, and how those stories evolve across different models. AIQ is the first platform built specifically for that challenge.”
Key Capabilities:
- Multi-Model AI Tracking: Every major AI model weights sources differently and surfaces different narratives. AIQ tracks eight simultaneously – ChatGPT, Copilot, Gemini, AI Overview, Perplexity, Grok, Claude, and Google AI Mode – so you always know which version of your brand story is winning, and where.
- Source Intelligence by Model: AIQ identifies exactly which sources – Wikipedia, Reddit, news outlets, PR distributions, industry sites – are shaping each AI model’s understanding of your brand. This is influence mapping for the AI era, not backlink counting.
- AI-Generated Theme Tracking: AIQ automatically identifies and categorizes the narrative themes appearing across AI responses, then tracks momentum over time – so you can see whether your messaging is breaking through, or whether a competing narrative is gaining ground.
“Communications teams are entering a new phase where AI answer engines aren’t just distributing information, they’re actively shaping how brands are interpreted,” said Amanda Coffee, CEO of Coffee Communications. “AIQ gives PR teams what they’ve desperately needed: visibility into how AI constructs narratives, which sources it trusts, and how those stories evolve in real time. This is how communicators prove strategic value to the C-suite while actually protecting the brand.”
Immediate Availability
AIQ is available now at https://aiq.fiveblocks.com. Subscriptions start at $99 per month, with plans designed for individual communications professionals, agencies, and enterprise teams. The platform is updated continuously as the AI landscape evolves, ensuring coverage reflects how the major models are changing.
About Five Blocks
Founded in 2003, Five Blocks is a digital reputation management firm with offices in New York and Jerusalem. A seven-time Inc. 5000 honoree, the company’s 70+ specialists partner with Fortune 500 CCOs, leading PR firms, and companies around the world to manage and shape how brands, organizations, and executives appear across Google Search, Wikipedia, and AI platforms. Five Blocks developed and built AIQ based on over a decade of real-world experience tracking, analyzing, and managing digital reputation across multiple digital platforms for hundreds of well-known brands.
Press Contact:
Renee Chemel
Five Blocks
reneec@fiveblocks.com
(212) 695-0855
Behind the Scenes at Five Blocks: Adam
Next up in our employee spotlight series: Adam, an Account Manager who’s been with Five Blocks since 2017. Whether he’s problem-solving for clients or pushing through a workout, Adam’s all about consistency and showing up.
Let’s get to know him.

How would you describe your job in a single sentence (or emoji)?
IMPACTful 🤪
What’s a valuable lesson you’ve learned from a work experience?
The value of a good reputation! There’s a reason that Five Blocks has been as successful as it is. It’s so important for our clients to keep their reputation high.

What’s a fun fact about yourself that most people wouldn’t know?
I kind of like to workout 🙂
Fitness started as a hobby of mine almost 10 years ago, and since has become a key part of my life. I truly believe that getting into fitness has helped make me a better person, both in and outside of the office.
A small thing that always makes your day better:
A good cup of coffee. And, not to sound like a broken record, but a good workout. Even if it has to happen at 6 am, I always feel better having had a good workout.

Favorite snack to keep at your desk?
Protein yogurt. Snack on them every day. Not only does it scratch the ‘snack’ itch, but it also is a good way to eat more protein (which is important to me).
What’s your spirit animal, and why?
Wolf. Quiet and strong. Always thought they were very cool.

One food you could eat every day and never get bored of?
My boring chicken salad. It’s pretty simple, but gets the job done. Some peppers, cucumbers, chicken breast and a dressing.
What unique skill or expertise do you bring to the table that benefits the team?
Fitness 💪
I joke that I am the CFO – Chief Fitness Officer. But outside of fitness, I am always happy to help with a task or anything that a colleague needs.
Beach vacation or mountain getaway?
Mountain for sure!

