Digital Reputation Management
Reputation is no longer a media problem. It’s an infrastructure problem.
What Google and AI say about your brand is your reputation. We manage it.

For most of the last two decades, “reputation” lived inside the communications function. A CCO managed the narrative through earned media, owned channels, and relationships with reporters. The story was the product.
That world still exists. But it now runs on top of a second, deeper layer – one that determines whether the story actually reaches anyone.
When a board member, a regulator, an LP, a journalist, a recruit, or a customer wants to understand a company or an executive, they do not start with a press release.
They typically start with Google, and increasingly, they are moving to ChatGPT, Gemini, Claude, Perplexity, or Copilot. What those systems return – the ten blue links, the knowledge panel, the AI-generated summary – is the reputation. Everything else is upstream of it.
Most PR firms are not built to manage that layer. We are. It is the only thing we do, and we have been doing it since 2003.
What “Digital Reputation Management” actually means at Five Blocks
The phrase gets used loosely. In our work, it has a precise meaning: the disciplined, ongoing management of every signal that Google and AI models use to construct a picture of a brand or an individual.
That includes, at minimum:
- Google search results for branded and reputational queries – the first three pages, every SERP feature (knowledge panel, People Also Ask, Top Stories, AI Overviews, sitelinks), and how they shift over time.
- AI-generated narratives in ChatGPT, Gemini, Claude, Perplexity, Copilot, Grok, and Google’s AI Mode – what the model says, which sources it draws from, and how the story compares to peers.
- Wikipedia – the single most influential third-party source on the open web, cited heavily by AI models and surfaced prominently in Google.
- Knowledge graphs and entity signals – Wikidata, Crunchbase, schema markup, structured data, and the dozens of signals that tell machines who a company or person is.
- Owned content – corporate sites, executive bios, FAQ pages, leadership content – structured to be readable by both humans and AI.
- Earned and third-party content – the press, directories, and reference sites that AI treats as authoritative.
Each of these is a discipline. Most firms work in one or two of them. We work in all of them, in-house, and we treat them as a single connected system – because that is how Google and AI treat them.
Why this is different from PR, SEO, or traditional ORM
We get asked this constantly, so it is worth being direct.
We are not a PR firm. We do not pitch reporters, place stories, or manage media relationships. We work alongside the firms that do – including most of the major strategic communications and IR firms in New York, London, and globally. They handle narrative and media. We handle the technical and content infrastructure that determines whether that narrative actually reaches people through Google and AI.
We are not an SEO agency. Traditional SEO optimizes for traffic and conversion – keywords, backlinks, technical performance. Reputation work optimizes for what specific people see when they search a specific name or brand. Different goals, different toolkit, different success metric.
We are not a traditional ORM or “suppression” firm. Most firms in that category fight the algorithm – they build networks of low-quality content, spin up profiles, and try to push negative results down through volume. The work is brittle, often unethical, and increasingly ineffective as Google and AI get better at recognizing manipulation.
We do the opposite. We work with the platforms – studying how Google ranks, how AI models source their answers, what Wikipedia accepts as credible – and we curate a client’s broader digital presence so that the preferred narrative is the one those systems naturally elevate. The work is durable because it is built on the same logic the platforms themselves use.
Our approach
Every engagement starts with the same conviction: you cannot manage what you have not measured, and you cannot fix what you do not understand.
1. We lead with data
Before we recommend anything, we audit. Across Google search results for every reputational query that matters, across all major AI models, across Wikipedia and Wikidata, across knowledge panels and structured data, across third-party citations. We map the full landscape – what is there, where it is coming from, and why the systems are surfacing it.
This produces two things our clients consistently tell us they cannot get elsewhere: a clear, evidence-based picture of the actual problem, and an internal alignment tool that gets stakeholders to agree on what to do.
Our proprietary platforms make this possible at depth:
- IMPACT™ tracks Google search results daily across tens of thousands of queries for every client. We have monitored more than 100,000 brand search footprints over the platform’s history. Clients see, in real time, which results dominate, how rankings shift, and where the leverage points are.
- AIQ is the only platform of its kind built specifically to monitor AI narratives. It tracks how ChatGPT, Gemini, Claude, Copilot, Perplexity, and Grok describe a brand – sentiment, sources cited, peer comparisons, narrative drift over time. Continuously updated.
- WikiAlerts monitors every relevant Wikipedia page and edit, in real time, across all language editions.
- GeoSearch tracks how results shift across geographies – critical for multinationals and for executives whose stakeholders are spread across markets.
