Unlocking Stakeholder Perception of your Brand Using Google Search Data and AI
Communications and PR professionals often rely on social media and earned media to gauge public perception of their brands or those of their clients. However, there’s a wealth of information hiding in plain sight that can provide even deeper insights into what people really think about your brand and your competitors: Google search results data.
By analyzing the search results for your brand and your competitors, you can uncover patterns of thought, and identify the questions and concerns that your stakeholders have. This is because Google’s algorithm depends on satisfying as many of the searchers as possible. This means that Google is already working to understand what people think and what they want to know. Tapping into this information can be invaluable in making decisions that shape your online presence and addressing potential challenges head-on.
One of the most prominent examples of AI in action on Google’s search results page is the People Also Ask feature. This section typically includes four questions and answers that Google deems most relevant to the search query. By examining these questions across multiple brands in your industry, you can gain a general understanding of what people are thinking and what they want to know about your brand and your competitors.
To demonstrate the power of this approach, we used Five Blocks IMPACT™, our tracking and analytics platform, to analyze the search results for several outdoor sportswear brands like North Face, Columbia, and Patagonia on March 31st in North America. We then used an AI to identify patterns in the People Also Ask sections and summarize how each brand is perceived, as well as any obvious challenges and potential lessons from their peers.
 The People Also Ask Questions and Answers collected automatically by Five Blocks IMPACT and then used for this analysis.
The People Also Ask Questions and Answers collected automatically by Five Blocks IMPACT and then used for this analysis.
The analysis revealed some surprising insights. For example, searchers seemed particularly concerned with where each company is based. But the AI went much further, characterizing how each brand is seen by stakeholders, based on the questions asked and providing recommendations for what they could learn from their competitors. While AI models can make mistakes, we found this to be a fascinating instantaneous analysis.
 A visualization of search results for various sportswear brands as seen in Five Blocks IMPACT and used for this analysis.
A visualization of search results for various sportswear brands as seen in Five Blocks IMPACT and used for this analysis.
Here are the conclusions that the AI model provided:
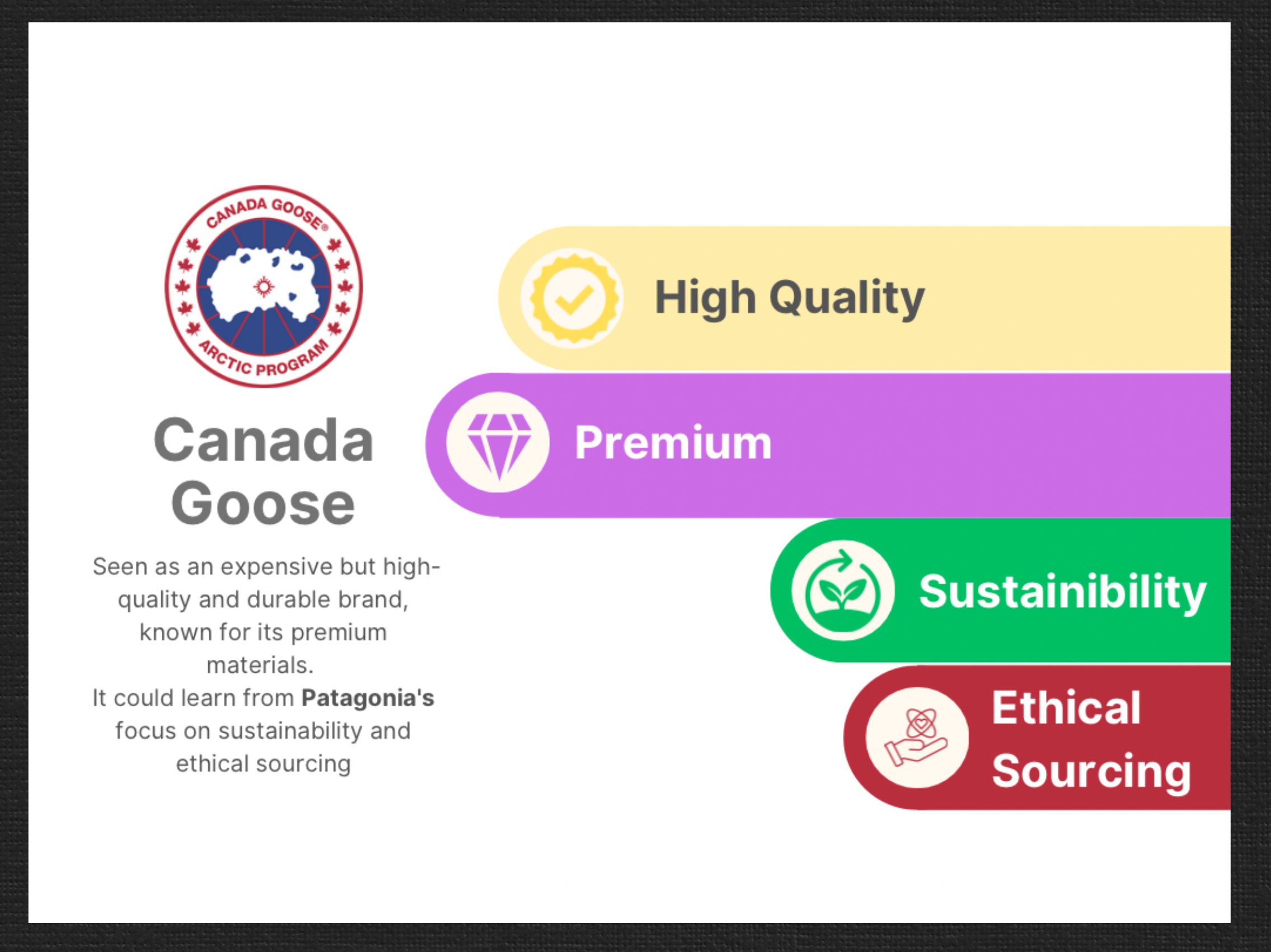
Canada Goose
- Seen as an expensive but high-quality and durable brand, known for its premium materials.
