Digital Reputation Management
Reputation is no longer a media problem. It’s an infrastructure problem.
What Google and AI say about your brand is your reputation. We manage it.

For most of the last two decades, “reputation” lived inside the communications function. A CCO managed the narrative through earned media, owned channels, and relationships with reporters. The story was the product.
That world still exists. But it now runs on top of a second, deeper layer – one that determines whether the story actually reaches anyone.
When a board member, a regulator, an LP, a journalist, a recruit, or a customer wants to understand a company or an executive, they do not start with a press release.
They typically start with Google, and increasingly, they are moving to ChatGPT, Gemini, Claude, Perplexity, or Copilot. What those systems return – the ten blue links, the knowledge panel, the AI-generated summary – is the reputation. Everything else is upstream of it.
Most PR firms are not built to manage that layer. We are. It is the only thing we do, and we have been doing it since 2003.
What “Digital Reputation Management” actually means at Five Blocks
The phrase gets used loosely. In our work, it has a precise meaning: the disciplined, ongoing management of every signal that Google and AI models use to construct a picture of a brand or an individual.
That includes, at minimum:
- Google search results for branded and reputational queries – the first three pages, every SERP feature (knowledge panel, People Also Ask, Top Stories, AI Overviews, sitelinks), and how they shift over time.
- AI-generated narratives in ChatGPT, Gemini, Claude, Perplexity, Copilot, Grok, and Google’s AI Mode – what the model says, which sources it draws from, and how the story compares to peers.
- Wikipedia – the single most influential third-party source on the open web, cited heavily by AI models and surfaced prominently in Google.
- Knowledge graphs and entity signals – Wikidata, Crunchbase, schema markup, structured data, and the dozens of signals that tell machines who a company or person is.
- Owned content – corporate sites, executive bios, FAQ pages, leadership content – structured to be readable by both humans and AI.
- Earned and third-party content – the press, directories, and reference sites that AI treats as authoritative.
Each of these is a discipline. Most firms work in one or two of them. We work in all of them, in-house, and we treat them as a single connected system – because that is how Google and AI treat them.
Why this is different from PR, SEO, or traditional ORM
We get asked this constantly, so it is worth being direct.
We are not a PR firm. We do not pitch reporters, place stories, or manage media relationships. We work alongside the firms that do – including most of the major strategic communications and IR firms in New York, London, and globally. They handle narrative and media. We handle the technical and content infrastructure that determines whether that narrative actually reaches people through Google and AI.
We are not an SEO agency. Traditional SEO optimizes for traffic and conversion – keywords, backlinks, technical performance. Reputation work optimizes for what specific people see when they search a specific name or brand. Different goals, different toolkit, different success metric.
We are not a traditional ORM or “suppression” firm. Most firms in that category fight the algorithm – they build networks of low-quality content, spin up profiles, and try to push negative results down through volume. The work is brittle, often unethical, and increasingly ineffective as Google and AI get better at recognizing manipulation.
We do the opposite. We work with the platforms – studying how Google ranks, how AI models source their answers, what Wikipedia accepts as credible – and we curate a client’s broader digital presence so that the preferred narrative is the one those systems naturally elevate. The work is durable because it is built on the same logic the platforms themselves use.
Our approach
Every engagement starts with the same conviction: you cannot manage what you have not measured, and you cannot fix what you do not understand.
1. We lead with data
Before we recommend anything, we audit. Across Google search results for every reputational query that matters, across all major AI models, across Wikipedia and Wikidata, across knowledge panels and structured data, across third-party citations. We map the full landscape – what is there, where it is coming from, and why the systems are surfacing it.
This produces two things our clients consistently tell us they cannot get elsewhere: a clear, evidence-based picture of the actual problem, and an internal alignment tool that gets stakeholders to agree on what to do.
Our proprietary platforms make this possible at depth:
- IMPACT™ tracks Google search results daily across tens of thousands of queries for every client. We have monitored more than 100,000 brand search footprints over the platform’s history. Clients see, in real time, which results dominate, how rankings shift, and where the leverage points are.
- AIQ is the only platform of its kind built specifically to monitor AI narratives. It tracks how ChatGPT, Gemini, Claude, Copilot, Perplexity, and Grok describe a brand – sentiment, sources cited, peer comparisons, narrative drift over time. Continuously updated.
- WikiAlerts monitors every relevant Wikipedia page and edit, in real time, across all language editions.
- GeoSearch tracks how results shift across geographies – critical for multinationals and for executives whose stakeholders are spread across markets.
2. We work every layer that matters, in-house
Five Blocks does not outsource. Every piece of work, Wikipedia research and editing, technical structured data implementation, AI content strategy, owned content development, entity optimization, is executed by our own team, in our offices in New York and Jerusalem.
Our staff averages well over a decade of experience in digital reputation. We have 10+ people dedicated exclusively to Wikipedia, with a depth of platform knowledge that is not matched anywhere in the industry. Our turnover is low. The senior practitioner assigned to a client in month one is the same one accountable in month twelve.
This matters because reputation work, done correctly, is highly contextual. There is no playbook that substitutes for someone who knows the case, the industry, the personalities, and the platforms intimately. We build that institutional knowledge inside the engagement, and we keep it there.
3. We use peer analysis as a methodology, not a sales pitch
One of our operating principles: do not reinvent the wheel. In every engagement, we study what is working for a client’s peers and competitors – which content AI models are citing, which Wikipedia structures are most defensible, which third-party sources are driving positive narratives, which owned content is breaking through.
Our AIQ platform makes this systematic. We can tell a client, with data, which sources are shaping how they are described in ChatGPT versus how a peer is described – and what to do about the gap. It accelerates results and grounds every recommendation in what is actually working in that competitive context.
4. We build for durability, not for the dashboard
There is a temptation in this industry to optimize for what looks good in a monthly report. We optimize for what holds up six, twelve, twenty-four months out – through algorithm changes, news cycles, and the rapid evolution of AI models.
That means investing in the structural assets that compound: a strong Wikipedia presence, well-architected owned content, accurate entity data, durable third-party citations. The work is slower than vanity tactics. It is also why our client relationships average many years.
What ongoing digital reputation management looks like
Most of our engagements are not crisis work. They are ongoing programs designed to keep a brand or an executive in a strong position – so that when something does happen, the foundation is already there.
A typical program includes:
Continuous monitoring. IMPACT™ and AIQ run daily. Clients have real-time visibility into where they stand in Google and across AI models. Anomalies, ranking shifts, narrative drift, new negative content – we see it as it happens, often before the client does.
Active curation of search results. We work the queries that matter, branded searches, executive names, reputational queries, industry-specific terms – and we manage what surfaces on them. That means strengthening preferred content, building new assets where gaps exist, and addressing problematic results through the structural levers that actually move rankings.