2. We work every layer that matters, in-house
Five Blocks does not outsource. Every piece of work, Wikipedia research and editing, technical structured data implementation, AI content strategy, owned content development, entity optimization, is executed by our own team, in our offices in New York and Jerusalem.
Our staff averages well over a decade of experience in digital reputation. We have 10+ people dedicated exclusively to Wikipedia, with a depth of platform knowledge that is not matched anywhere in the industry. Our turnover is low. The senior practitioner assigned to a client in month one is the same one accountable in month twelve.
This matters because reputation work, done correctly, is highly contextual. There is no playbook that substitutes for someone who knows the case, the industry, the personalities, and the platforms intimately. We build that institutional knowledge inside the engagement, and we keep it there.
3. We use peer analysis as a methodology, not a sales pitch
One of our operating principles: do not reinvent the wheel. In every engagement, we study what is working for a client’s peers and competitors – which content AI models are citing, which Wikipedia structures are most defensible, which third-party sources are driving positive narratives, which owned content is breaking through.
Our AIQ platform makes this systematic. We can tell a client, with data, which sources are shaping how they are described in ChatGPT versus how a peer is described – and what to do about the gap. It accelerates results and grounds every recommendation in what is actually working in that competitive context.
4. We build for durability, not for the dashboard
There is a temptation in this industry to optimize for what looks good in a monthly report. We optimize for what holds up six, twelve, twenty-four months out – through algorithm changes, news cycles, and the rapid evolution of AI models.
That means investing in the structural assets that compound: a strong Wikipedia presence, well-architected owned content, accurate entity data, durable third-party citations. The work is slower than vanity tactics. It is also why our client relationships average many years.
What ongoing digital reputation management looks like
Most of our engagements are not crisis work. They are ongoing programs designed to keep a brand or an executive in a strong position – so that when something does happen, the foundation is already there.
A typical program includes:
Continuous monitoring. IMPACT™ and AIQ run daily. Clients have real-time visibility into where they stand in Google and across AI models. Anomalies, ranking shifts, narrative drift, new negative content – we see it as it happens, often before the client does.
Active curation of search results. We work the queries that matter, branded searches, executive names, reputational queries, industry-specific terms – and we manage what surfaces on them. That means strengthening preferred content, building new assets where gaps exist, and addressing problematic results through the structural levers that actually move rankings.
Wikipedia stewardship. For clients with Wikipedia presence (or who should have one), we manage notability, accuracy, sourcing, and the ongoing editorial process – transparently, with disclosed conflict-of-interest editing per Wikipedia’s terms of service. For clients without a Wikipedia page, we assess whether one is appropriate and, if so, build it correctly the first time.
AI narrative management. We monitor how each major AI model describes the client, identify the sources driving the narrative, and shape those sources – corporate site content, Wikipedia, earned media, structured data – so that the AI-generated story is accurate, complete, and favorable. This is the newest discipline in reputation, and the one most firms have not figured out.
Entity optimization. Wikidata entries, Google Knowledge Graph signals, schema markup on the corporate site, executive entity hygiene across the open web. The unglamorous infrastructure that determines whether AI and search engines correctly understand who the client is.
Owned content development and optimization. We help clients build the kind of content, executive bios, leadership pages, FAQ structures, thought leadership architecture, that performs in both human search and AI synthesis. Often this is the highest-leverage work we do.
Reporting and review. Formal monthly reports, weekly check-ins where appropriate, ad-hoc updates as activity warrants, and continuous platform access through IMPACT™ and AIQ. Clients are never guessing where they stand.
How we work with PR and communications partners
The majority of our engagements involve a PR or strategic communications firm working alongside us. That is by design. PR teams shape narrative; we shape the infrastructure that determines whether the narrative is what people actually find.
In practice this looks like:
- Joint stakeholder mapping. Comms identifies the audiences and moments that matter; we identify the queries, platforms, and signals that audience will actually encounter.
- Coordinated content strategy. When the comms team places earned media, we ensure the placements are structured to be discoverable and citable by AI. When we recommend owned content, the comms team owns voice and message; we own architecture and discoverability.
- Crisis preparation, not just response. We map vulnerabilities before they become incidents, exposed search queries, weak entity data, Wikipedia risk, AI narrative gaps – and the PR partner builds the messaging playbook against that map.
- Clear lines. No turf wars. We do not pitch reporters; PR partners do not edit Wikipedia. The collaboration works because the disciplines do not overlap.