What made you first feel like an adult and why?
Probably when I had my first kid. Took a whole 30 years to finally feel like an adult. 😜
Adam, thank you for sharing your story with us — and for the reminder that the same discipline it takes to show up at the gym every day is probably what makes you so good at what you do. More spotlights are on the way, so check back soon.
Your Brand Doesn’t Exist Unless AI Says It Does

Your brand isn’t what you say it is anymore, it’s what the AI concludes it is.
For two decades, digital strategy was about “the click,” fighting for page one of Google so users would visit your website. But the ground has shifted. We’re no longer in an era of search; we’re in an era of synthesis.
When someone asks ChatGPT, Gemini, or Perplexity about your company, they’re not clicking through to your website. They’re getting an answer, synthesized from whatever data the AI can find. If your digital footprint is thin, incomplete, or outdated, the AI will fill the void with whatever it finds. Or worse, it will hallucinate.
In Hirsch Leatherwood’s latest podcast, Five Blocks CEO Sam Michelson breaks down what this shift means for your brand and how to prepare for 2026.
Key Insights from the Conversation:
The Death of the Click
Traffic is a disappearing metric. Users stay in the browser window with AI, they don’t need to visit your site anymore. The new KPI isn’t traffic; it’s presence. How accurately and frequently does AI represent your brand?
Your Website is a Training Manual
Traditional websites were brochures. Now they’re data sources for AI models. If you don’t provide rich, structured content, the AI will pull from less reliable sources or invent a narrative. Nature abhors a vacuum, and so does an LLM.
Wikipedia and Earned Media Matter More Than Ever
Despite the fragmentation of AI models, they all share common trusted sources. Wikipedia remains the ultimate pillar, if your entry is outdated, that error gets amplified everywhere. Earned media and third-party validation provide the “proof” AI needs to avoid hallucinations.
The brands that thrive in 2026 will be the ones that treat their digital footprint as an open data source, feeding the models that now define their reputation.
Behind the Scenes at Five Blocks: Donna
We’re continuing our series spotlighting the people behind Five Blocks—the team members whose work and expertise shape what we deliver to clients every day.
This time, we’re sitting down with Donna, a Senior Content Writer who has been with Five Blocks for 16 years. Donna works on our Wikipedia team, helping clients navigate one of the most visible—and carefully governed—platforms on the internet.
Before joining Five Blocks, Donna earned a BS in Microbiology from UC Berkeley and conducted cancer research at Memorial Sloan Kettering in New York City. When she started raising her family, she stepped away from formal work but remained active through volunteer work and various writing projects.
Let’s get to know Donna.

What are your favorite work tools?
Since I still remember working without these tools, I know how helpful and time-saving the following are:
- Who Wrote That – indicates which editor wrote specific text, when they wrote it, and what percentage of the article they contributed. (Highly recommended!)
- Wikipedia Editor Activity Tracker – tells you when an editor made his/her last edit.
- Wikipedia UserTags – shows you how many edits an editor has made in the past week.
- WikiAlerts by Five Blocks – alerts you when an edit has been made to your Wikipedia page.
- Google Calendar – let’s me track team schedules. (So, I know where everyone is at all times. Maybe not so useful, but super fun!)
Which part of your job makes you feel like a superhero?
Making sure all the batteries are charged. Although I don’t do that anymore, sadly. The next best thing is when our clients make a direct edit with no mistakes and no pushback.

What is your favorite weekend ritual?
Going to visit my children and grandchildren on Fridays. Oh, and sleeping in!
What hobby or activity could you spend hours doing without realizing it?
Watching good movies.
If you could instantly master a new skill, what would it be?
Playing piano.

Pancakes or waffles? And what’s your favorite topping?
I don’t eat either, but I like chocolate sprinkles on ice cream and croutons in chicken soup.

What’s the weirdest or most random thing on your desk right now?
I have two lava lamps. Isn’t that cool?
What is your favorite snack:
Brownies, ice cream, chocolate chip cookies, dark chocolate, 1.7% plain yogurt.
Favorite quote:
I have 3…
1. If you lived here, you’d be home by now.
2. Rumors of my death have been greatly exaggerated.
3. Better to be quiet and let people think you are stupid than to open your mouth and prove it.
Thanks, Donna, for letting us get to know you and for the craft and care you bring to every piece of content. We’re continuing this series with more voices from the Five Blocks team—check back soon for the next spotlight!
Behind the Scenes at Five Blocks: Nahum
We’re launching a new blog series to spotlight the people who make Five Blocks what it is—the team working behind the scenes every day to support our clients. It’s a chance to get to know the individuals who bring thoughtfulness, expertise, and energy to everything we do, even when their contributions aren’t always visible.
We’re starting the series with Nahum, a Senior Account Manager who has been with Five Blocks for four years. Beyond leading client work, Nahum is also part of our culture committee, helping shape how we celebrate holidays, connect as a team, and create the moments that make Five Blocks a great place to work.
With no further ado, let’s get to know Nahum.

