Your Brand Doesn’t Exist Unless AI Says It Does

Your brand isn’t what you say it is anymore, it’s what the AI concludes it is.
For two decades, digital strategy was about “the click,” fighting for page one of Google so users would visit your website. But the ground has shifted. We’re no longer in an era of search; we’re in an era of synthesis.
When someone asks ChatGPT, Gemini, or Perplexity about your company, they’re not clicking through to your website. They’re getting an answer, synthesized from whatever data the AI can find. If your digital footprint is thin, incomplete, or outdated, the AI will fill the void with whatever it finds. Or worse, it will hallucinate.
In Hirsch Leatherwood’s latest podcast, Five Blocks CEO Sam Michelson breaks down what this shift means for your brand and how to prepare for 2026.
Key Insights from the Conversation:
The Death of the Click
Traffic is a disappearing metric. Users stay in the browser window with AI, they don’t need to visit your site anymore. The new KPI isn’t traffic; it’s presence. How accurately and frequently does AI represent your brand?
Your Website is a Training Manual
Traditional websites were brochures. Now they’re data sources for AI models. If you don’t provide rich, structured content, the AI will pull from less reliable sources or invent a narrative. Nature abhors a vacuum, and so does an LLM.
Wikipedia and Earned Media Matter More Than Ever
Despite the fragmentation of AI models, they all share common trusted sources. Wikipedia remains the ultimate pillar, if your entry is outdated, that error gets amplified everywhere. Earned media and third-party validation provide the “proof” AI needs to avoid hallucinations.
The brands that thrive in 2026 will be the ones that treat their digital footprint as an open data source, feeding the models that now define their reputation.
Behind the Scenes at Five Blocks: Donna
We’re continuing our series spotlighting the people behind Five Blocks—the team members whose work and expertise shape what we deliver to clients every day.
This time, we’re sitting down with Donna, a Senior Content Writer who has been with Five Blocks for 16 years. Donna works on our Wikipedia team, helping clients navigate one of the most visible—and carefully governed—platforms on the internet.
Before joining Five Blocks, Donna earned a BS in Microbiology from UC Berkeley and conducted cancer research at Memorial Sloan Kettering in New York City. When she started raising her family, she stepped away from formal work but remained active through volunteer work and various writing projects.
Let’s get to know Donna.

What are your favorite work tools?
Since I still remember working without these tools, I know how helpful and time-saving the following are:
- Who Wrote That – indicates which editor wrote specific text, when they wrote it, and what percentage of the article they contributed. (Highly recommended!)
- Wikipedia Editor Activity Tracker – tells you when an editor made his/her last edit.
- Wikipedia UserTags – shows you how many edits an editor has made in the past week.
- WikiAlerts by Five Blocks – alerts you when an edit has been made to your Wikipedia page.
- Google Calendar – let’s me track team schedules. (So, I know where everyone is at all times. Maybe not so useful, but super fun!)
Which part of your job makes you feel like a superhero?
Making sure all the batteries are charged. Although I don’t do that anymore, sadly. The next best thing is when our clients make a direct edit with no mistakes and no pushback.

What is your favorite weekend ritual?
Going to visit my children and grandchildren on Fridays. Oh, and sleeping in!
What hobby or activity could you spend hours doing without realizing it?
Watching good movies.
If you could instantly master a new skill, what would it be?
Playing piano.

Pancakes or waffles? And what’s your favorite topping?
I don’t eat either, but I like chocolate sprinkles on ice cream and croutons in chicken soup.

What’s the weirdest or most random thing on your desk right now?
I have two lava lamps. Isn’t that cool?
What is your favorite snack:
Brownies, ice cream, chocolate chip cookies, dark chocolate, 1.7% plain yogurt.
Favorite quote:
I have 3…
1. If you lived here, you’d be home by now.
2. Rumors of my death have been greatly exaggerated.
3. Better to be quiet and let people think you are stupid than to open your mouth and prove it.
Thanks, Donna, for letting us get to know you and for the craft and care you bring to every piece of content. We’re continuing this series with more voices from the Five Blocks team—check back soon for the next spotlight!
Behind the Scenes at Five Blocks: Nahum
We’re launching a new blog series to spotlight the people who make Five Blocks what it is—the team working behind the scenes every day to support our clients. It’s a chance to get to know the individuals who bring thoughtfulness, expertise, and energy to everything we do, even when their contributions aren’t always visible.
We’re starting the series with Nahum, a Senior Account Manager who has been with Five Blocks for four years. Beyond leading client work, Nahum is also part of our culture committee, helping shape how we celebrate holidays, connect as a team, and create the moments that make Five Blocks a great place to work.
With no further ado, let’s get to know Nahum.