Why this matters now
Two things have changed in the last twenty-four months.
First, AI-generated answers are rapidly replacing the search query as the primary way people get information about brands and individuals. The narrative those models produce is built from a specific set of sources – Wikipedia, corporate websites, earned media, structured data – and it is being formed right now, whether the subject is paying attention or not.
Second, the cost of getting it wrong has gone up. A flawed AI summary that gets cited by a journalist, repeated by an analyst, or surfaced to a board member becomes the working version of the story. Correcting it after the fact is far harder than shaping it correctly in the first place.
Five Blocks has spent twenty-plus years working on exactly the building blocks AI models now read. We were doing this work before AI made it urgent. The firms that figure out the AI layer will be the firms that already understood the search and Wikipedia layers – because they are the same problem, in a new wrapper.
Frequently Asked Questions
How is Five Blocks different from a traditional ORM or “suppression” firm? Traditional ORM fights the algorithm – building low-quality content networks to push results down. We work with the platforms. We study how Google and AI models source and prioritize content, and we curate a client’s broader digital presence so the preferred narrative is the one those systems naturally surface. The work is durable because it is built on the same logic the platforms use.
How is Five Blocks different from a PR firm doing digital reputation? PR firms manage narrative and media relationships. We manage the technical and content infrastructure that determines what Google and AI actually return. Different skills, different tools, different success metric. Most major PR firms partner with us rather than compete with us.
Do you outsource any work? No. All Five Blocks work is done in-house, by our team. No white-label vendors, no offshore execution.
How long do engagements typically last? Most clients work with us on an ongoing basis. Reputation infrastructure is not a one-time project – search results shift, AI models evolve, news cycles change, executives transition. Programs are designed to maintain and strengthen the foundation over time. Crisis-only engagements are usually two to six months; broader programs run for years.
Can Five Blocks actually change what AI models say about a client? Yes – through structural means. We improve the sources AI models read: Wikipedia, corporate website content, earned media, entity signals. When those sources improve, the AI-generated narrative improves. Our AIQ platform measures the change directly. This is not a workaround; it is how AI reputation management works.
Does Five Blocks remove negative content? Where it is possible and appropriate, yes – through direct outreach, factual correction requests, legal angles where they exist, and in some cases acquiring defunct sites that host defamatory content. Removal is not always feasible, which is why our broader methodology focuses on shaping what surfaces in Google and AI regardless of whether any individual piece comes down.
How do you report to clients? Formal monthly reports, weekly check-ins where the engagement warrants, ad-hoc updates as activity requires, and continuous real-time access to IMPACT™ (search) and AIQ (AI). Clients are never guessing where they stand.
Do you work confidentially through PR partners? Yes. Many of our engagements run through strategic communications and PR firms. We also work directly with end-clients. Either model is standard.
How much does an engagement cost? Programs are structured as monthly retainers, scoped to the work required. Crisis engagements typically run $15,000 to $30,000 per month. Ongoing programs vary based on scale – a single executive looks different from a multi-brand corporate mandate. We will scope and price transparently after an initial audit.
Do you work outside the United States? Yes. We work across many languages and geographies.
Is the work confidential? Always. No exceptions.
Where to start
The right entry point for almost every prospective client is the same: a Digital Brand Audit. It is fast, it is concrete, and it produces a clear, evidence-based picture of where the client stands across Google, AI models, Wikipedia, and entity signals – along with a prioritized roadmap for what to do about it.
For active situations, we begin a crisis engagement within 24 to 48 hours.
For ongoing programs, we typically scope, audit, and launch within two to three weeks of engagement.
Contact us to discuss your situation – whether you are evaluating partners, building defenses before a crisis, or already in one.
Reputation Crisis Management
Why Five Blocks – and Why It’s the Right Choice for Reputation Crisis
When reputation is on the line, the firm you choose matters more than ever.

Most digital reputation crises share the same fatal flaw: the response comes too late, goes too shallow, or fixes the wrong layer. At Five Blocks, we’ve spent over two decades building a methodology that works precisely because it doesn’t treat a crisis as a moment – it treats it as a system.
Here’s why brands and individuals consistently choose Five Blocks when the stakes are highest.
We Move Fast – Without Cutting Corners
Crisis reputation work demands both speed and substance. Those are usually in tension. At Five Blocks, we’ve solved for both.
Our first move in any crisis engagement is triage: identifying which elements of a client’s digital presence can be improved immediately – owned content updates, structured data corrections, knowledge panel claims, entity signals – and which require a longer runway. We call this our two-pronged approach: pain relief plus permanent repair.
