What Sources does Grokipedia use for its Fortune 100 Articles
As tools like Grokipedia begin to sit alongside Wikipedia, search results, and AI assistants, they are no longer just reflecting public information – they are actively shaping it. To understand what this shift means in practice, we analyzed how Grokipedia represents the Fortune 100, digging into nearly 19,000 sources to see where the information comes from, what gets emphasized, and how this new, AI-curated model differs from the human-edited standard brands have relied on for years.
Why Grokipedia matters
Grokipedia is making a bold wager: replacing Wikipedia’s human editors with algorithmic curation. Instead of volunteer consensus and strict sourcing rules, Grokipedia relies on AI systems to decide what information matters and which sources are credible.
That shift raises an important question for brands and communicators:
What actually happens to corporate narratives when AI, not humans, becomes the editor?
The big picture: more sources, different priorities
Grokipedia articles are not necessarily longer than their Wikipedia counterparts. But they are far more heavily sourced.
- Average sources per Fortune 100 company: 187
- Highest count: Apple, with 359 sources
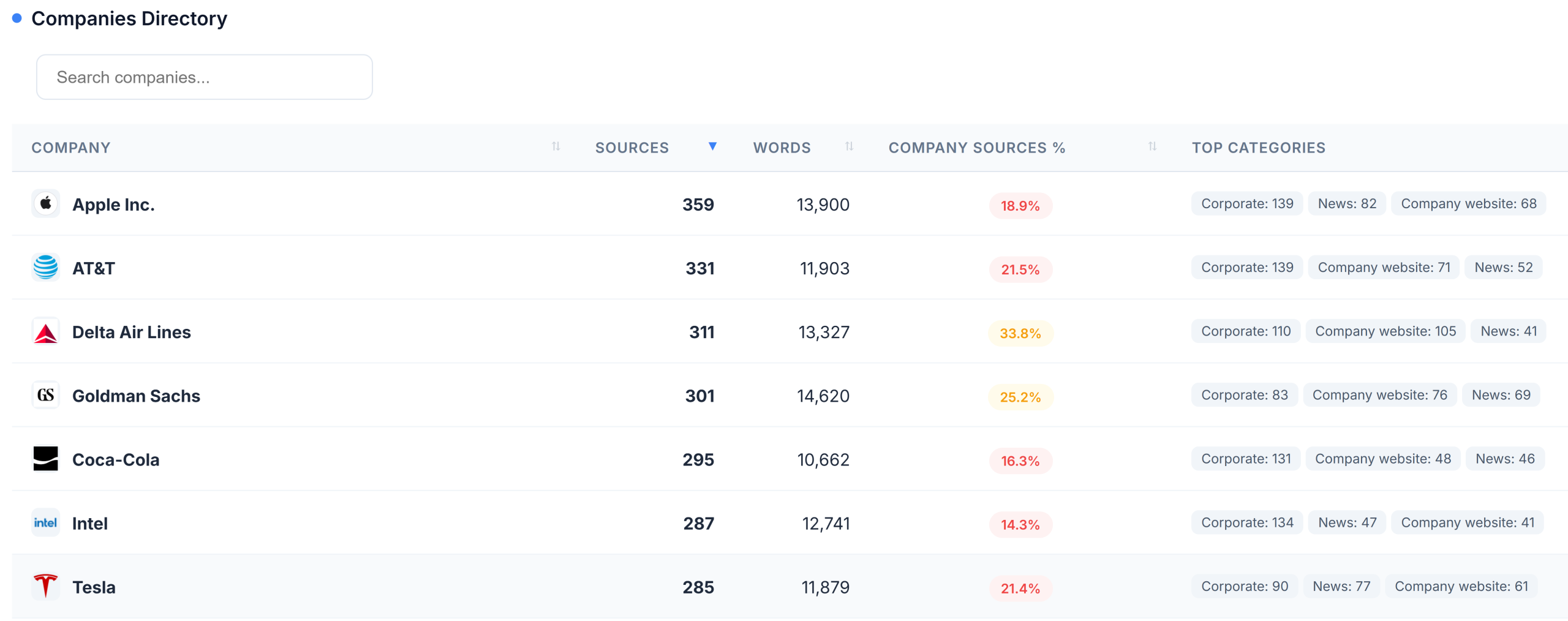
This volume alone signals something important: Grokipedia’s model values aggregation and breadth over editorial restraint. But the real story lies in what sources it chooses.