How would you describe your job with emojis?
👀 Monitor ☕ Coffee 🔍 Research 🤝 Manage 🚨 Crisis 🍵 Coffee 😎 Calm 💻 Reputation 🔁 Repeat
What’s the funniest or weirdest thing that’s happened to you at work?
I was on a call with an important client and the WiFi crashed, got back on the call and it crashed again. Ended up going outside, setting up a hotspot from my cell and doing the rest of the call outside on the hood of my car.
What hobby or activity could you spend hours doing without realizing it?
Playing the drums and jamming with my band Red & the Baldies.

If you could live anywhere for a year, where would it be?
A beach in Hawaii, in the shade, with several layers of sunscreen.

What’s a hidden talent you have that not many people know about?
I do voice-over work as a (very) side gig and can (and do) drum on everything within reach.
Mac and cheese or tuna noodle casserole – or a completely different comfort food?
I’d rather go with low and slow smoked beef brisket, short ribs, top-sirloin cap picanha, and duck breast in a honey-mustard sauce. If I can’t have that, just give me a chocolate milk in a bag.
Sweet, salty, or spicy — which snack can you not resist?
Sweet! Donuts or fresh pastries are impossible for me to resist.

What’s your go-to karaoke song (even if you’d never sing it in public)?
100% “Mustang Sally.” I’ll sing it anywhere.
What’s your “guilty pleasure” show, movie, or podcast?
Show, movie or book connected with Harlan Coban.
What’s the weirdest or most random thing on your desk right now?
Pink spoons from Baskin-Robbins.

Favorite quote:
From the one and only Robin Williams: “Everyone you meet is fighting a battle you know nothing about. Be kind. Always.”
Thanks, Nahum, for letting us get to know you and for all the energy and dedication you bring to Five Blocks. This is just the start of our series highlighting the amazing people behind the work we do—stay tuned for the next employee spotlight!
Beyond Deletion: What ChatGPT’s Use of Hidden Wikipedia Pages Reveals About AI Reputation