Wikipedia stewardship. For clients with Wikipedia presence (or who should have one), we manage notability, accuracy, sourcing, and the ongoing editorial process – transparently, with disclosed conflict-of-interest editing per Wikipedia’s terms of service. For clients without a Wikipedia page, we assess whether one is appropriate and, if so, build it correctly the first time.
AI narrative management. We monitor how each major AI model describes the client, identify the sources driving the narrative, and shape those sources – corporate site content, Wikipedia, earned media, structured data – so that the AI-generated story is accurate, complete, and favorable. This is the newest discipline in reputation, and the one most firms have not figured out.
Entity optimization. Wikidata entries, Google Knowledge Graph signals, schema markup on the corporate site, executive entity hygiene across the open web. The unglamorous infrastructure that determines whether AI and search engines correctly understand who the client is.
Owned content development and optimization. We help clients build the kind of content, executive bios, leadership pages, FAQ structures, thought leadership architecture, that performs in both human search and AI synthesis. Often this is the highest-leverage work we do.
Reporting and review. Formal monthly reports, weekly check-ins where appropriate, ad-hoc updates as activity warrants, and continuous platform access through IMPACT™ and AIQ. Clients are never guessing where they stand.
How we work with PR and communications partners
The majority of our engagements involve a PR or strategic communications firm working alongside us. That is by design. PR teams shape narrative; we shape the infrastructure that determines whether the narrative is what people actually find.
In practice this looks like:
- Joint stakeholder mapping. Comms identifies the audiences and moments that matter; we identify the queries, platforms, and signals that audience will actually encounter.
- Coordinated content strategy. When the comms team places earned media, we ensure the placements are structured to be discoverable and citable by AI. When we recommend owned content, the comms team owns voice and message; we own architecture and discoverability.
- Crisis preparation, not just response. We map vulnerabilities before they become incidents, exposed search queries, weak entity data, Wikipedia risk, AI narrative gaps – and the PR partner builds the messaging playbook against that map.
- Clear lines. No turf wars. We do not pitch reporters; PR partners do not edit Wikipedia. The collaboration works because the disciplines do not overlap.
Why this matters now
Two things have changed in the last twenty-four months.
First, AI-generated answers are rapidly replacing the search query as the primary way people get information about brands and individuals. The narrative those models produce is built from a specific set of sources – Wikipedia, corporate websites, earned media, structured data – and it is being formed right now, whether the subject is paying attention or not.
Second, the cost of getting it wrong has gone up. A flawed AI summary that gets cited by a journalist, repeated by an analyst, or surfaced to a board member becomes the working version of the story. Correcting it after the fact is far harder than shaping it correctly in the first place.
Five Blocks has spent twenty-plus years working on exactly the building blocks AI models now read. We were doing this work before AI made it urgent. The firms that figure out the AI layer will be the firms that already understood the search and Wikipedia layers – because they are the same problem, in a new wrapper.
Frequently Asked Questions
How is Five Blocks different from a traditional ORM or “suppression” firm? Traditional ORM fights the algorithm – building low-quality content networks to push results down. We work with the platforms. We study how Google and AI models source and prioritize content, and we curate a client’s broader digital presence so the preferred narrative is the one those systems naturally surface. The work is durable because it is built on the same logic the platforms use.
How is Five Blocks different from a PR firm doing digital reputation? PR firms manage narrative and media relationships. We manage the technical and content infrastructure that determines what Google and AI actually return. Different skills, different tools, different success metric. Most major PR firms partner with us rather than compete with us.
Do you outsource any work? No. All Five Blocks work is done in-house, by our team. No white-label vendors, no offshore execution.
How long do engagements typically last? Most clients work with us on an ongoing basis. Reputation infrastructure is not a one-time project – search results shift, AI models evolve, news cycles change, executives transition. Programs are designed to maintain and strengthen the foundation over time. Crisis-only engagements are usually two to six months; broader programs run for years.
Can Five Blocks actually change what AI models say about a client? Yes – through structural means. We improve the sources AI models read: Wikipedia, corporate website content, earned media, entity signals. When those sources improve, the AI-generated narrative improves. Our AIQ platform measures the change directly. This is not a workaround; it is how AI reputation management works.
Does Five Blocks remove negative content? Where it is possible and appropriate, yes – through direct outreach, factual correction requests, legal angles where they exist, and in some cases acquiring defunct sites that host defamatory content. Removal is not always feasible, which is why our broader methodology focuses on shaping what surfaces in Google and AI regardless of whether any individual piece comes down.
How do you report to clients? Formal monthly reports, weekly check-ins where the engagement warrants, ad-hoc updates as activity requires, and continuous real-time access to IMPACT™ (search) and AIQ (AI). Clients are never guessing where they stand.
Do you work confidentially through PR partners? Yes. Many of our engagements run through strategic communications and PR firms. We also work directly with end-clients. Either model is standard.
How much does an engagement cost? Programs are structured as monthly retainers, scoped to the work required. Crisis engagements typically run $15,000 to $30,000 per month. Ongoing programs vary based on scale – a single executive looks different from a multi-brand corporate mandate. We will scope and price transparently after an initial audit.
Do you work outside the United States? Yes. We work across many languages and geographies.
Is the work confidential? Always. No exceptions.
Where to start
The right entry point for almost every prospective client is the same: a Digital Brand Audit. It is fast, it is concrete, and it produces a clear, evidence-based picture of where the client stands across Google, AI models, Wikipedia, and entity signals – along with a prioritized roadmap for what to do about it.
For active situations, we begin a crisis engagement within 24 to 48 hours.
For ongoing programs, we typically scope, audit, and launch within two to three weeks of engagement.
Contact us to discuss your situation – whether you are evaluating partners, building defenses before a crisis, or already in one.
Your Brand Doesn’t Exist Unless AI Says It Does

Your brand isn’t what you say it is anymore, it’s what the AI concludes it is.
For two decades, digital strategy was about “the click,” fighting for page one of Google so users would visit your website. But the ground has shifted. We’re no longer in an era of search; we’re in an era of synthesis.
When someone asks ChatGPT, Gemini, or Perplexity about your company, they’re not clicking through to your website. They’re getting an answer, synthesized from whatever data the AI can find. If your digital footprint is thin, incomplete, or outdated, the AI will fill the void with whatever it finds. Or worse, it will hallucinate.
In Hirsch Leatherwood’s latest podcast, Five Blocks CEO Sam Michelson breaks down what this shift means for your brand and how to prepare for 2026.
Key Insights from the Conversation:
The Death of the Click
Traffic is a disappearing metric. Users stay in the browser window with AI, they don’t need to visit your site anymore. The new KPI isn’t traffic; it’s presence. How accurately and frequently does AI represent your brand?