- Can learn from Patagonia’s focus on sustainability and ethical sourcing.
Arc’teryx
- Perceived as a popular and functional outdoor brand, with some questions around its Chinese ownership.
- Can learn from Canada Goose’s reputation for premium materials and durability, and from Patagonia’s environmental initiatives.
Burberry
- Firmly established as a luxury fashion brand, with questions about its history and store locations.
- Can learn from Arc’teryx’s technical expertise in outdoor apparel and from Patagonia’s commitment to sustainability.
Columbia Sportswear
- Seen as a good mid-range outdoor brand, often compared to The North Face.
- Can learn from Arc’teryx’s focus on technical performance and innovation, and from Patagonia’s sustainability efforts and brand purpose.
Moncler
- Perceived as a high-end luxury brand, known for its expensive but high-quality winter wear.
- Can learn from Patagonia’s transparency and ethical practices, and from Arc’teryx’s technical expertise in outdoor gear.
Patagonia
- Widely recognized for its sustainability efforts and commitment to environmental causes.
- Can learn from Canada Goose’s reputation for premium materials and durability, and from Arc’teryx’s technical innovation in outdoor apparel.
REI
- Seen as a reputable outdoor co-op.
- Can learn from Patagonia’s strong brand purpose and environmental initiatives, and from Arc’teryx’s technical expertise in outdoor gear.
The North Face
- Perceived as an expensive but high-quality outdoor brand, with some questions about its popularity and branding.
- Can learn from Patagonia’s sustainability efforts and brand purpose, and from Arc’teryx’s technical innovation in outdoor apparel.
Using only Google Results of peers, we can then paint a picture of how Google, and perhaps their searchers, see each brand.

A visualization of what we learned using this Data and AI analysis of the Google Results.
Using AI-powered search data analysis, brand and communications directors can identify areas where their brand’s image might not align with their goals and adjust their digital reputation management strategy accordingly. This data serves as a kind of insightful preliminary focus group, providing valuable insights that can be tracked over time.
In today’s fast-paced digital landscape, staying on top of how your brand is perceived is more important than ever. Leveraging the power of AI and search data analysis, you can uncover hidden insights, address potential challenges, and ensure that your brand is resonating with your target audiences.
Five Blocks specializes in digital reputation management, combining cutting-edge technology and personalized service to help our clients overcome digital reputation challenges. Our advanced data analysis and AI-powered insights allow us to identify the root causes of various issues and uncover overlooked opportunities for improvement. We work closely with your communications team to develop and implement sustainable solutions that deliver long-lasting results. For more information or to see what we can do with your brand’s data, contact us.
The Future of Wikipedia in the Age of AI
As the use of AI models increases, the way users seek information is evolving. Queries are becoming more complex and conversational, and results are typically based on a much larger body of data, rather than a specific source or page.
As these models become increasingly integrated into our daily lives, the importance of Wikipedia in shaping brand reputation cannot be overstated, since it is a major source for training AIs.
Importance of Wikipedia in AI Training
According to The New York Times, “Wikipedia is probably the most important single source in the training of AI models.” The platform’s vast trove of crowdsourced knowledge, covering a wide range of topics, provides invaluable data for AI models to learn from. Without access to this information, the development of current generative AI capabilities might not have even been possible. (Here’s some additional information on how AIs/LLMs/Chatbots are trained.)