For years, Google has been the ultimate arbiter of online visibility. If a page didn’t appear in Google’s index, it effectively didn’t exist in the public eye. Brands, communicators, and reputation managers learned to play by Google’s rules — optimizing what could be found, fixing what was misleading, and deleting what was outdated.
But artificial intelligence is rewriting those rules in real time.
Recently, we made a surprising discovery that raises new questions about how AI systems like ChatGPT access and represent information — and what that means for brands. ChatGPT cited Wikipedia pages that not only weren’t indexed by Google but, in some cases, had been deleted from Wikipedia entirely months earlier.
In other words: ChatGPT appears to be referencing information that no longer exists on the open web.
This finding, while seemingly small, points to a much larger shift. It suggests that ChatGPT operates from a different kind of index — one not governed by Google or Bing, but by the model’s own memory and training data. And that has profound implications for online reputation.
1. The Discovery
At Five Blocks, we regularly analyze how information about companies and individuals appears across platforms — from search results to knowledge panels to AI-generated summaries.
During one of these analyses, we noticed something odd: ChatGPT was citing a Wikipedia page about a company that had been deleted from Wikipedia months earlier. Even more surprising, the page had never been indexed by Google — likely due to Wikipedia’s internal restrictions on certain pages and drafts.
In short, ChatGPT seemed to know something that should have been impossible for it to know.
When we tested further, we found similar examples. In some cases, ChatGPT referenced archived or draft Wikipedia pages that were not accessible through normal search.
This means ChatGPT’s knowledge base includes content that is invisible to both users and search engines — a sort of ghost archive of the internet.
The image below from our AIQ platform shows an example of ChatGPT referencing a deleted Wikipedia page:
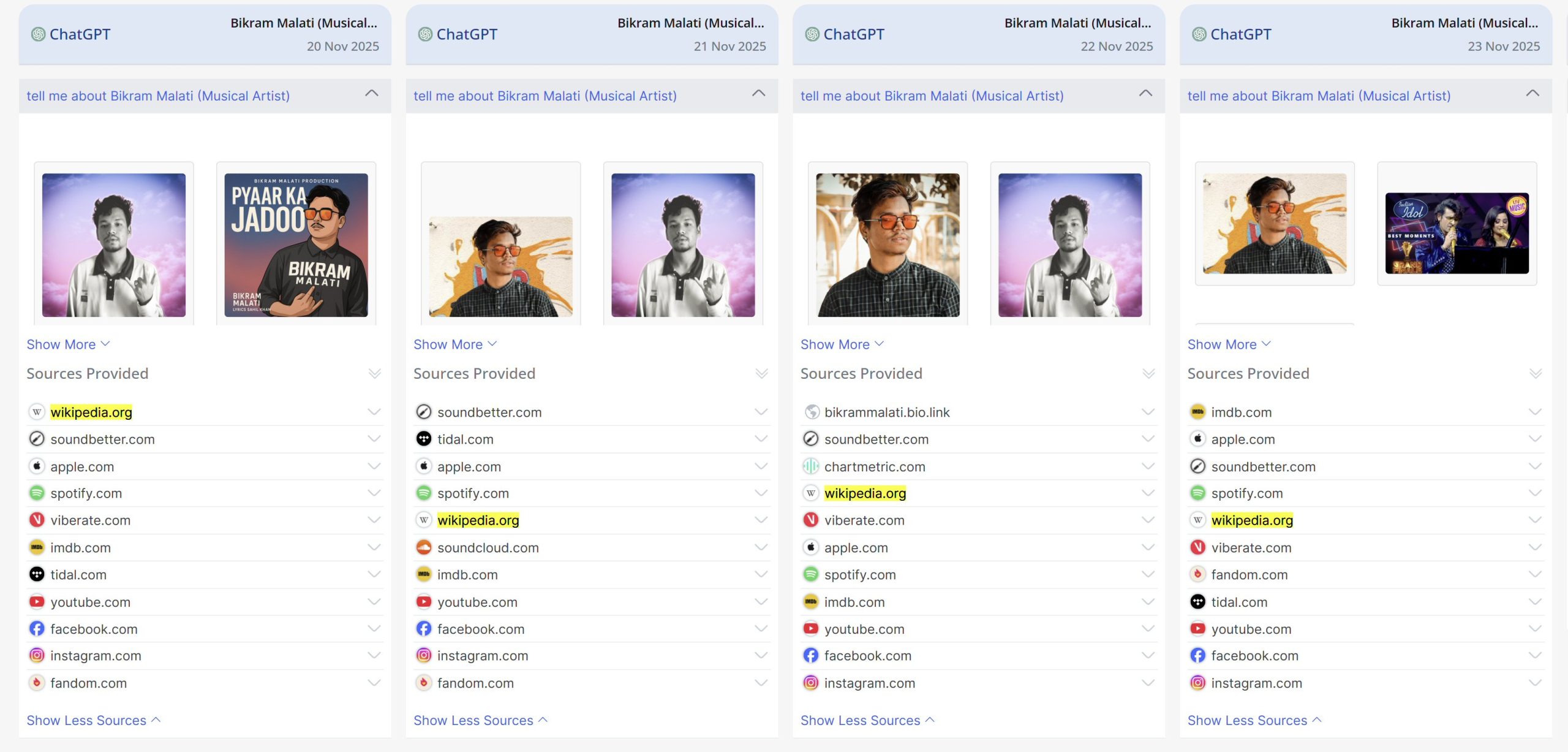
Here is an actual ChatGPT screenshot:
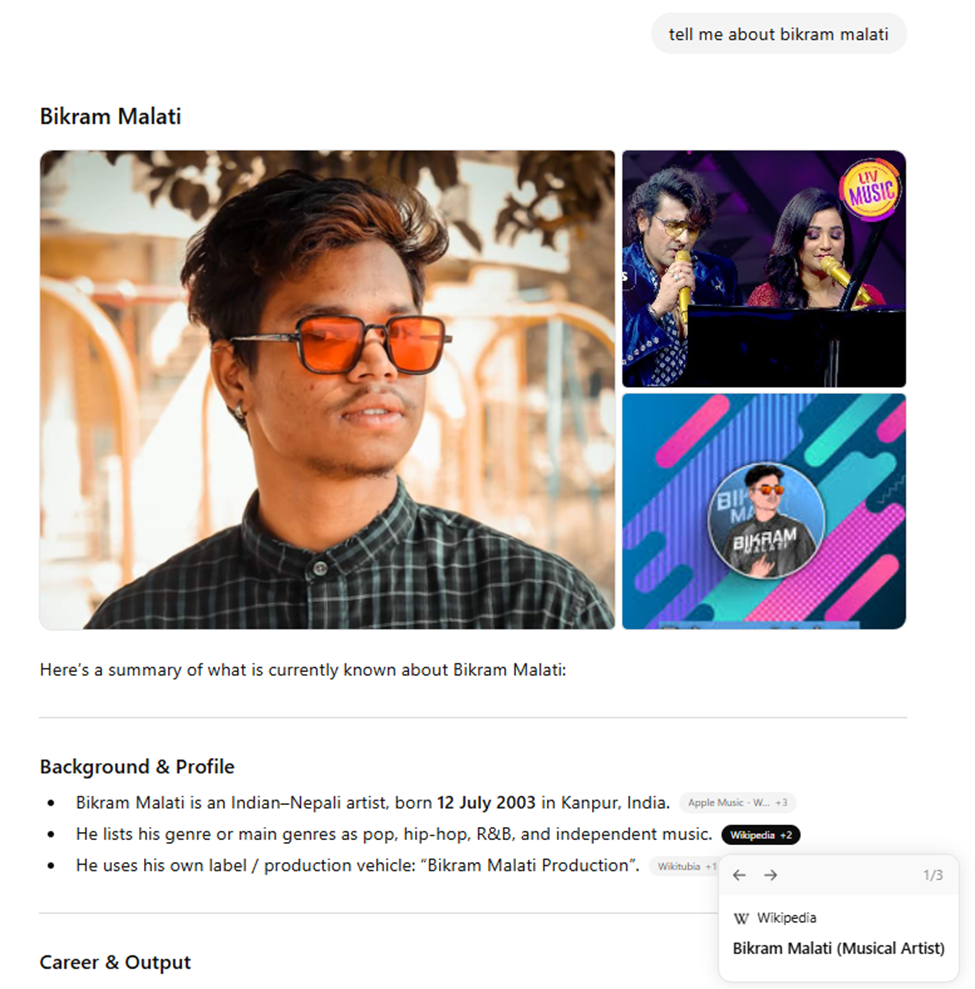
When you click on the link from ChatGPT, you get:
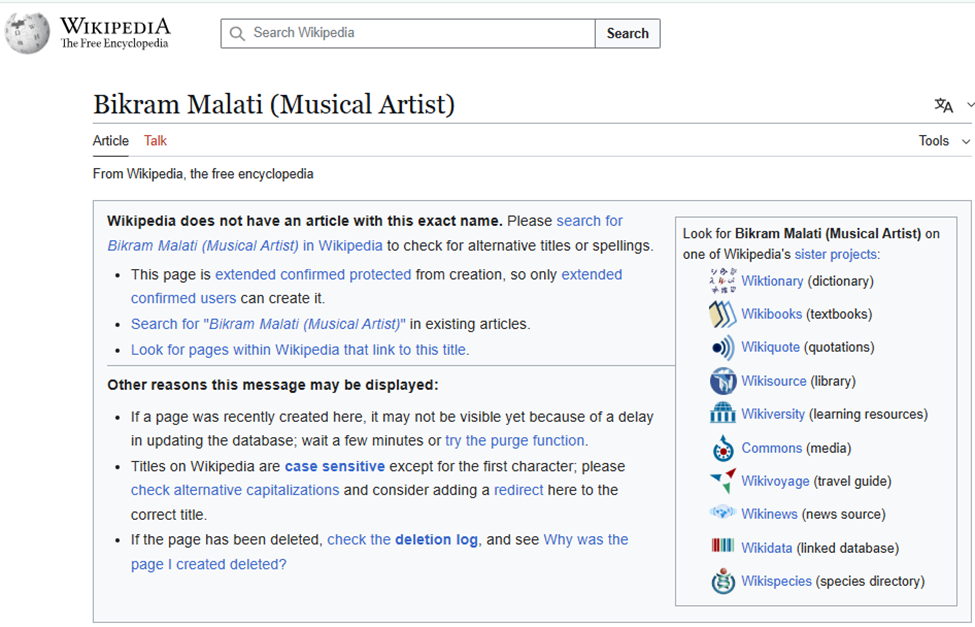
And, here you can see that the Wikipedia article was deleted on May 19th:
![]()
2. The Indexing Debate: Google, Bing… or Something Else?
There’s been a lot of discussion online about whether ChatGPT (and similar tools) rely on Google’s or Bing’s index to answer questions about current topics.
Microsoft has described Bing as ChatGPT’s “search partner,” suggesting that when the model browses the web in real time, it’s doing so through Bing’s infrastructure. Others assume that since Google dominates the indexing landscape, much of the information must come from its dataset.
Our finding suggests a third possibility.
AI systems like ChatGPT don’t just rely on live search indices — they also draw on their own internal knowledge, built from snapshots of the web taken during training. That means they may reference pages that have since disappeared, been updated, or were never fully visible to search engines at all.
For example, here ChatGPT cites the HMS Totnes Wikipedia page:
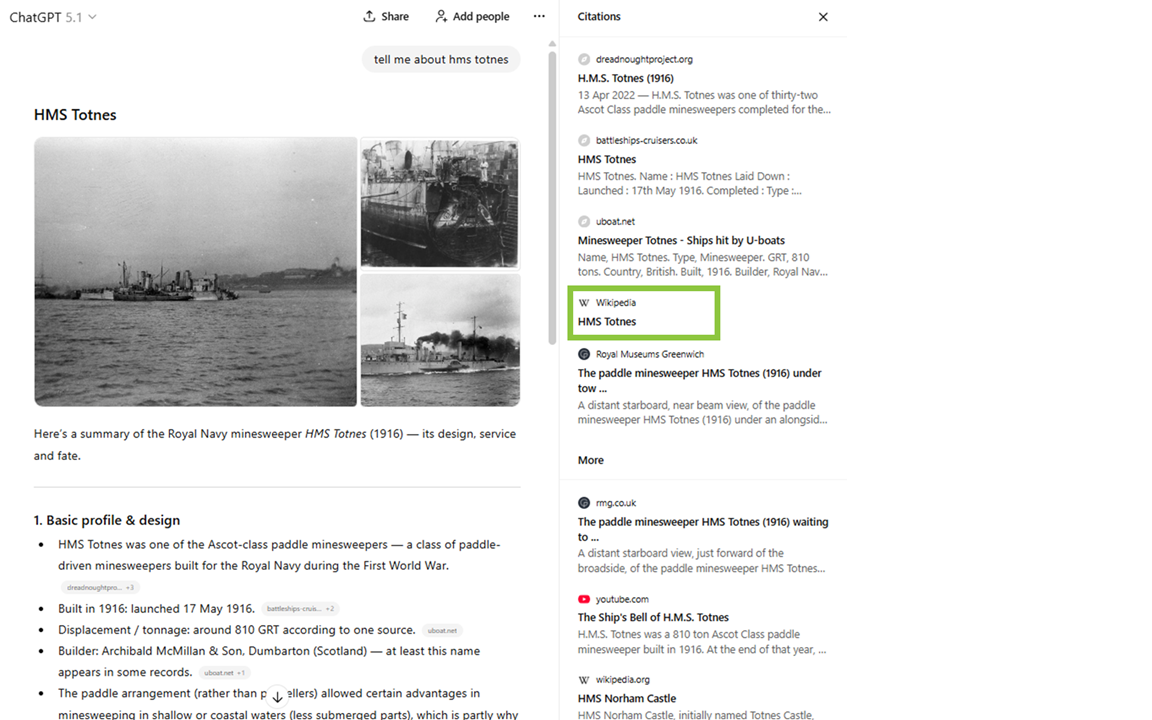
However, a Google search for that Wikipedia page shows that it hasn’t been indexed:
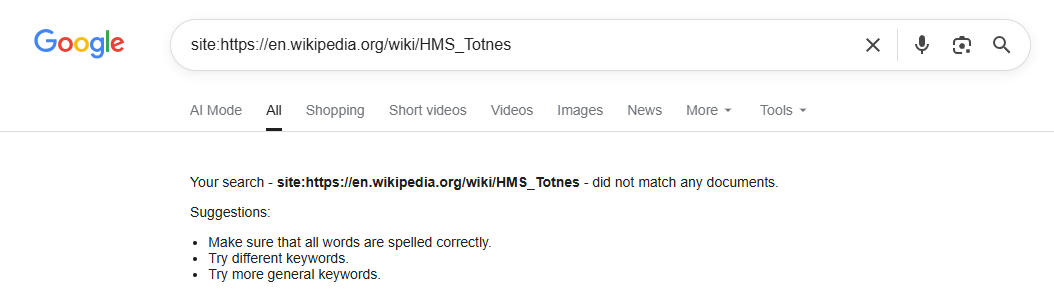
Unlike Google or Bing, which are constantly re-indexing the live web, AI models often retain information indefinitely. They may “remember” content that was once public but has long since vanished — effectively creating a parallel version of the internet that exists only inside the model.
This raises a fascinating question:
If AI can access and resurface information that’s been deleted or de-indexed, what does “control” over your online reputation really mean?
3. The Reputation Implications
For years, Wikipedia has been one of the most powerful determinants of how brands and individuals appear online. It influences Google Knowledge Panels, affects trust signals, and often shapes media narratives.
Because of that, many organizations have worked diligently to ensure that their Wikipedia entries are accurate, balanced, and aligned with verifiable facts. But the assumption has always been: once an error is corrected or a page is deleted, the outdated version fades from public view. In the age of AI, that’s no longer guaranteed.