Your Website is a Training Manual
Traditional websites were brochures. Now they’re data sources for AI models. If you don’t provide rich, structured content, the AI will pull from less reliable sources or invent a narrative. Nature abhors a vacuum, and so does an LLM.
Wikipedia and Earned Media Matter More Than Ever
Despite the fragmentation of AI models, they all share common trusted sources. Wikipedia remains the ultimate pillar, if your entry is outdated, that error gets amplified everywhere. Earned media and third-party validation provide the “proof” AI needs to avoid hallucinations.
The brands that thrive in 2026 will be the ones that treat their digital footprint as an open data source, feeding the models that now define their reputation.
The Speed Tax: Your Slow Corporate Site Is Hurting You in AI Search

Sometime milliseconds matter more than money — how Time to First Byte is quietly reshaping brand visibility in the AI era…
For years, the playbook was simple: optimize for Google, rank on page one, and let the traffic roll in. But as millions of consumers now get their answers from ChatGPT, Perplexity, and Google’s AI Overviews instead of scrolling through search results, a new technical reality is emerging, and it’s catching many of the world’s largest companies off guard.
If your corporate website is too slow, AI systems may never see your content at all.
The culprit? A metric most communications professionals have never heard of: Time to First Byte.
What Is TTFB, and Why Should You Care?
Time to First Byte (TTFB) measures how quickly a server begins responding after receiving a request. When someone, or something, asks your website for information, TTFB captures the milliseconds between the request and the very first byte of data being sent back.
For human visitors, a slow TTFB means frustrating load times. For AI crawlers, it means something far more consequential: your content may simply be skipped.
Here’s the technical reality that’s reshaping digital reputation: AI systems operate under strict latency budgets. When ChatGPT or Perplexity need to fetch real-time information to answer a query, they can’t wait around. If your server takes too long to respond, the crawler moves on. Your carefully crafted content, your company’s narrative, your leadership’s bios, your crisis messaging, never enters the AI’s knowledge base.
Google recommends a TTFB of 200 milliseconds or less. Industry benchmarks suggest anything above 500ms is problematic. Yet our analysis of Fortune 500 corporate websites reveals that many fall well above these thresholds, with some enterprise sites clocking in at 1.5 to 2 seconds before delivering their first byte of data.
The AI Crawl Budget Problem
Think of it like a library with limited reading time. Traditional search engines like Google have decades of infrastructure investment and can afford to be patient, they’ll come back, render JavaScript, and eventually index your content. AI crawlers don’t have that luxury.
When OpenAI’s GPTBot or Anthropic’s ClaudeBot visits your site, they’re operating on what’s essentially a “processing budget.” These systems need to ingest, understand, and vectorize millions of pages. If your site is slow to respond, has massive file sizes, or requires extensive JavaScript rendering, the crawler may timeout or only partially index your content.
Recent research tracking over 500 million GPTBot requests found that sites with response times under 200 milliseconds receive significantly more complete indexing than slower competitors. The data is clear: faster servers help with freshness, retrieval quality, and the likelihood of your content appearing in AI-generated answers.
The JavaScript Blind Spot
Speed isn’t the only factor working against enterprise websites. There’s another technical hurdle that’s even more problematic: most AI crawlers cannot execute JavaScript.
Unlike Google’s crawler, which uses a sophisticated rendering engine that can process JavaScript-heavy pages, AI crawlers from OpenAI, Anthropic, and Perplexity essentially operate like it’s 2010. They fetch raw HTML and move on. They don’t wait for your scripts to load, don’t execute your React components, and don’t see anything that’s dynamically injected after the initial page load.
This creates a troubling scenario for modern corporate websites. Many enterprise sites rely on JavaScript frameworks to deliver content, product information, executive bios, news releases, even basic navigation. To a human visitor with a browser, the site looks beautiful and fully functional. To GPTBot, it’s a blank page with a header and footer.
An analysis by Vercel and MERJ found zero evidence of JavaScript execution by GPTBot across half a billion requests. The same limitation applies to ClaudeBot, PerplexityBot, and most other AI crawlers. If your content requires JavaScript to display, AI systems simply cannot see it.
A Real-World Example: The Invisible Product Launch
Consider this scenario: A major consumer brand launches a new product line. They invest heavily in a sleek, modern microsite with interactive features, animated product showcases, and JavaScript-powered content sections. The site looks stunning. Traditional SEO is optimized. Press coverage links back appropriately.
Three months later, when consumers ask ChatGPT “What’s new from [Brand]?” or Perplexity “Tell me about [Brand’s] latest products,” the AI responses reference old information, or worse, a competitor’s offerings. The microsite, despite its beauty and its Google rankings, never made it into the AI’s knowledge base.
The brand’s communications team is baffled. The problem? The microsite’s TTFB averaged 1.2 seconds, and the product descriptions were rendered entirely via JavaScript. From the AI crawler’s perspective, the launch might as well never have happened.
What This Means for Reputation Management
At Five Blocks, we’ve spent years helping brands understand how digital platforms shape their narratives. The rise of AI-powered search represents the most significant shift in information discovery since Google’s emergence, and it brings new technical requirements that go beyond traditional SEO.
The implications for reputation are substantial:
- Controlled narratives may not reach AI audiences. If your carefully managed corporate website is slow or JavaScript-dependent, the definitive information about your company may never enter AI training data or real-time retrieval systems.
- Faster competitors get cited first. When AI systems need to answer questions about your industry, they’ll pull from sources that are accessible. If your competitor’s content loads in 150ms with clean HTML while yours struggles at 800ms behind JavaScript rendering, their narrative shapes the AI response.
- Crisis content timing becomes critical. During a reputational crisis, every hour matters. If your response statement lives on a slow, JavaScript-heavy newsroom page, it may take significantly longer to propagate into AI systems, if it propagates at all.
- Wikipedia and third-party sources gain outsized influence. When AI crawlers struggle to access primary corporate sources, they lean more heavily on Wikipedia, news coverage, and other third-party content. You lose control of your own story.
The Technical Fixes That Matter
Addressing these challenges requires coordination between communications teams and IT infrastructure. Here’s what actually moves the needle:
Optimize Server Response Times. Target a TTFB under 200ms. This may require CDN implementation, server-side caching, and infrastructure upgrades. Many enterprise WordPress sites, in particular, struggle with response times that can be dramatically improved through proper configuration.
Implement Server-Side Rendering. If your site uses JavaScript frameworks like React, Vue, or Angular, implement server-side rendering (SSR) to ensure that critical content is present in the initial HTML response. This lets AI crawlers see your content without waiting for JavaScript execution.