The quick wins are real. We can often move the needle on owned and controlled content within days. But we never stop there. While the client is getting near-term relief, our team is simultaneously working the harder, more durable problems – the ones that will determine how that person or brand looks in Google and in AI-generated responses six months from now.
Everything Starts With Data
The hardest part of managing a brand through a crisis isn’t the execution – it’s getting the client to understand what actually needs to be done.
At Five Blocks, we lead with analysis. Every engagement begins with a comprehensive audit of how a client appears across Google search, AI models (ChatGPT, Claude, Gemini, Perplexity, Copilot, Grok, AI Mode, and AI Overview), Wikipedia, knowledge graphs, and third-party citations. We map the full landscape before we touch a single thing.
This matters for two reasons. First, it gives clients a clear, evidence-based picture of the problem – which builds alignment and gets decisions made faster. Second, it ensures our solutions address root causes, not symptoms. Surface-level fixes collapse under pressure. Structural ones hold.
Our proprietary platforms make this possible at a level of depth most firms can’t match:
IMPACT™
IMPACT™ tracks Google search results daily across tens of thousands of queries, giving clients real-time visibility into which results dominate their brand, name, or other query, and how they shift over time.
AIQ
AIQ monitors how AI models describe a brand across all major platforms – sentiment, source citations, peer comparisons – updated continuously. It is the only tool of its kind built specifically for AI narrative management.
Bespoke Work. In-House. Every Time.
Five Blocks does not outsource. Every piece of work – from Wikipedia research and editing to technical structured data implementation to AI content strategy – is done by our team, all in-house.
This is not an operational detail. It is a quality guarantee.
Our staff averages well over a decade of experience in digital reputation. We have 10+ people dedicated exclusively to Wikipedia, with a depth of knowledge of that platform that is unmatched in the industry. We have low turnover. The person who starts on a client’s account in month one is still there in month six – and they know the case intimately.
In a crisis, continuity and expertise are everything. You cannot afford to have your case managed by a junior associate reading from a playbook. At Five Blocks, senior practitioners are hands-on throughout.
We Work Across Every Layer That Matters
Digital reputation today is not a single channel. It is a system – and in a crisis, every layer of that system gets stress-tested simultaneously.
Five Blocks has deep expertise across all of them:
Google Search
We know how to identify which results are driving reputational harm, how to move positive content up, and how to push damaging results down through content strategy, entity optimization, and technical signals. Our IMPACT™ platform has tracked over 100,000 brand search footprints.
Wikipedia
One of the most powerful – and most misunderstood – platforms in digital reputation. Wikipedia content is cited directly by AI models and influences knowledge panels across Google. We work transparently and ethically within Wikipedia’s policies, disclosing our role as required. Our 13-person Wikipedia team handles everything from notability assessments to complex editorial negotiations.
AI and LLM Narratives
This is the frontier of reputation management, and it is where Five Blocks has invested deeply. AI models like ChatGPT and Claude synthesize a narrative about every brand and individual from the sources they can access – primarily Wikipedia, corporate websites, earned media, and third-party directories. We know how to shape those sources so that the narrative AI builds is accurate, complete, and favorable. Our AIQ platform measures this precisely.
Entity Signals and Structured Data
Wikidata, Crunchbase, Google’s Knowledge Graph, schema markup on corporate websites – these are the underlying signals that AI and search engines use to understand who a person or company is. We have experts who work in all of these environments.
Owned Content
In a crisis, a client’s own website becomes a critical reputation asset. We help clients build content that is structured for both human readers and AI models – detailed, well-sourced, and optimized to become a primary citation source.
We Know How AI Models Think About Your Brand
This is the capability that most reputation firms do not yet have – and it matters more every month.
When someone searches for a brand, an executive, or a company in ChatGPT, Claude, Gemini, or Copilot, the AI constructs a narrative. That narrative is synthesized from what it has read across the web – and it is often incomplete, outdated, or shaped by negative sources the client doesn’t even know exist.
We call this Synthesized Reputation – the AI’s version of who you are, built from the same building blocks that have always mattered in digital reputation: earned media, owned content, Wikipedia, and entity signals. Five Blocks has spent 20 years working on exactly these building blocks. We were doing this work before AI made it urgent.
Our AIQ platform gives clients a real-time window into their AI reputation – how they are described, what sources AI is drawing from, how they compare to peers in the same industry. No other firm offers this at scale.