How would you describe your job with emojis?
👀 Monitor ☕ Coffee 🔍 Research 🤝 Manage 🚨 Crisis 🍵 Coffee 😎 Calm 💻 Reputation 🔁 Repeat
What’s the funniest or weirdest thing that’s happened to you at work?
I was on a call with an important client and the WiFi crashed, got back on the call and it crashed again. Ended up going outside, setting up a hotspot from my cell and doing the rest of the call outside on the hood of my car.
What hobby or activity could you spend hours doing without realizing it?
Playing the drums and jamming with my band Red & the Baldies.

If you could live anywhere for a year, where would it be?
A beach in Hawaii, in the shade, with several layers of sunscreen.

What’s a hidden talent you have that not many people know about?
I do voice-over work as a (very) side gig and can (and do) drum on everything within reach.
Mac and cheese or tuna noodle casserole – or a completely different comfort food?
I’d rather go with low and slow smoked beef brisket, short ribs, top-sirloin cap picanha, and duck breast in a honey-mustard sauce. If I can’t have that, just give me a chocolate milk in a bag.
Sweet, salty, or spicy — which snack can you not resist?
Sweet! Donuts or fresh pastries are impossible for me to resist.

What’s your go-to karaoke song (even if you’d never sing it in public)?
100% “Mustang Sally.” I’ll sing it anywhere.
What’s your “guilty pleasure” show, movie, or podcast?
Show, movie or book connected with Harlan Coban.
What’s the weirdest or most random thing on your desk right now?
Pink spoons from Baskin-Robbins.

Favorite quote:
From the one and only Robin Williams: “Everyone you meet is fighting a battle you know nothing about. Be kind. Always.”
Thanks, Nahum, for letting us get to know you and for all the energy and dedication you bring to Five Blocks. This is just the start of our series highlighting the amazing people behind the work we do—stay tuned for the next employee spotlight!
Beyond Deletion: What ChatGPT’s Use of Hidden Wikipedia Pages Reveals About AI Reputation