Audit What Crawlers Actually See. Disable JavaScript in your browser and visit your key pages. What remains is what AI crawlers see. If executive bios, product information, or corporate messaging disappear, you have a problem that needs immediate attention.
Prioritize Critical Content in HTML. Ensure that your most important reputation-relevant content, leadership information, company overview, key messaging, exists in static HTML rather than being loaded dynamically.
Monitor AI Crawler Access. Review server logs for GPTBot, ClaudeBot, and PerplexityBot activity. Are they successfully accessing your key pages? Are requests timing out? This data reveals whether AI systems can actually reach your content.
The Bigger Picture: Infrastructure as Reputation Strategy
For communications professionals accustomed to thinking about narratives, messaging, and media relationships, the idea that server response times affect reputation may feel foreign. But in the AI era, technical infrastructure is communications infrastructure.
The question isn’t just “What story are we telling?” but “Can AI systems even hear us?”
As AI-powered search continues to grow, and all indicators suggest it will only accelerate, brands that invest in technical accessibility will have a structural advantage. Their content will be more consistently indexed, more frequently cited, and more accurately represented in the AI-generated answers that increasingly shape public perception.
Those that don’t will find themselves shouting into a void, their carefully crafted messages trapped behind slow servers and invisible JavaScript, while faster, more accessible sources define their narrative instead.
Curious whether AI systems can access your corporate content? Five Blocks’ AIQ platform tracks how your brand appears across ChatGPT, Perplexity, Google AI, and other AI-powered platforms, including whether your key pages are being successfully indexed. Contact us for an assessment.
Grokipedia Isn’t Just an AI Wikipedia

Introduction: The Next Chapter in Online Knowledge
In September 2025, Elon Musk’s company xAI announced the upcoming launch of Grokipedia, a fully AI-powered alternative to Wikipedia. Positioned as a solution to the editorial biases Musk perceives in the long-standing online encyclopedia, Grokipedia promises a new model for knowledge aggregation, driven entirely by artificial intelligence.
The immediate assumption is that this is a simple platform war: out with the old, volunteer-driven model and in with a new, algorithmically-curated system. However, this shift from a human-moderated commons to a corporate-controlled algorithm is not a simple competitive maneuver; it is a fundamental rewiring of how online truth is established and challenged, with profound implications for digital reputation.
The relationship between these two platforms is not one of simple opposition. In fact, Grokipedia’s core design creates a series of counter-intuitive dependencies and strategic necessities that every brand and public figure must understand. This article unpacks the four most counter-intuitive takeaways for your digital reputation.
Takeaway 1: Grokipedia’s Biggest Secret? It Needs Wikipedia to Survive.
Far from ignoring its predecessor, Grokipedia will use public information from sources like news and books, with Wikipedia serving as a primary foundational dataset. The process is designed for AI-driven refinement, not outright replacement. Grok will systematically scan existing Wikipedia articles, evaluate their claims as true, partially true, false, or missing, and then use its AI to rewrite them, aiming to fix falsehoods and add omitted context.
This dependency creates a surprising strategic imperative: maintaining a robust and accurate Wikipedia presence is now more important, not less. Because Grokipedia will use Wikipedia as its starting point, a well-sourced, comprehensive, and neutral article on the original platform serves as the first line of defense against unwanted algorithmic changes.
The more robust a Wikipedia page is, the less likely it is to be changed by Grokipedia.
The irony is clear. To effectively manage your presence on the new AI-powered encyclopedia, you must first double down on your commitment to the old, human-edited one. The best defense against unwanted AI edits in this new era is to ensure the source material it relies on is as accurate and complete as possible.
Takeaway 2: You Can’t Directly Edit Grokipedia—And That Changes Everything.
Grokipedia’s most fundamental departure from Wikipedia is the elimination of direct human editing. The familiar tactics of logging in to correct an error or engaging in “talk page negotiations” with other editors will be impossible. This represents a monumental shift for reputation management.
Instead, the new mechanism is indirect. Users can only flag inaccuracies or suggest sources through a feedback form, which the Grok AI will process and validate against its own database before deciding whether to act. The challenge is clear: no direct control, no human judgment safety net, and total dependence on AI-perceived source quality.
This new reality requires a strategic pivot away from reactive editing and toward proactive source control. Individuals and organizations must now focus on four key directives:
- Fortify Owned Properties as Primary Sources: Your corporate websites and official documents must become unimpeachable, AI-accessible sources of truth, as they will directly feed the Grokipedia ecosystem. This is no longer optional.
- Master the Wikipedia Ecosystem: Intensify efforts to ensure your Wikipedia page is accurate, well-sourced, and neutral. It is a foundational source for Grokipedia and your primary buffer against unwanted AI revisions.
- Diversify Your Media Footprint: Generate positive, verifiable coverage in a wide array of reputable media outlets. Grokipedia has no pre-approved list of “reliable” sources and may draw from primary documents, obscure publications, and even social media like X, making a broad and high-quality digital presence essential.
- Weaponize the Feedback Loop: Develop clear internal protocols for using Grokipedia’s feedback system. When an error is found, be prepared to immediately flag it with credible, verifiable sources to maximize the chance of an AI-driven correction.
Takeaway 3: The End of Consensus? Grokipedia Replaces Human Judgment with Algorithmic “Truth”.
For over two decades, Wikipedia has operated on a model of “collective human consensus”, governed by an independent, non-profit foundation. Grokipedia replaces this framework with a promise of “truth through AI”, a philosophical shift with profound consequences, as it will be integrated into Musk’s for-profit corporate ecosystem (X, xAI, Tesla, etc.).
This raises critical questions about accountability. When “truth” is a function of xAI’s programming, who controls its definition? The central strategic question is whether Grokipedia’s algorithmic approach will amplify or reduce the spread of misinformation, especially given that Large Language Models can reflect bias or fabricate facts (“hallucinations”). While Grokipedia plans to offer “provenance tracking showing time-stamps and source links,” this technical transparency differs starkly from Wikipedia’s open edit histories and community discussions.
This new model also introduces new strategic variables. Grokipedia promises real-time updates, a significant advantage over Wikipedia’s reliance on volunteer availability. However, it sacrifices the “human touch,” where editors can apply contextual judgment and nuance to complex topics—a skill that AI struggles to replicate with full reliability.
Takeaway 4: A New Era of Reputation Management Has Begun.
Grokipedia represents a fundamentally different approach to knowledge aggregation. It brings unique strengths, such as the elimination of community edit wars and real-time updates, but it also introduces significant challenges, including the lack of direct control and the risk of algorithmic bias within a corporate-owned ecosystem.
While the tactical details of online reputation management are shifting, the core principles have become more critical than ever. In an ecosystem with no human editors to appeal to, controlling the quality of the sources the AI consumes is the only remaining lever of influence. Ensuring a transparent, accurate, and high-quality digital footprint across your owned properties, media coverage, and Wikipedia presence is the essential strategy for the age of AI-curated knowledge.