Peer Analysis Is Built Into Our Methodology
One of our core operating principles: don’t reinvent the wheel.
In every engagement, we analyze what is working for clients’ peers and competitors – which content is getting cited by AI models, which sources are driving positive narratives, which Wikipedia structures are most effective. If something is working, we learn from it. This peer analysis approach, powered by AIQ, accelerates results and ensures our recommendations are grounded in what is actually effective in that industry and competitive context.
Industries and Audiences We Serve
Five Blocks works with Fortune 500 companies, PR firms, hedge funds, private equity firms, insurance companies, banks, pharmaceutical companies, energy companies, higher education institutions, and high-net-worth individuals – including some of the most recognized names in business and public life.
We understand that a pharmaceutical company in the middle of an FDA controversy has different needs than a hedge fund manager dealing with adverse press. We tailor every engagement to the specific context, industry, and stakeholder environment.
What a Five Blocks Crisis Engagement Looks Like
Rapid Audit: Within 48 hours, we deliver a prioritized map of where the reputational damage exists across Google, AI models, Wikipedia, and entity signals.
Triage and Quick Wins: We identify what can be corrected or improved immediately and begin execution.
Strategic Roadmap: We build a structured 90-day plan that addresses both near-term relief and long-term durability.
Continuous Monitoring: IMPACT™ and AIQ track progress daily. Clients always know where they stand.
Senior Oversight Throughout: A senior practitioner is accountable for the engagement from day one through completion.
Frequently Asked Questions
How quickly can Five Blocks respond to a crisis situation?
We can begin a crisis engagement within 24-48 hours of engagement. Our team is structured for rapid mobilization, and we have dedicated capacity for crisis work.
Does Five Blocks work with individuals as well as companies?
Yes. We work with high-net-worth individuals, executives, public figures, and celebrities alongside corporate clients. Individual reputation management has its own specialized methodology, and we have deep experience in it.
What makes Five Blocks different from a general PR firm handling digital reputation?
General PR firms typically manage media relationships. Five Blocks manages the technical and content infrastructure that determines what the internet – and AI – says about you. These are different skills, different tools, and different expertise. Most PR firms partner with us rather than compete with us.
Can Five Blocks actually change what AI models say about a client?
Yes – through legitimate, structural means. We improve the underlying sources that AI models read: corporate website content, Wikipedia, earned media citations, entity signals. When those sources improve, AI-generated narratives improve. This is not a hack or a workaround. It is how AI reputation management works.
Do you outsource any of your work?
No. All Five Blocks work is done in-house by our team. We do not use white-label vendors or offshore execution.
How much does a Five Blocks crisis engagement cost?
Crisis engagements are structured as monthly retainers, typically ranging from $15,000 to $30,000 per month depending on scope and resourcing. Some situations resolve in one to two months; engagements involving larger companies or sustained news cycles often run six months or longer. Fees are tied directly to the scope of the work and the resources required to execute it.
How quickly will we see measurable results?
In most engagements, we see measurable impact within the first one to two weeks, with significant improvements over the course of two to three months. Full programs can run longer because the goal is not a band-aid – it is a durable, long-term solution that holds up after the immediate crisis subsides.
What types of crises does Five Blocks handle?
We work on crisis situations for both brands and individuals. On the brand side, this includes transactions, poor earnings, safety concerns, product recalls, negative product reviews, and broader industry-related issues. For individuals, we handle negative press, defamation, and other reputation challenges that surface in search and AI results.
Does Five Blocks remove negative content from the internet?
Whenever it is possible and appropriate, yes. We pursue removals through direct outreach to site owners, factual correction requests, and – in cases where a defunct site is hosting defamatory content – we have even purchased sites and blogs on behalf of clients. Where a legal angle exists, we advise clients on how to use it. Removal is not always feasible, which is why our broader methodology focuses on shaping what surfaces in Google and AI results regardless.
Yes. All of our work is confidential, without exception.
How does Five Blocks report progress to clients?
Clients receive formal progress reports on a monthly cadence, supplemented by weekly and ad-hoc updates as activities and developments occur. IMPACT™ and AIQ provide continuous, real-time visibility into Google search results and AI narratives, so clients always have a current picture of where they stand.
How is Five Blocks different from traditional ORM or suppression firms?
Traditional ORM firms tend to fight the algorithm. We work with the platforms. Our team understands where Google and AI models source their content and how they prioritize it, and we help clients ensure that their preferred narrative, stories, and links are seen and prioritized within those systems. We work hand-in-hand with clients’ CCOs and PR teams to curate that narrative – not against the algorithm or AI logic, but in alignment with how it actually works.