For years, Google has been the ultimate arbiter of online visibility. If a page didn’t appear in Google’s index, it effectively didn’t exist in the public eye. Brands, communicators, and reputation managers learned to play by Google’s rules — optimizing what could be found, fixing what was misleading, and deleting what was outdated.
But artificial intelligence is rewriting those rules in real time.
Recently, we made a surprising discovery that raises new questions about how AI systems like ChatGPT access and represent information — and what that means for brands. ChatGPT cited Wikipedia pages that not only weren’t indexed by Google but, in some cases, had been deleted from Wikipedia entirely months earlier.
In other words: ChatGPT appears to be referencing information that no longer exists on the open web.
This finding, while seemingly small, points to a much larger shift. It suggests that ChatGPT operates from a different kind of index — one not governed by Google or Bing, but by the model’s own memory and training data. And that has profound implications for online reputation.
1. The Discovery
At Five Blocks, we regularly analyze how information about companies and individuals appears across platforms — from search results to knowledge panels to AI-generated summaries.
During one of these analyses, we noticed something odd: ChatGPT was citing a Wikipedia page about a company that had been deleted from Wikipedia months earlier. Even more surprising, the page had never been indexed by Google — likely due to Wikipedia’s internal restrictions on certain pages and drafts.
In short, ChatGPT seemed to know something that should have been impossible for it to know.
When we tested further, we found similar examples. In some cases, ChatGPT referenced archived or draft Wikipedia pages that were not accessible through normal search.
This means ChatGPT’s knowledge base includes content that is invisible to both users and search engines — a sort of ghost archive of the internet.
The image below from our AIQ platform shows an example of ChatGPT referencing a deleted Wikipedia page:
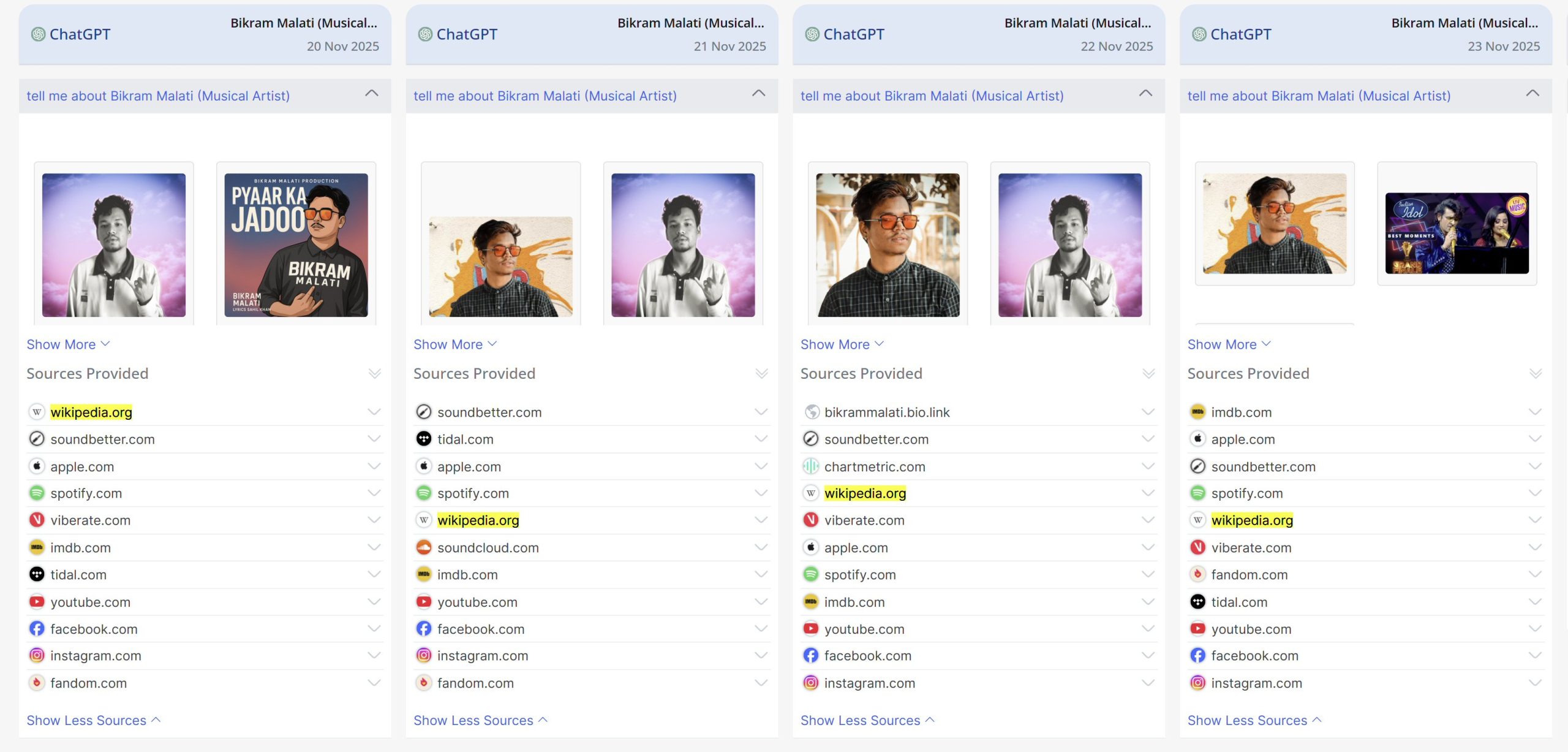
Here is an actual ChatGPT screenshot:
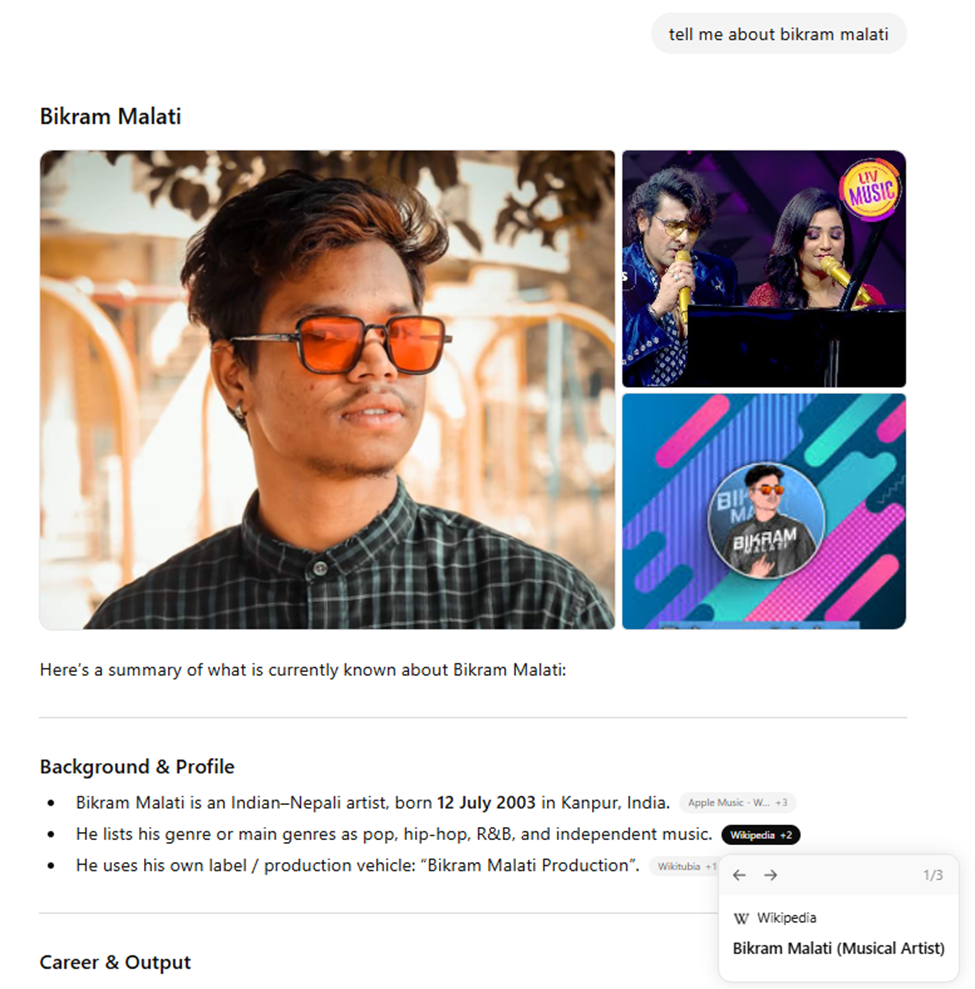
When you click on the link from ChatGPT, you get:
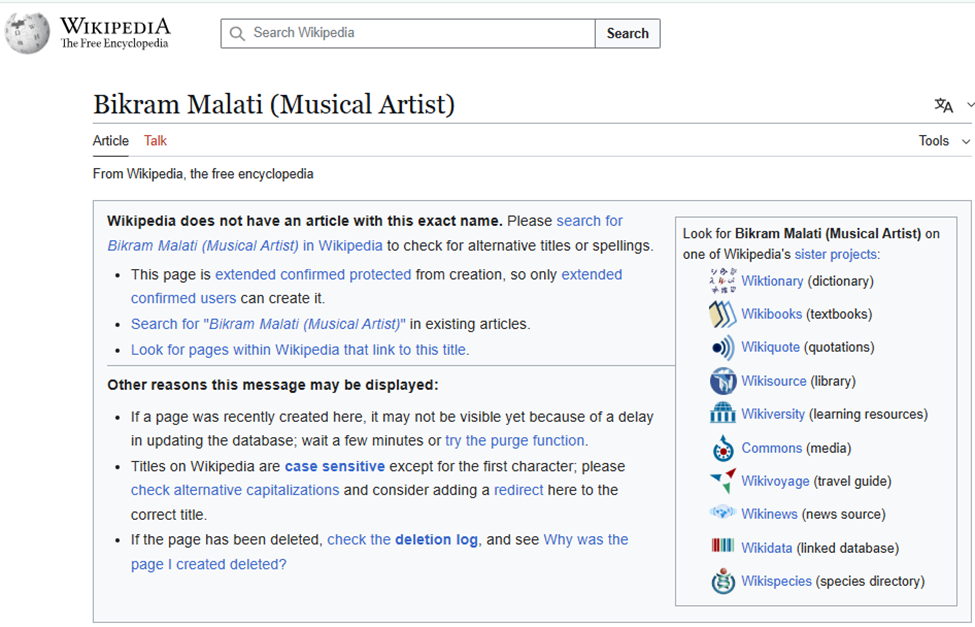
And, here you can see that the Wikipedia article was deleted on May 19th:
![]()
2. The Indexing Debate: Google, Bing… or Something Else?
There’s been a lot of discussion online about whether ChatGPT (and similar tools) rely on Google’s or Bing’s index to answer questions about current topics.
Microsoft has described Bing as ChatGPT’s “search partner,” suggesting that when the model browses the web in real time, it’s doing so through Bing’s infrastructure. Others assume that since Google dominates the indexing landscape, much of the information must come from its dataset.
Our finding suggests a third possibility.
AI systems like ChatGPT don’t just rely on live search indices — they also draw on their own internal knowledge, built from snapshots of the web taken during training. That means they may reference pages that have since disappeared, been updated, or were never fully visible to search engines at all.
For example, here ChatGPT cites the HMS Totnes Wikipedia page:
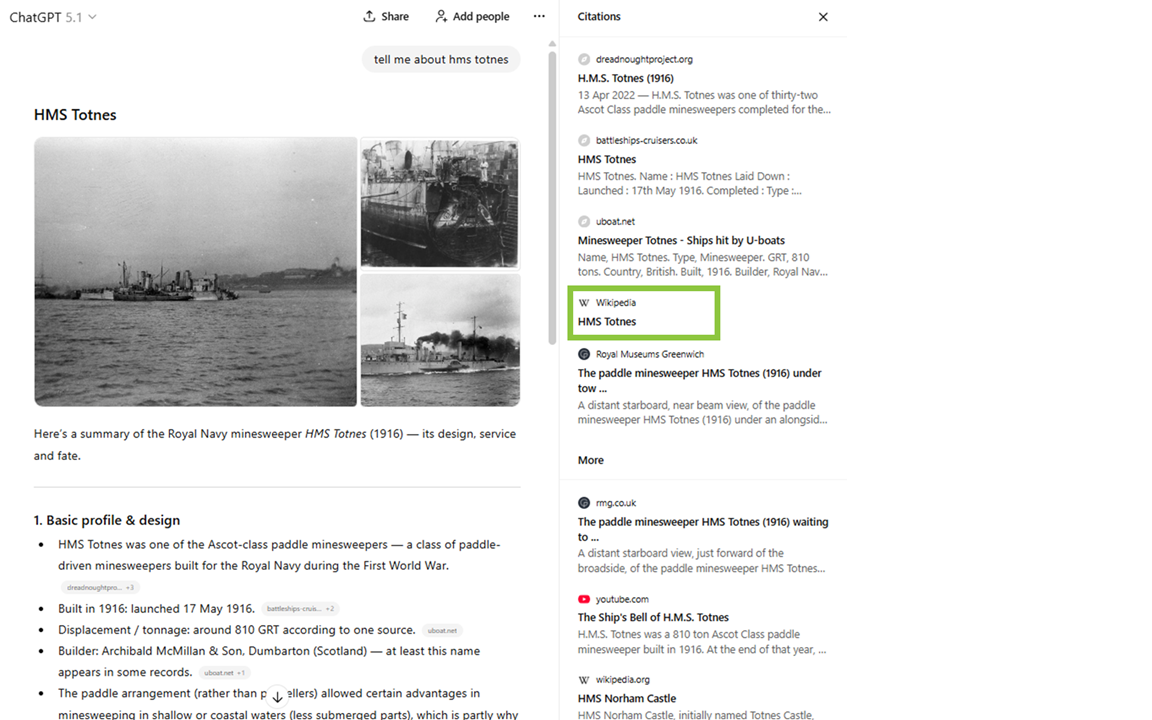
However, a Google search for that Wikipedia page shows that it hasn’t been indexed:
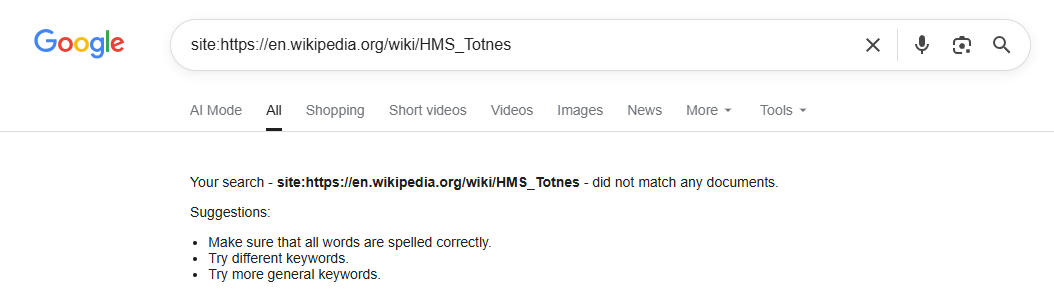
Unlike Google or Bing, which are constantly re-indexing the live web, AI models often retain information indefinitely. They may “remember” content that was once public but has long since vanished — effectively creating a parallel version of the internet that exists only inside the model.
This raises a fascinating question:
If AI can access and resurface information that’s been deleted or de-indexed, what does “control” over your online reputation really mean?
3. The Reputation Implications
For years, Wikipedia has been one of the most powerful determinants of how brands and individuals appear online. It influences Google Knowledge Panels, affects trust signals, and often shapes media narratives.
Because of that, many organizations have worked diligently to ensure that their Wikipedia entries are accurate, balanced, and aligned with verifiable facts. But the assumption has always been: once an error is corrected or a page is deleted, the outdated version fades from public view. In the age of AI, that’s no longer guaranteed.