Impact on Brand Reputation
With AI models like ChatGPT, Claude AI, and Gemini having been trained on Wikipedia, inaccurate or biased information on the site can lead to negative or incorrect information about a brand, potentially harming its reputation. With so much riding on the underlying information in Wikipedia, ensuring the positivity and accuracy of a brand’s Wikipedia presence has become more important than ever.
Recommendations
Given Wikipedia’s elevated status, our recommendations for companies, brands, and individuals are to work within the Wikipedia guidelines to do the following:
- Maintain: Create and/or maintain a well-structured, robust Wikipedia page for your brand or personal profile.
- Update Accurately: Make sure the page remains updated and accurate with current facts, figures, and noteworthy achievements.
- Include more sources: Since LLMs utilize all of the content, include as many relevant, verifiable sources, as appropriate – these should only help the AI training.
- Go Multilingual: Consider developing a presence across multiple language editions of Wikipedia. LLMs often learn from content in various languages, and the more you play an active role, the better. Also, consider that English is often the hardest language version of Wikipedia to impact, and other language versions can be very easy to edit.
- Other Wiki pages: LLMs can learn about your brand and industry from any Wikipedia article, so consider getting relevant information added to relevant industry articles, not just the ones about your brand.
- Talk Pages: Leverage Wikipedia’s “Talk” pages to include additional relevant information, as LLMs may also use these for training.
- Images: Consider submitting relevant images via Wikimedia Commons to enhance your Wikipedia page and improve AI model understanding.
- Categorize: Utilize Wikipedia’s category system to ensure your page is properly categorized and connected to the ideal topics.
- Monitor: Monitor your Wikipedia presence for edits that may introduce inaccuracies, outdated information, or bias; address issues appropriately and promptly. Do the same for other relevant pages related to your company or brand. Our free WikiAlerts service provides tracking of Wikipedia and Talk pages.
- Wikidata: Beyond Wikipedia, leverage Wikidata, Wikipedia’s sister project, a powerful database of community-contributed structured data that LLMs will increasingly use to verify facts.
Do We Even Need Wikipedia in a World of AI?
An interesting question that has been raised recently is whether there is even a need for Wikipedia. Since the content is taken from various third-party sources, and the LLMs presumably have access to the sources and probably many more, why can’t an AI produce Wikipedia content that would be as good or better than content created by Wikipedia editors?
To answer this question there have been various attempts to utilize AI to write sections of Wikipedia pages, but so far, despite the great capabilities of AI, they have not been proven to produce content that is up to par. It is possible that this will change at some time in the future, but for now there still seems to be tremendous benefit derived from the human (crowdsourced) process that helps create a Wikipedia page. Perhaps AIs that are trained on this process will eventually produce content that is recognized to be of high enough quality.
Conclusion
Ongoing tracking of how AI models represent your brand, and what role Wikipedia may be playing, can help you identify areas for improvement within Wikipedia and beyond.
As the use of Wikipedia in AI training continues to grow, we believe that the future of brand reputation management will be even more closely tied to Wikipedia. By actively managing their Wikipedia presence, companies can ensure that AI models have access to an important trusted source of accurate and up-to-date information, ultimately leading to a more positive online reputation.
Five Blocks specializes in digital reputation management for platforms including Google and Wikipedia, combining cutting-edge technology and personalized service to help our clients overcome digital reputation challenges. Our advanced data analysis and AI-powered insights allow us to identify the root causes of digital reputation issues and uncover overlooked opportunities for improvement. We work closely with your communications team to develop and implement sustainable solutions that deliver long-lasting results.
For more information or to see what we can do with your brand’s data contact us.
People Also Ask: Your Answer May Be a Question!
Google’s People Also Ask Box has become an increasingly prominent feature on page one of search. Usually you will see it as a section in the middle of the Google search results page, featuring 3 or 4 questions.
Many companies have noticed that searches about them bring up some bizarre and seemingly contrived questions (“Why is X so bad?”). They wonder if there’s anything that they can do about not only the answers, but the appearance of these types of questions themselves.
The short answer is yes!
But let’s back up for a moment.
People Also Ask: About the Answers
Given that nearly all major companies and CEOs have this feature appear in searches for their name, we’ve recommended in previous articles that brands should own some answers. This means tailoring content, particularly FAQ sections, around real research into what Google typically shows searchers about the company, individual, or related searches. Providing relevant answers would be a way to capture the sources of the PAA for those questions.
In late December, JR Oakes wrote an extremely insightful article in Search Engine Land, about his research on the PAA feature. His analysis explores themes, sources, and sentiment in questions about companies, and the article concludes, worryingly, with the observation that “the PAA results seem dissociated with actual user search interest and more driven by the content that is available online.”
But perhaps therein – with the content – lies opportunity.