Do you work with clients outside the United States?
Yes. We work across many languages and countries, including French, German, Spanish, Italian, Japanese, and others. Our international offices give us native depth in multiple markets, and our methodology adapts to the search and AI ecosystems clients face in their specific geographies.
What happens after a crisis engagement ends?
It depends on the client. In some cases, once the crisis is resolved, no further work is needed. For companies and organizations with ongoing news cycles – where the same stories can resurface – we offer ongoing maintenance programs to keep the preferred narrative durable over time.
Can Five Blocks move existing negative results off page one of Google?
Yes – and we do it primarily by curating a client’s broader online presence rather than by attacking the negative results directly. That means making preferred content robust, readable by Google and AI models, and optimized to surface. We study what is working for peers, and we seize every opportunity available – website changes, new profiles, video content, images, FAQs, articles on third-party sites, earned media. PR and comms do their work; we do the technical, structural, and content optimization work hands-on, and the two together move the results.
Ready to talk? Contact us to discuss your situation – whether you are in an active crisis or building defenses before one arrives.
Google: Facing the Music
The following is a quick study of the fascinating dynamics behind search page results. Most people don’t think too much about the complex nature of how Google arrives at its results, but that’s exactly what we do here at Five Blocks.
A Wall Street Journal story last month accused Google of sourcing content without giving credit to the source. The article said Google had been scraping music lyrics from genius.com, a popular lyrics site.
Some quick background: When you search for the lyrics of a song, Google often shows the lyrics in what’s called a “rich snippet”.
What are Rich Snippets? you may ask.
Rich snippets are boxes that contain content clipped directly from a third-party web page. Google uses these rich snippets because it is the fastest way to get searchers the answer to their query.
Here is an example:
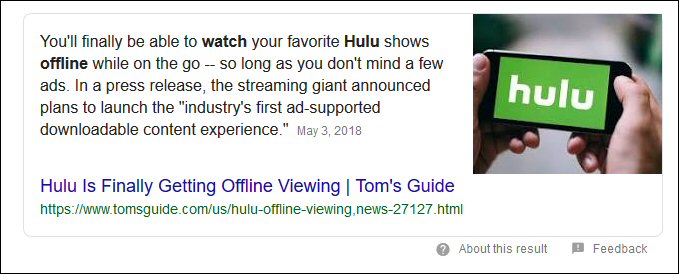
This is all fine as long as Google credits the source – and ideally provides a link to click.
However, in the case of song lyrics, Google seems to have provided the name of the artist, but not the website the lyrics came from – below is an image from before the WSJ story was published:
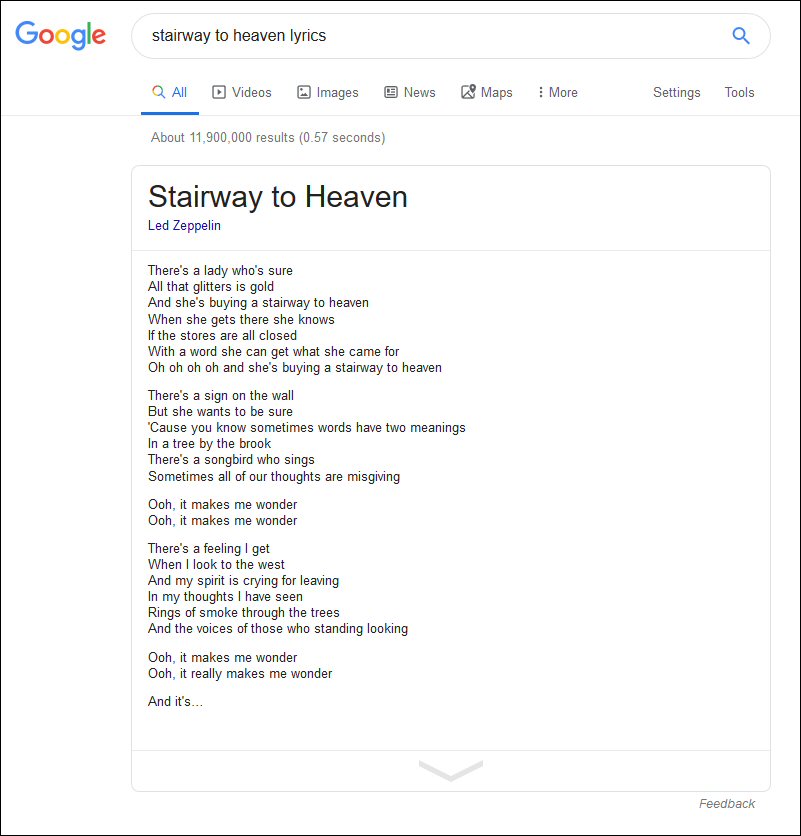
As you can imagine, song lyrics appear on lots of sites. So how could Genius.com be so sure that Google was scraping their site?