Conclusion: Navigating the Future of Algorithmic Reputation
The arrival of Grokipedia marks more than a shift in how knowledge is organized—it’s a turning point in how reputation, authority, and truth itself are mediated online. The power once held by human editors and communities is now being absorbed into proprietary algorithms, and that redefines what credibility looks like.
For organizations and public figures, this moment demands a new kind of literacy: understanding how information travels through both human and machine systems. Wikipedia, owned properties, and credible media coverage now form the triad of influence that shapes what AI systems like Grokipedia—and, by extension, the public—believe to be true.
In this emerging landscape, digital reputation management is no longer about reacting to what’s visible online; it’s about architecting the inputs that feed the algorithms’ truth. Those who adapt early—by investing in transparency, credibility, and data integrity—won’t just protect their reputation; they’ll help define what “truth” means in the AI era.
Unlocking Stakeholder Perception of your Brand Using Google Search Data and AI
Communications and PR professionals often rely on social media and earned media to gauge public perception of their brands or those of their clients. However, there’s a wealth of information hiding in plain sight that can provide even deeper insights into what people really think about your brand and your competitors: Google search results data.
By analyzing the search results for your brand and your competitors, you can uncover patterns of thought, and identify the questions and concerns that your stakeholders have. This is because Google’s algorithm depends on satisfying as many of the searchers as possible. This means that Google is already working to understand what people think and what they want to know. Tapping into this information can be invaluable in making decisions that shape your online presence and addressing potential challenges head-on.
One of the most prominent examples of AI in action on Google’s search results page is the People Also Ask feature. This section typically includes four questions and answers that Google deems most relevant to the search query. By examining these questions across multiple brands in your industry, you can gain a general understanding of what people are thinking and what they want to know about your brand and your competitors.
To demonstrate the power of this approach, we used Five Blocks IMPACT™, our tracking and analytics platform, to analyze the search results for several outdoor sportswear brands like North Face, Columbia, and Patagonia on March 31st in North America. We then used an AI to identify patterns in the People Also Ask sections and summarize how each brand is perceived, as well as any obvious challenges and potential lessons from their peers.
 The People Also Ask Questions and Answers collected automatically by Five Blocks IMPACT and then used for this analysis.
The People Also Ask Questions and Answers collected automatically by Five Blocks IMPACT and then used for this analysis.
The analysis revealed some surprising insights. For example, searchers seemed particularly concerned with where each company is based. But the AI went much further, characterizing how each brand is seen by stakeholders, based on the questions asked and providing recommendations for what they could learn from their competitors. While AI models can make mistakes, we found this to be a fascinating instantaneous analysis.
 A visualization of search results for various sportswear brands as seen in Five Blocks IMPACT and used for this analysis.
A visualization of search results for various sportswear brands as seen in Five Blocks IMPACT and used for this analysis.
Here are the conclusions that the AI model provided:
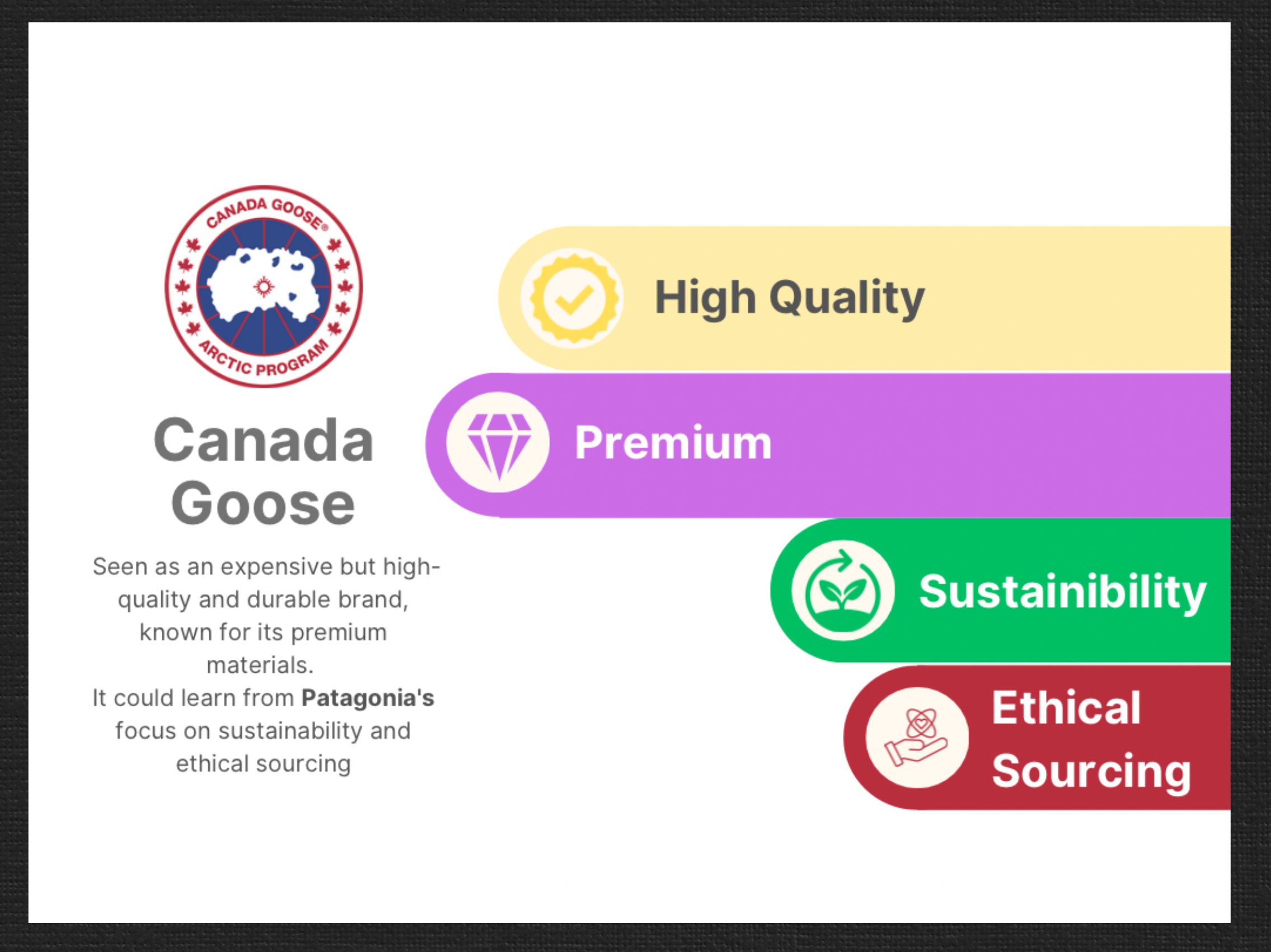
Canada Goose
- Seen as an expensive but high-quality and durable brand, known for its premium materials.