If ChatGPT or another AI system has already learned from a previous version of a Wikipedia page, that information may continue to influence its responses — even if the page no longer exists. This creates a temporal lag between what’s true now and what AI believes to be true, based on past data.
That lag can have real consequences:
- A company that successfully removes an inaccurate Wikipedia claim may still see it resurface in AI summaries.
- An individual whose biography was corrected might find outdated information repeated in generative search results.
- A brand that relies on Wikipedia for credibility could see outdated or partial content influencing how AI describes it to users.
This represents a profound shift in the mechanics of reputation. Reputation is no longer defined solely by what’s visible online — it’s also shaped by what AI remembers.
This raises an important question: if outdated Wikipedia content can continue to surface in AI responses, is there still value in correcting or deleting a page? The answer is yes — but with new strategic considerations. When an updated version of a page is published, AI systems that re-crawl or refresh their training data are more likely to replace older information with the corrected version. And even if outdated details aren’t fully overwritten everywhere, ensuring that accurate, high-quality content exists increases the probability that AI models will surface the correct version in most contexts. In other words, maintaining an accurate Wikipedia presence still matters — it just operates within a more complex, probabilistic AI ecosystem.
4. Managing Reputation in the Age of AI Memory
So, what should brands and communicators do in this new landscape?
First, recognize that deletion isn’t disappearance.
Once information has entered the public digital ecosystem — especially on high-visibility platforms like Wikipedia — it may continue to circulate in AI models long after being removed. That makes proactive accuracy and clarity even more important. Fixing misinformation quickly reduces the risk that it becomes “baked in” to an AI’s memory.
Second, expand your visibility monitoring beyond search.