They ran a test. They embedded patterns of apostrophes in the formatting of song lyrics. If this pattern was replicated in the rich snippet in search results, it would prove that genius.com was the original source. They used two different types of apostrophes throughout the lyrics, as below (as seen in the WSJ.com article referenced above):
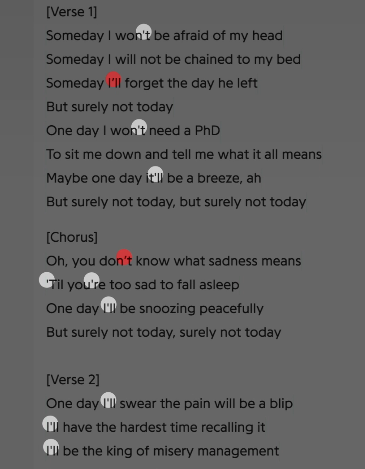
Genius checked the rich snippet, and found the apostrophe pattern replicated, proving the content came from their site.
But now the plot thickens — a development we became aware of after recently sharing this story with our partners.
The lyrics site LyricFind offered a rebuttal of the WSJ story, citing their licensing agreement with Google, and claiming that the content came from their site.
In fact, in the days following the publication of the WSJ story, Google began showing LyricFind as the source, and including a link.
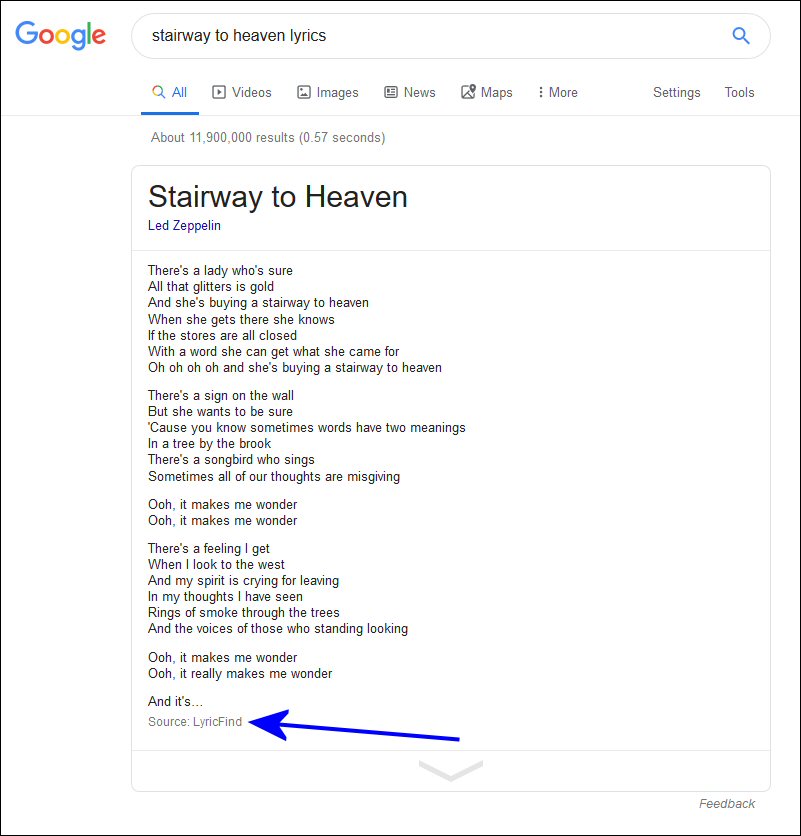
But what about Genius.com’s test? Here’s what LyricFind says:
“Some time ago…Genius notified LyricFind that they believed they were seeing Genius lyrics in LyricFind’s database. As a courtesy to Genius, our content team was instructed not to consult Genius as a source. Recently, Genius raised the issue again and provided a few examples. All of those examples were also available on many other lyric sites and services, raising the possibility that our team unknowingly sourced Genius lyrics from another location. [Italics ours. – YG]
As a result, LyricFind offered to remove any lyrics Genius felt had originated from them, even though we did not source them from Genius’ site. Genius declined to respond to that offer. Despite that, our team is currently investigating the content in our database and removing any lyrics that seem to have originated from Genius.”