Where Grokipedia gets its information
Across all Fortune 100 articles, sources break down as follows:
- Corporate sources: 34.5% (6,477 citations)
- Company websites: 27.2% (5,112 citations)
- News media: 16.3% (3,050 citations)
- Government: 7.0% (1,319 citations)
- Financial / Academic / Trade: 7.5% (1,408 citations)
- Social media: 1.8% (335 citations)
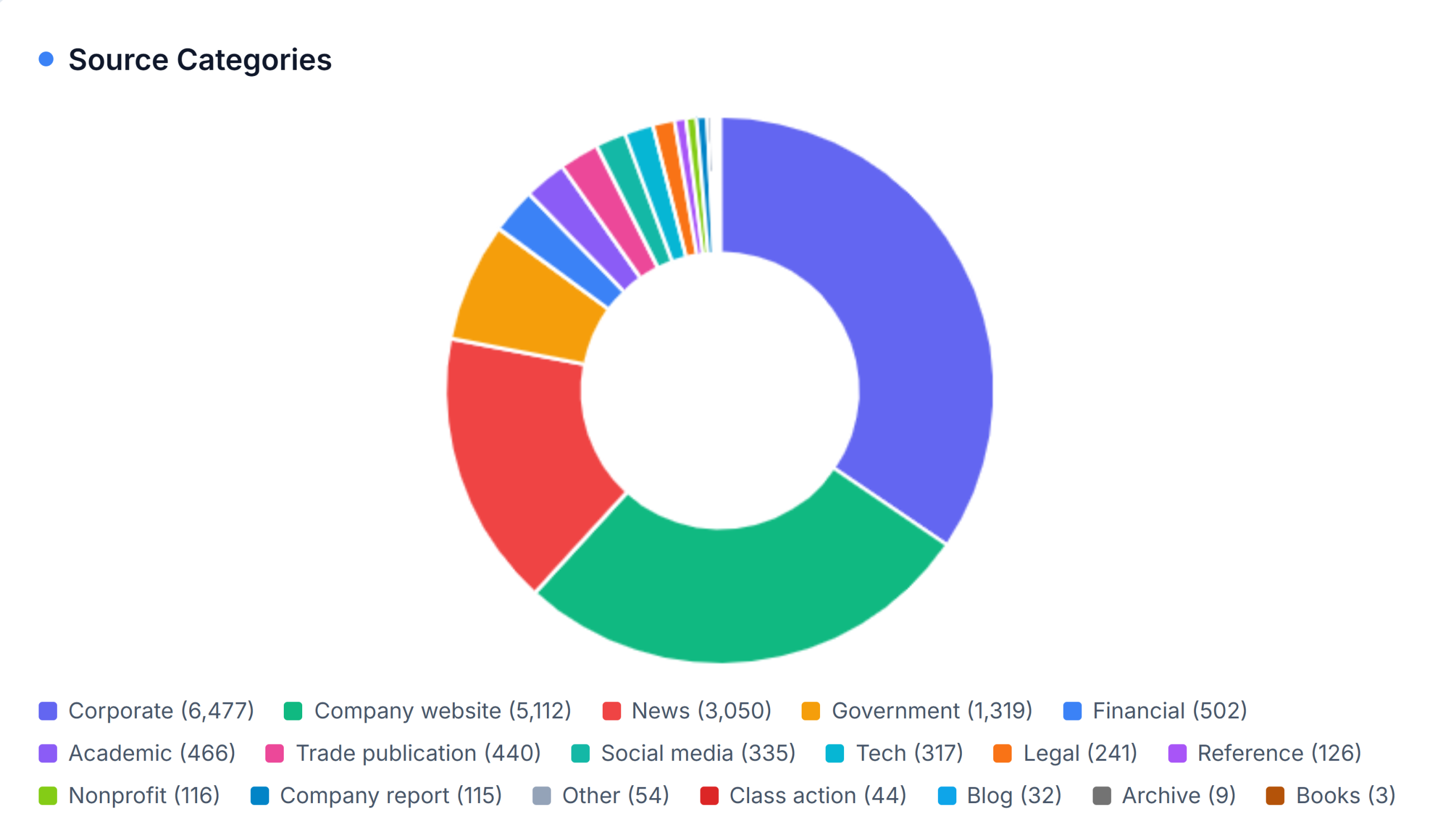
This alone marks a major departure from Wikipedia, which treats corporate and self-published sources as inherently suspect. Grokipedia does the opposite.
