Google Serves Up a Fail for Waffle House
I’m not from the South and have never been to a Waffle House. So, without ever having given it too much thought, I could only imagine that eating there is probably fairly similar to any other fast food experience. Today, though, I had occasion to search for Waffle House on Google. Based on their search results, with all due respect to customers of Waffle House, I have learned that Waffle House seems to be a magnet for the lowest class of society. Highlights from their search page include:
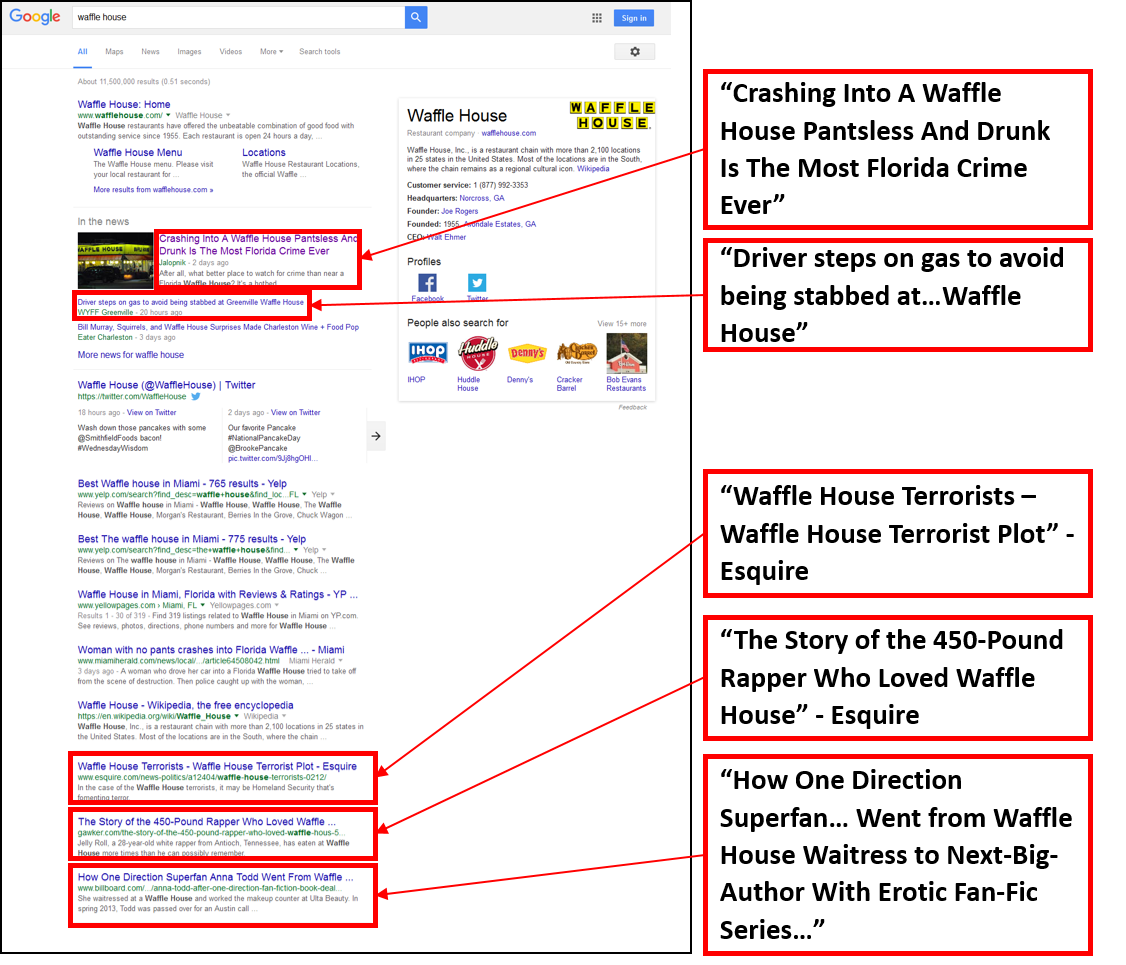
As an SEO researcher, I am particularly intrigued by the in-depth articles Google’s algorithm selected for inclusion here. In-depth articles often appear in search results for a known entity, such as a person, company, brand, or concept. They appear as a group of three articles and are typically long form journalistic coverage of the searched term. Often, their coverage has a negative slant. For example, one of Apple’s in-depth articles is “iPhone Killer: The Secret History of the Apple Watch.” For Uber, we find “The Inside Story of Uber’s Radical Rebranding.”
But these in-depth articles aren’t about Waffle House at all. They are stories about people, some crazy people, whose lives happened to intersect with Waffle House. Is that really what people searching for Waffle House are interested in finding? More than anything, they create a highly unfavorable impression of Waffle House, even though these stories have little to do with the brand itself.
Yes, these articles all mention Waffle House and yes, they are all long form journalistic coverage. In that sense, Google’s algorithm got it right. But I think nature abhors a vacuum and Google abhors one even more. In the absence of any other in-depth article-worthy coverage of Waffle House itself – positive or negative – Google’s algorithm scraped the bottom of the barrel and came up with these.
Ultimately this is one big fail for Google’s algorithm that leads to an even bigger fail for the Waffle House brand. Google is probably the best place to go when you want to size up an individual, company or brand. You are quickly exposed to a variety of sources and types of information: corporate website, social media, news, YouTube, Wikipedia etc. But when Google gets it wrong – as they do in this Waffle House example – the cost can be very high for the brand, with stakeholders getting a negative and undeserved impression of the brand.