If ChatGPT or another AI system has already learned from a previous version of a Wikipedia page, that information may continue to influence its responses — even if the page no longer exists. This creates a temporal lag between what’s true now and what AI believes to be true, based on past data.
That lag can have real consequences:
- A company that successfully removes an inaccurate Wikipedia claim may still see it resurface in AI summaries.
- An individual whose biography was corrected might find outdated information repeated in generative search results.
- A brand that relies on Wikipedia for credibility could see outdated or partial content influencing how AI describes it to users.
This represents a profound shift in the mechanics of reputation. Reputation is no longer defined solely by what’s visible online — it’s also shaped by what AI remembers.
This raises an important question: if outdated Wikipedia content can continue to surface in AI responses, is there still value in correcting or deleting a page? The answer is yes — but with new strategic considerations. When an updated version of a page is published, AI systems that re-crawl or refresh their training data are more likely to replace older information with the corrected version. And even if outdated details aren’t fully overwritten everywhere, ensuring that accurate, high-quality content exists increases the probability that AI models will surface the correct version in most contexts. In other words, maintaining an accurate Wikipedia presence still matters — it just operates within a more complex, probabilistic AI ecosystem.
4. Managing Reputation in the Age of AI Memory
So, what should brands and communicators do in this new landscape?
First, recognize that deletion isn’t disappearance.
Once information has entered the public digital ecosystem — especially on high-visibility platforms like Wikipedia — it may continue to circulate in AI models long after being removed. That makes proactive accuracy and clarity even more important. Fixing misinformation quickly reduces the risk that it becomes “baked in” to an AI’s memory.
Second, expand your visibility monitoring beyond search.