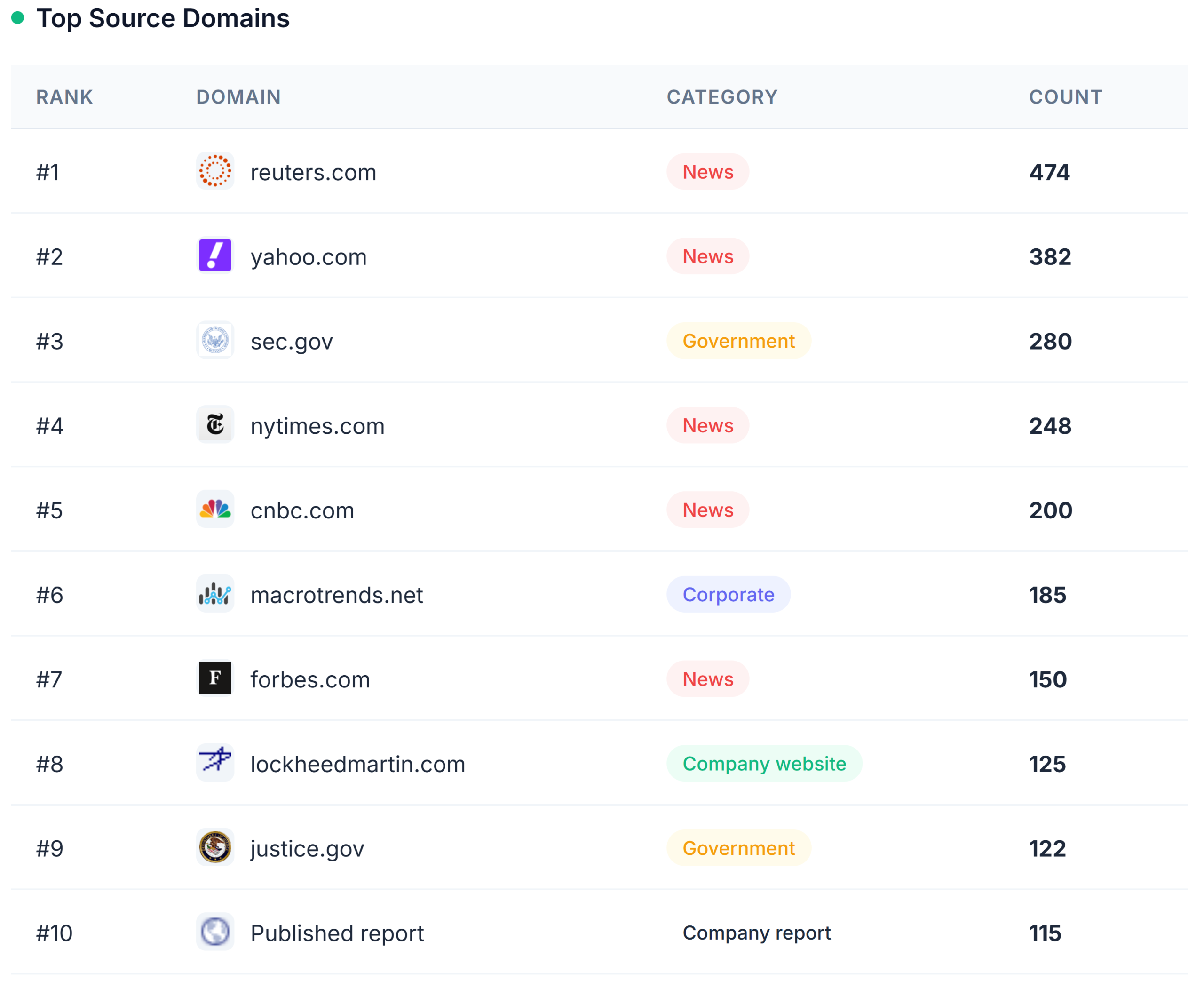
The most-cited domains across the Fortune 100
Here are the top 10 domains cited across all Fortune 100 Grokipedia pages:
- Reuters.com(474)
- Yahoo.com (382)
- SEC.gov (280)
- NYTimes.com (248)
- CNBC.com (200)
- Macrotrends.net (185)
- Forbes.com (150)
- LockheedMartin.com (125)
- Justice.gov (122)
- Published reports (115)
What surprised us most
A company website cracked the top 10 overall.