Traditional SEO and reputation tools focus on what appears in Google results. But as AI platforms like ChatGPT, Perplexity, and Google’s own AI Overviews become more popular, brands need to track how they’re represented there, too. Five Blocks’ AIQ Snapshot, for example, measures how companies appear across leading AI platforms — providing early warning when narratives diverge from reality.
Third, view Wikipedia through an AI lens.
Wikipedia remains one of the most influential data sources in the world — not just for humans, but for machines. Maintaining accuracy, neutrality, and completeness there matters more than ever, because what’s written (or once written) can echo through AI systems long after.
Finally, stay vigilant about every change that happens on your Wikipedia pages.
Even small edits — a phrasing shift, a new citation, an added controversy — can ripple into AI systems that use Wikipedia as a core reference. That makes real-time monitoring essential. Tools like Five Blocks’ WikiAlerts™ notify brands the moment a page is edited, enabling rapid review and response before inaccurate or biased information spreads or becomes part of an AI model’s reference set. In the age of AI memory, staying updated isn’t just good Wikipedia hygiene — it’s a critical layer of reputation protection.
5. The Takeaway: Reputation in a Post-Search World
The discovery that ChatGPT can cite deleted or unindexed Wikipedia pages is more than a technical curiosity. It’s a signal that we’re entering a post-search era — one where visibility and influence extend beyond the reach of traditional SEO and content control.
Search engines like Google and Bing show us what’s out there today. AI models, in contrast, reveal what’s still in there — the accumulated memory of the internet, with all its imperfections, edits, and ghosts of pages past.
For communicators and reputation professionals, this is both a challenge and an opportunity. It’s a reminder that reputation isn’t static, and it isn’t limited to what’s live. It’s a living narrative, shaped by both current content and the digital traces left behind.
At Five Blocks, we believe the next chapter of reputation management lies in understanding and influencing that AI layer — ensuring that when machines summarize who you are, they get the story right.
Curious whether ChatGPT is pulling from non-indexed or deleted pages that could be influencing your brand narrative? Get an AIQ Snapshot now!