Traditional SEO and reputation tools focus on what appears in Google results. But as AI platforms like ChatGPT, Perplexity, and Google’s own AI Overviews become more popular, brands need to track how they’re represented there, too. Five Blocks’ AIQ Snapshot, for example, measures how companies appear across leading AI platforms — providing early warning when narratives diverge from reality.
Third, view Wikipedia through an AI lens.
Wikipedia remains one of the most influential data sources in the world — not just for humans, but for machines. Maintaining accuracy, neutrality, and completeness there matters more than ever, because what’s written (or once written) can echo through AI systems long after.
Finally, stay vigilant about every change that happens on your Wikipedia pages.
Even small edits — a phrasing shift, a new citation, an added controversy — can ripple into AI systems that use Wikipedia as a core reference. That makes real-time monitoring essential. Tools like Five Blocks’ WikiAlerts™ notify brands the moment a page is edited, enabling rapid review and response before inaccurate or biased information spreads or becomes part of an AI model’s reference set. In the age of AI memory, staying updated isn’t just good Wikipedia hygiene — it’s a critical layer of reputation protection.
5. The Takeaway: Reputation in a Post-Search World
The discovery that ChatGPT can cite deleted or unindexed Wikipedia pages is more than a technical curiosity. It’s a signal that we’re entering a post-search era — one where visibility and influence extend beyond the reach of traditional SEO and content control.
Search engines like Google and Bing show us what’s out there today. AI models, in contrast, reveal what’s still in there — the accumulated memory of the internet, with all its imperfections, edits, and ghosts of pages past.
For communicators and reputation professionals, this is both a challenge and an opportunity. It’s a reminder that reputation isn’t static, and it isn’t limited to what’s live. It’s a living narrative, shaped by both current content and the digital traces left behind.
At Five Blocks, we believe the next chapter of reputation management lies in understanding and influencing that AI layer — ensuring that when machines summarize who you are, they get the story right.
Curious whether ChatGPT is pulling from non-indexed or deleted pages that could be influencing your brand narrative? Get an AIQ Snapshot now!