Lockheed Martin’s corporate site appears 125 times across Grokipedia—but not because it’s cited broadly. It’s because Grokipedia’s Lockheed Martin page relies heavily(!) on the company’s own materials.
Equally interesting: TD Synnex sources 60.8% of its Grokipedia citations from its own website
This represents a fundamental break from Wikipedia’s editorial philosophy. Where Wikipedia views corporate sites as biased and secondary, Grokipedia treats them as primary sources of truth.
Social media: barely present
Early critics worried Grokipedia would overweight X (formerly Twitter). The data tells a different story with social media accounting for under 2% of all citations
- LinkedIn leads with 75 citations
- Facebook – 40 citations
- Reddit – 38 citations
- YouTube – 31 citations
- X.com appears just 14 times
Despite Grokipedia’s ownership of X, social platforms are not driving corporate narratives on the platform itself.
PR Newswire is doing well!
Another sharp contrast with Wikipedia and Google Page 1:
PR Newswire ranks #7 among news sources, with 95 citations
Wikipedia rarely allows press releases as sources, while Grokipedia treats them as legitimate references – giving companies a direct channel into AI-generated “encyclopedic” content.
What this means for communications teams
The shift from human-curated to AI-curated knowledge changes the playbook.
1. Your corporate website now matters more than ever
It is no longer just a destination – it can become the primary source for LLMs.
2. Government filings carry outsized influence
SEC.gov (#3) and Justice.gov (#9) rank among the most-cited domains.
AI systems read and index everything, including filings, enforcement actions, and regulatory language.
3. Earned media still matters – but the mix is changing
Reuters and legacy outlets dominate, but trade publications and financial data aggregators (440 citations combined) remain highly influential.
4. Wikipedia is no longer the single source of record
Fixing Wikipedia is no longer sufficient. Grokipedia and similar AI-driven platforms are building parallel narratives, governed by entirely different editorial logic.
Explore the data yourself
We’ve created an interactive dashboard where you can dig into all of the data here!
The dashboard allows you to look at each company individually as well!
Grokipedia Isn’t Just an AI Wikipedia

Introduction: The Next Chapter in Online Knowledge
In September 2025, Elon Musk’s company xAI announced the upcoming launch of Grokipedia, a fully AI-powered alternative to Wikipedia. Positioned as a solution to the editorial biases Musk perceives in the long-standing online encyclopedia, Grokipedia promises a new model for knowledge aggregation, driven entirely by artificial intelligence.
The immediate assumption is that this is a simple platform war: out with the old, volunteer-driven model and in with a new, algorithmically-curated system. However, this shift from a human-moderated commons to a corporate-controlled algorithm is not a simple competitive maneuver; it is a fundamental rewiring of how online truth is established and challenged, with profound implications for digital reputation.
The relationship between these two platforms is not one of simple opposition. In fact, Grokipedia’s core design creates a series of counter-intuitive dependencies and strategic necessities that every brand and public figure must understand. This article unpacks the four most counter-intuitive takeaways for your digital reputation.
Takeaway 1: Grokipedia’s Biggest Secret? It Needs Wikipedia to Survive.
Far from ignoring its predecessor, Grokipedia will use public information from sources like news and books, with Wikipedia serving as a primary foundational dataset. The process is designed for AI-driven refinement, not outright replacement. Grok will systematically scan existing Wikipedia articles, evaluate their claims as true, partially true, false, or missing, and then use its AI to rewrite them, aiming to fix falsehoods and add omitted context.
This dependency creates a surprising strategic imperative: maintaining a robust and accurate Wikipedia presence is now more important, not less. Because Grokipedia will use Wikipedia as its starting point, a well-sourced, comprehensive, and neutral article on the original platform serves as the first line of defense against unwanted algorithmic changes.
The more robust a Wikipedia page is, the less likely it is to be changed by Grokipedia.
The irony is clear. To effectively manage your presence on the new AI-powered encyclopedia, you must first double down on your commitment to the old, human-edited one. The best defense against unwanted AI edits in this new era is to ensure the source material it relies on is as accurate and complete as possible.