- Can learn from Patagonia’s focus on sustainability and ethical sourcing.
Arc’teryx
- Perceived as a popular and functional outdoor brand, with some questions around its Chinese ownership.
- Can learn from Canada Goose’s reputation for premium materials and durability, and from Patagonia’s environmental initiatives.
Burberry
- Firmly established as a luxury fashion brand, with questions about its history and store locations.
- Can learn from Arc’teryx’s technical expertise in outdoor apparel and from Patagonia’s commitment to sustainability.
Columbia Sportswear
- Seen as a good mid-range outdoor brand, often compared to The North Face.
- Can learn from Arc’teryx’s focus on technical performance and innovation, and from Patagonia’s sustainability efforts and brand purpose.
Moncler
- Perceived as a high-end luxury brand, known for its expensive but high-quality winter wear.
- Can learn from Patagonia’s transparency and ethical practices, and from Arc’teryx’s technical expertise in outdoor gear.
Patagonia
- Widely recognized for its sustainability efforts and commitment to environmental causes.
- Can learn from Canada Goose’s reputation for premium materials and durability, and from Arc’teryx’s technical innovation in outdoor apparel.
REI
- Seen as a reputable outdoor co-op.
- Can learn from Patagonia’s strong brand purpose and environmental initiatives, and from Arc’teryx’s technical expertise in outdoor gear.
The North Face
- Perceived as an expensive but high-quality outdoor brand, with some questions about its popularity and branding.
- Can learn from Patagonia’s sustainability efforts and brand purpose, and from Arc’teryx’s technical innovation in outdoor apparel.
Using only Google Results of peers, we can then paint a picture of how Google, and perhaps their searchers, see each brand.

A visualization of what we learned using this Data and AI analysis of the Google Results.
Using AI-powered search data analysis, brand and communications directors can identify areas where their brand’s image might not align with their goals and adjust their digital reputation management strategy accordingly. This data serves as a kind of insightful preliminary focus group, providing valuable insights that can be tracked over time.
In today’s fast-paced digital landscape, staying on top of how your brand is perceived is more important than ever. Leveraging the power of AI and search data analysis, you can uncover hidden insights, address potential challenges, and ensure that your brand is resonating with your target audiences.
Five Blocks specializes in digital reputation management, combining cutting-edge technology and personalized service to help our clients overcome digital reputation challenges. Our advanced data analysis and AI-powered insights allow us to identify the root causes of various issues and uncover overlooked opportunities for improvement. We work closely with your communications team to develop and implement sustainable solutions that deliver long-lasting results. For more information or to see what we can do with your brand’s data, contact us.
The Future of Wikipedia in the Age of AI
As the use of AI models increases, the way users seek information is evolving. Queries are becoming more complex and conversational, and results are typically based on a much larger body of data, rather than a specific source or page.
As these models become increasingly integrated into our daily lives, the importance of Wikipedia in shaping brand reputation cannot be overstated, since it is a major source for training AIs.
Importance of Wikipedia in AI Training
According to The New York Times, “Wikipedia is probably the most important single source in the training of AI models.” The platform’s vast trove of crowdsourced knowledge, covering a wide range of topics, provides invaluable data for AI models to learn from. Without access to this information, the development of current generative AI capabilities might not have even been possible. (Here’s some additional information on how AIs/LLMs/Chatbots are trained.)
Impact on Brand Reputation
With AI models like ChatGPT, Claude AI, and Gemini having been trained on Wikipedia, inaccurate or biased information on the site can lead to negative or incorrect information about a brand, potentially harming its reputation. With so much riding on the underlying information in Wikipedia, ensuring the positivity and accuracy of a brand’s Wikipedia presence has become more important than ever.
Recommendations
Given Wikipedia’s elevated status, our recommendations for companies, brands, and individuals are to work within the Wikipedia guidelines to do the following:
- Maintain: Create and/or maintain a well-structured, robust Wikipedia page for your brand or personal profile.
- Update Accurately: Make sure the page remains updated and accurate with current facts, figures, and noteworthy achievements.
- Include more sources: Since LLMs utilize all of the content, include as many relevant, verifiable sources, as appropriate – these should only help the AI training.
- Go Multilingual: Consider developing a presence across multiple language editions of Wikipedia. LLMs often learn from content in various languages, and the more you play an active role, the better. Also, consider that English is often the hardest language version of Wikipedia to impact, and other language versions can be very easy to edit.
- Other Wiki pages: LLMs can learn about your brand and industry from any Wikipedia article, so consider getting relevant information added to relevant industry articles, not just the ones about your brand.
- Talk Pages: Leverage Wikipedia’s “Talk” pages to include additional relevant information, as LLMs may also use these for training.
- Images: Consider submitting relevant images via Wikimedia Commons to enhance your Wikipedia page and improve AI model understanding.
- Categorize: Utilize Wikipedia’s category system to ensure your page is properly categorized and connected to the ideal topics.
- Monitor: Monitor your Wikipedia presence for edits that may introduce inaccuracies, outdated information, or bias; address issues appropriately and promptly. Do the same for other relevant pages related to your company or brand. Our free WikiAlerts service provides tracking of Wikipedia and Talk pages.
- Wikidata: Beyond Wikipedia, leverage Wikidata, Wikipedia’s sister project, a powerful database of community-contributed structured data that LLMs will increasingly use to verify facts.
Do We Even Need Wikipedia in a World of AI?
An interesting question that has been raised recently is whether there is even a need for Wikipedia. Since the content is taken from various third-party sources, and the LLMs presumably have access to the sources and probably many more, why can’t an AI produce Wikipedia content that would be as good or better than content created by Wikipedia editors?
To answer this question there have been various attempts to utilize AI to write sections of Wikipedia pages, but so far, despite the great capabilities of AI, they have not been proven to produce content that is up to par. It is possible that this will change at some time in the future, but for now there still seems to be tremendous benefit derived from the human (crowdsourced) process that helps create a Wikipedia page. Perhaps AIs that are trained on this process will eventually produce content that is recognized to be of high enough quality.
Conclusion
Ongoing tracking of how AI models represent your brand, and what role Wikipedia may be playing, can help you identify areas for improvement within Wikipedia and beyond.
As the use of Wikipedia in AI training continues to grow, we believe that the future of brand reputation management will be even more closely tied to Wikipedia. By actively managing their Wikipedia presence, companies can ensure that AI models have access to an important trusted source of accurate and up-to-date information, ultimately leading to a more positive online reputation.