In any event, it seems that Google, having implemented the change of crediting the source, has admitted that lyric sites, and not only artists, have certain rights — even if those are different than those held by the artist or publisher.
This episode is a reminder of how Google, with its complex automated systems that collect, process, categorize, and display information, needs to be closely monitored and managed.
In the same way that the system seems to have sourced content without proper attribution, that same mechanism often presents incorrect and damaging content about brands and individuals.
With so many stakeholders using Google to help them form opinions on people, companies, and issues, watching every detail related to Google’s top results is critical for your brand.
Another reminder that Intelligent Digital Reputation Management isn’t just “nice to have” — but an essential business strategy.
How Deep is Google’s Love?: Where the In-Depth Articles have Gone (and What it Means for You)
![]()
Recently, Google appears to have made a significant change to its search results page that eliminated several in-depth articles for many clients. We’ve taken a deeper dive into this development to see what it could mean for brands and high-profile individuals, and the PR professionals who work with them.
As you know, when searching for a brand or an individual, the Google search results page presents a variety of relevant content pieces and types of media to satisfy the query. Often this means a company’s own webpage will appear at the top, followed by third-party content such as Wikipedia and news sources. There may also be social media results (if an individual or brand actively maintains these platforms), along with image results or video content.
Several years ago, Google introduced a section within top search results they called “in-depth articles”. These results looked very similar to other search results, but came from longform media outlets like Variety, Rolling Stone, or The New York Times Magazine. Often, they were a seminal article about the brand in question – articles that may have been placed by their PR teams.
Including these articles on the top results page seems to have been Google’s way of ensuring that a greater variety (and deeper) content would appear in this prime spot. Their inclusion, and the actual articles that appeared within that section, were governed by a different set of algorithms than most search results.
Recently, this section disappeared from all search pages for brands and executives. This happened without any announcement or acknowledgment on the part of Google. It is important to note that in-depth articles for many brands and individuals contained negative content. At the same time, it was the place where particularly engaging longform journalism made its way onto the prime real estate of Google page 1 for a brand.
The ramifications of Google’s elimination of this section are yet to be seen, and their motivation can only be assumed to be “less intervention” following high profile criticism of potential bias in their algorithms.
A whole host of interesting questions arise from Google’s move: What is the corporate (and civic) responsibility of those who hold the world’s data in their hands? Are there cases for intervention? Who decides what those are?
It is interesting to note that alongside this mysterious disappearance, a recent Five Blocks study of CEO search results found there are far fewer news sites (sites such as CNN, CNBC, and others) on the first couple of pages of searches for a CEO compared to a year ago. In addition, those pages feature many more profile sites, where one would find more dry facts (often created by the brand), and less news.
This marked difference in the presence of news within the organic results over the course of the past year, alongside the recent removal of the in-depth article section, means that page 1 of search for brands and individuals will contain far more“owned” content – i.e.: information they control.
For some brands this would appear to be a positive turn of events, but for many this trend means they will not automatically have great media pieces (which they often earned by being genuinely great) appear prominently in searches. It means they will need to work harder to deliberately ensure that the best third-party media does in fact place highly within their profile. Savvy communications teams will find ways to enhance their brands’ online presence within these brave new parameters.
— Sam Michelson, with Sara K. Eisen
Five Blocks to Present at 2018 PRWeek “PRDecoded” Conference in Chicago – Thursday, October 18
 Curious to learn more about digital reputation management? Five Blocks will be in Chicago this week at the 2018 PR Week Conference. The conference promises to be a master class for communications pros in the ever-evolving digital world. Come hear from the best in the business and be sure to catch our CEO, Sam Michelson, speaking on Thursday, October 18 at 10:45 when he’ll share keys for cracking a digital reputation crisis. Don’t miss this informative and actionable conversation.
Curious to learn more about digital reputation management? Five Blocks will be in Chicago this week at the 2018 PR Week Conference. The conference promises to be a master class for communications pros in the ever-evolving digital world. Come hear from the best in the business and be sure to catch our CEO, Sam Michelson, speaking on Thursday, October 18 at 10:45 when he’ll share keys for cracking a digital reputation crisis. Don’t miss this informative and actionable conversation.
Our team will be at the conference all day and looks forward to seeing old friends and meeting new colleagues interested in discussing digital reputation management.