Takeaway 2: You Can’t Directly Edit Grokipedia—And That Changes Everything.
Grokipedia’s most fundamental departure from Wikipedia is the elimination of direct human editing. The familiar tactics of logging in to correct an error or engaging in “talk page negotiations” with other editors will be impossible. This represents a monumental shift for reputation management.
Instead, the new mechanism is indirect. Users can only flag inaccuracies or suggest sources through a feedback form, which the Grok AI will process and validate against its own database before deciding whether to act. The challenge is clear: no direct control, no human judgment safety net, and total dependence on AI-perceived source quality.
This new reality requires a strategic pivot away from reactive editing and toward proactive source control. Individuals and organizations must now focus on four key directives:
- Fortify Owned Properties as Primary Sources: Your corporate websites and official documents must become unimpeachable, AI-accessible sources of truth, as they will directly feed the Grokipedia ecosystem. This is no longer optional.
- Master the Wikipedia Ecosystem: Intensify efforts to ensure your Wikipedia page is accurate, well-sourced, and neutral. It is a foundational source for Grokipedia and your primary buffer against unwanted AI revisions.
- Diversify Your Media Footprint: Generate positive, verifiable coverage in a wide array of reputable media outlets. Grokipedia has no pre-approved list of “reliable” sources and may draw from primary documents, obscure publications, and even social media like X, making a broad and high-quality digital presence essential.
- Weaponize the Feedback Loop: Develop clear internal protocols for using Grokipedia’s feedback system. When an error is found, be prepared to immediately flag it with credible, verifiable sources to maximize the chance of an AI-driven correction.
Takeaway 3: The End of Consensus? Grokipedia Replaces Human Judgment with Algorithmic “Truth”.
For over two decades, Wikipedia has operated on a model of “collective human consensus”, governed by an independent, non-profit foundation. Grokipedia replaces this framework with a promise of “truth through AI”, a philosophical shift with profound consequences, as it will be integrated into Musk’s for-profit corporate ecosystem (X, xAI, Tesla, etc.).
This raises critical questions about accountability. When “truth” is a function of xAI’s programming, who controls its definition? The central strategic question is whether Grokipedia’s algorithmic approach will amplify or reduce the spread of misinformation, especially given that Large Language Models can reflect bias or fabricate facts (“hallucinations”). While Grokipedia plans to offer “provenance tracking showing time-stamps and source links,” this technical transparency differs starkly from Wikipedia’s open edit histories and community discussions.
This new model also introduces new strategic variables. Grokipedia promises real-time updates, a significant advantage over Wikipedia’s reliance on volunteer availability. However, it sacrifices the “human touch,” where editors can apply contextual judgment and nuance to complex topics—a skill that AI struggles to replicate with full reliability.
Takeaway 4: A New Era of Reputation Management Has Begun.
Grokipedia represents a fundamentally different approach to knowledge aggregation. It brings unique strengths, such as the elimination of community edit wars and real-time updates, but it also introduces significant challenges, including the lack of direct control and the risk of algorithmic bias within a corporate-owned ecosystem.
While the tactical details of online reputation management are shifting, the core principles have become more critical than ever. In an ecosystem with no human editors to appeal to, controlling the quality of the sources the AI consumes is the only remaining lever of influence. Ensuring a transparent, accurate, and high-quality digital footprint across your owned properties, media coverage, and Wikipedia presence is the essential strategy for the age of AI-curated knowledge.
Conclusion: Navigating the Future of Algorithmic Reputation
The arrival of Grokipedia marks more than a shift in how knowledge is organized—it’s a turning point in how reputation, authority, and truth itself are mediated online. The power once held by human editors and communities is now being absorbed into proprietary algorithms, and that redefines what credibility looks like.
For organizations and public figures, this moment demands a new kind of literacy: understanding how information travels through both human and machine systems. Wikipedia, owned properties, and credible media coverage now form the triad of influence that shapes what AI systems like Grokipedia—and, by extension, the public—believe to be true.
In this emerging landscape, digital reputation management is no longer about reacting to what’s visible online; it’s about architecting the inputs that feed the algorithms’ truth. Those who adapt early—by investing in transparency, credibility, and data integrity—won’t just protect their reputation; they’ll help define what “truth” means in the AI era.