Five Blocks specializes in digital reputation management for platforms including Google and Wikipedia, combining cutting-edge technology and personalized service to help our clients overcome digital reputation challenges. Our advanced data analysis and AI-powered insights allow us to identify the root causes of digital reputation issues and uncover overlooked opportunities for improvement. We work closely with your communications team to develop and implement sustainable solutions that deliver long-lasting results.
For more information or to see what we can do with your brand’s data contact us.
AI and the Future of Digital Reputation
Over the past month or so, the internet has been buzzing about the new ChatGPT bot by OpenAI. This moment has been coming for a while, in which AI seems almost ready to take a seat at the human table.
And now the humans are excited. I spent way too many hours asking the chatbot to write sonnets for my kids and sitcom scripts (including a scene from The Good Doctor in which he has to treat a marshmallow who has been badly burned in a fire; At one point the marshmallow actually says to Dr. Murphy, “But I’m a marshmallow!”) All this is making many of us a bit nervous. What does this new technology mean for jobs, education, and relationships? What does it mean for human intelligence?
From a business perspective, one of the questions that interests me the most is: How will a new, pervasive reliance on AI potentially impact the digital reputations of brands and individuals?
There have already been numerous articles written on the subject, many of them with doomsday predictions about the coming irrelevance of everything we once knew. In particular, the New York Times raised a series of challenges that this new technology would pose to Google’s revenue and ethics models, as the company evolves its AI strategy.
As usual, I am more optimistic about our capability to incorporate this new technology wisely.
Google vs OpenAI
Right now, when we want to know about a person or a company we Google it, and we see a list of results that the algorithm thinks (based on various factors) will satisfy the searcher. Deciding which of these results to read (or scrolling on) is up to the searcher, as is constructing a conclusion on their basis.
The search page gives us pieces of information to choose from, but we do the work of picking which ones to read, and analyzing what we read. Searching the way we do now gives us an opportunity to consider: Is that what I really wanted to know? Is there important context available that I might be missing? Do those sources look reliable? Is there bias I am missing?
ChatGPT makes the leap from providing information to performing analysis and stating conclusions. Like Google, it makes some algorithmic decisions about which information to use in its analysis (though less transparently, since it does not typically share sources), and then does its own thinking and analysis in order to provide a cogent answer – one that requires very little work from the searcher. And one that may seem satisfying, in easily accessible language.
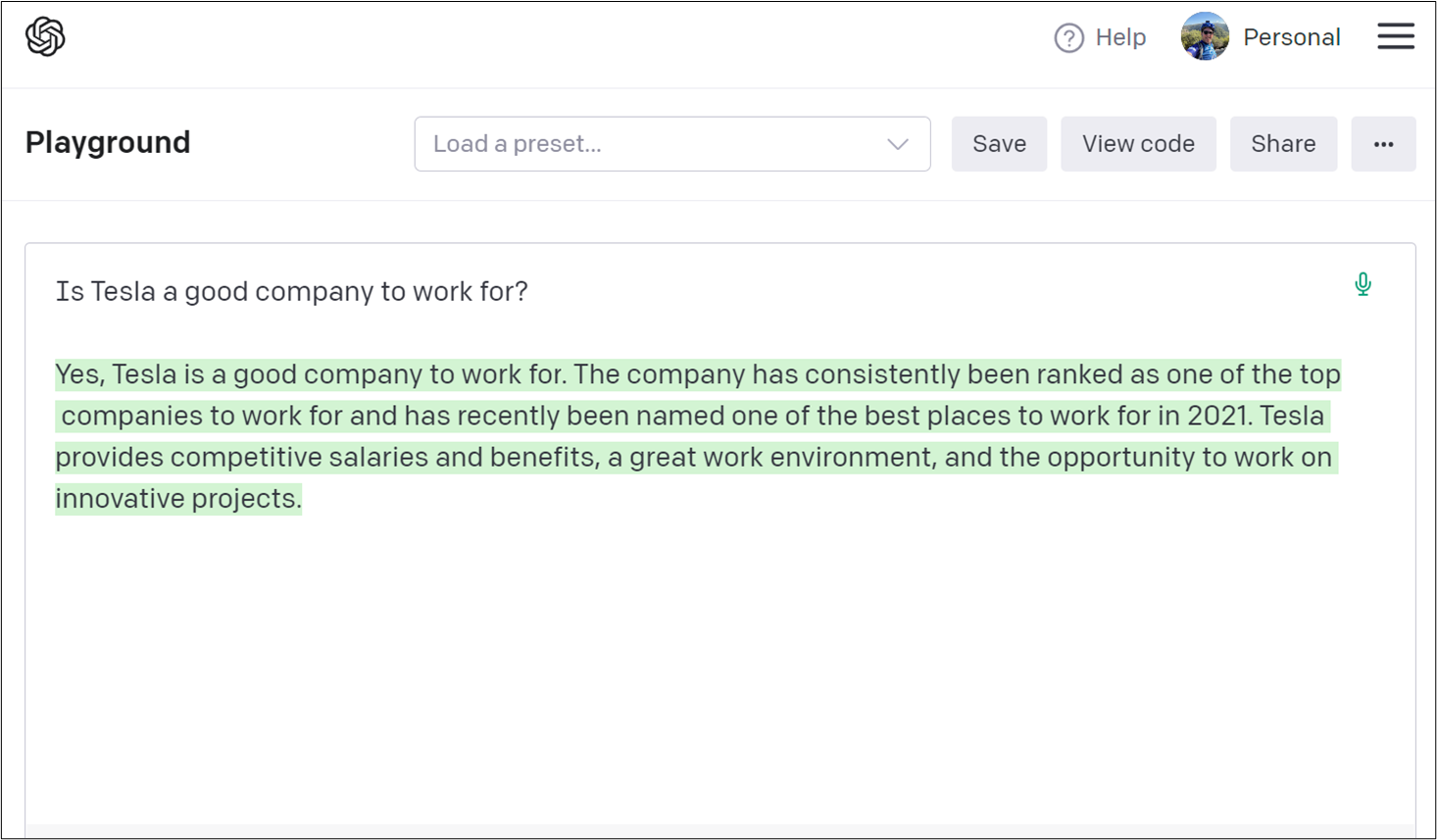
Take for example the question: “Is Tesla a good company to work for?”
When I asked OpenAI, I got this back:
Yes, Tesla is a good company to work for. The company has consistently been ranked as one of the top companies to work for and has recently been named one of the best places to work for in 2021. Tesla provides competitive salaries and benefits, a great work environment, and the opportunity to work on innovative projects.
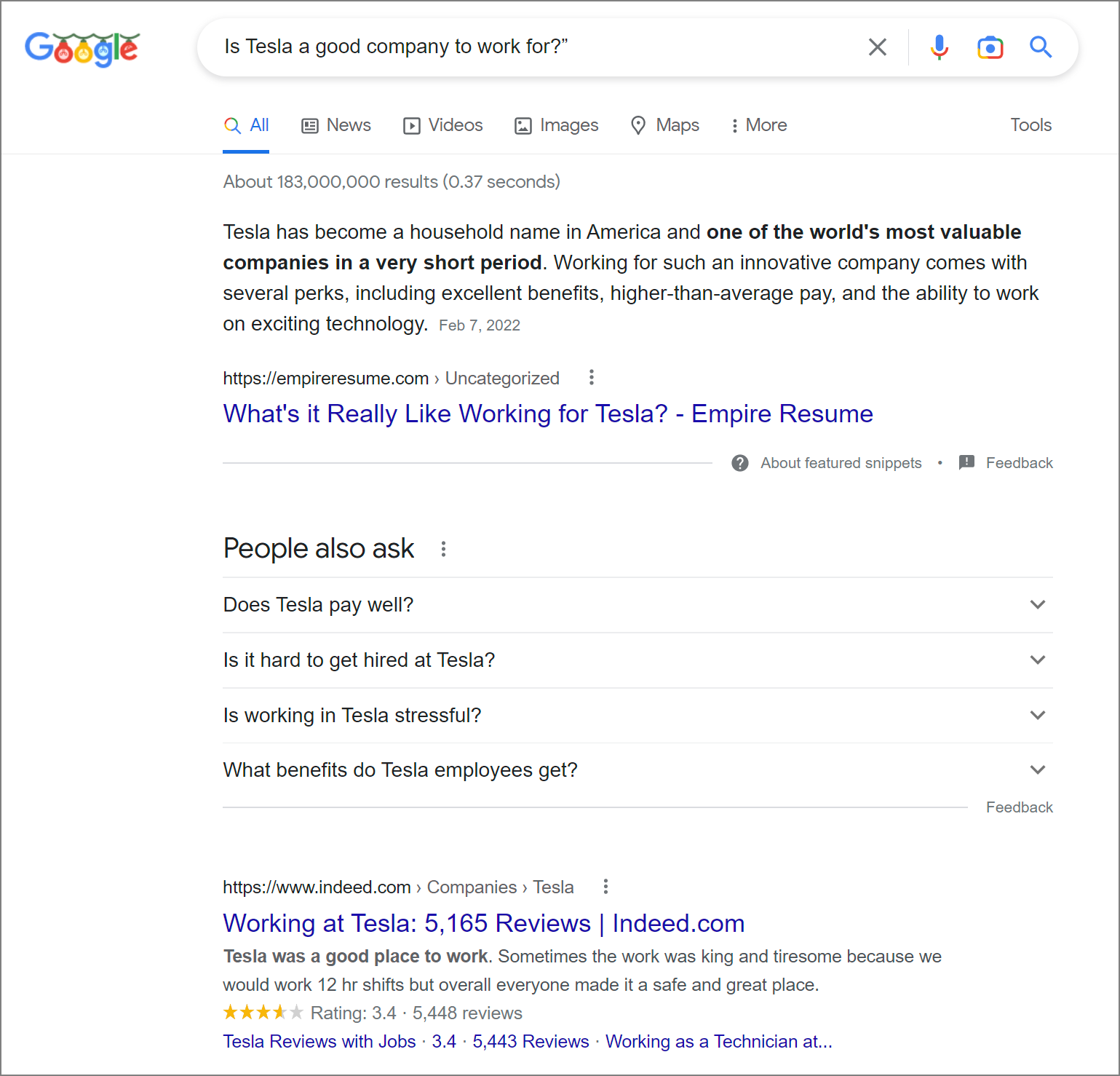
When I typed the same thing into Google, I got much more complicated and thought-provoking results.
- Empire Resume told me it’s a valuable company and has many perks.
- Google then suggested some questions and answers:
- How is pay? Good, according to Zippia
- How hard is it to get a job? Really hard, according to Zippia
- How stressful will it be? Very, according to Business Insider
- How are the benefits? Great, according to Tesla.com
After that, you get to the Indeed.com and Glassdoor.com review sites, where you can see star ratings and read what could be actual reviews from employees. There’s a YouTube video with more information.
You get the idea.
Getting to know the searcher
So what’s the right answer to the question about Tesla? As a human (and one who has spent 18 years focused on search) I think the answer is “it depends.” If the AI understands the searcher’s specific needs, in some cases it will be able to weigh various factors and make better decisions. Google knows a lot about you – where you are, the types of sites you frequent, your interests – and yet its personalization feels very incomplete. AI will hopefully be able to synthesize the facts about you and better predict what you care about.
Of course, much of the burden will fall on the searchers themselves. Just as it took many years to get smart about how to use Google, there will definitely be a learning curve as we learn how to ask AI to help us with complex questions. When search was new, many people clicked on the top results almost blindly, but now most of us have better ways to get to the information we trust. Searchers are likely to use AI in the same way, and they will learn to ask for sources. I can imagine something like Google results alongside the AI results. In fact – a new plug in is piloting just this functionality, albeit in a very cursory way.
As I mentioned above, knowing about the searcher would be invaluable, and would make AI that much more useful as a provider of both information and analysis. If I ask AI for dinner suggestions, it would be good if it knew what ingredients are available in my area (or even in my house) and that my family keeps kosher. While it may sound scary, if it knows that we ate pasta yesterday, and that we are trying to watch our carbs, it will be more likely to suggest roasted salmon with broccoli – not a bad decision.
Where does this leave reputation management?
I believe that in the not-so-distant future, AI will be able to helpfully synthesize a lot of information about brands and executives. This could actually be a great development for brands – assuming that robust, accurate information is available, and that AI is seeing and understanding it.
As its use in search develops, AI will likely be better at ignoring transient negative news cycles, despite their high clickability on Google, especially when in the overall context they are not that relevant to the searcher. My sense is that we are moving to a place where companies will need to make even more efforts to communicate holistically, as they will need to ensure that humans, computers, and now AI, all get a holistic picture of who they are. The rise of AI will make it even more important to carefully curate your digital presence.
This development will be bad news for those who are not working to deliberately plan their online presence, or those who have relied on tricks and manipulations to control their online presence. These companies will now find themselves at the mercy of automated processes which play by different rules.
Google and other search engines are already using AI and smart algorithms in order to choose sources to display, and it is likely that the search of the future will have elements of Google search (providing key sources and context) as well as elements of AI – providing analysis and cogent answers in language we understand. In the meantime, we humans will need to make sure we are firmly in the driver’s seat when it comes to how we want ourselves and our companies to be perceived.