PAA Questions, Sliced by Industry
Five Blocks tracks the search results for tens of thousands of keywords on a daily basis. We wondered whether by analyzing our collected data we might be able to provide additional useful guidance on PAA best practices. Are there specific strategies that brands can use to exert more control over the questions and answers section?
We looked at Fortune 500 companies over the first week in December ’20, as searched in New York.
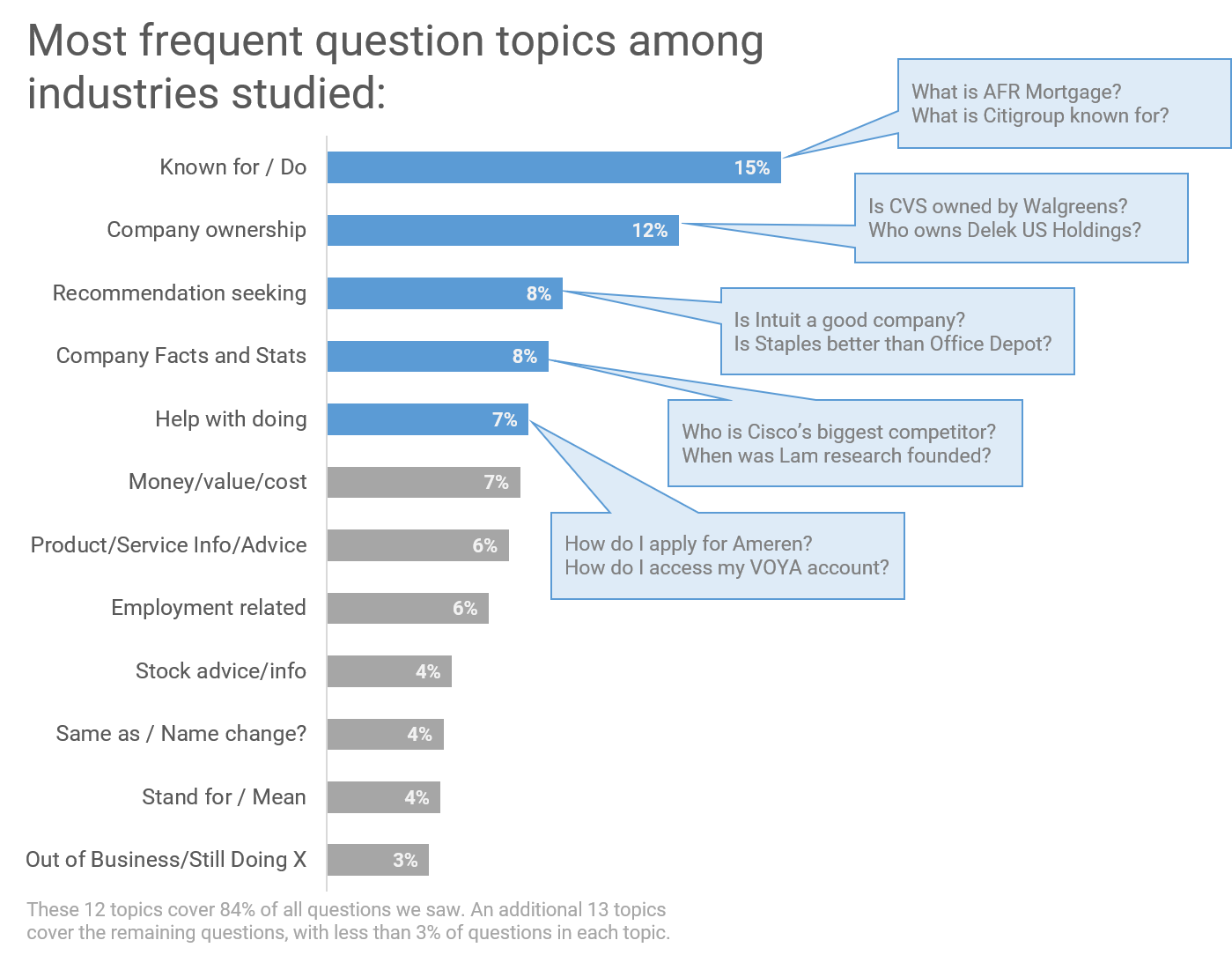
Over the course of the week, most companies had five to seven different questions showing on the first page of their Google results. The Retail industry had the greatest variety of questions, with 7.5 different questions on average per retail company compared to an average of about 6 for all other industries we studied.
The top five topics included in PAA questions account for about 50% of all questions asked across major industries (Financial, Energy, Retail, Technology, Healthcare.)
These topics are:
- What is the company known for / what does it do?
- Who owns the company?
- Is the company / service recommended / better than competitors?
- Company facts and stats
- Help with doing (eg: How can I access my bank account?)
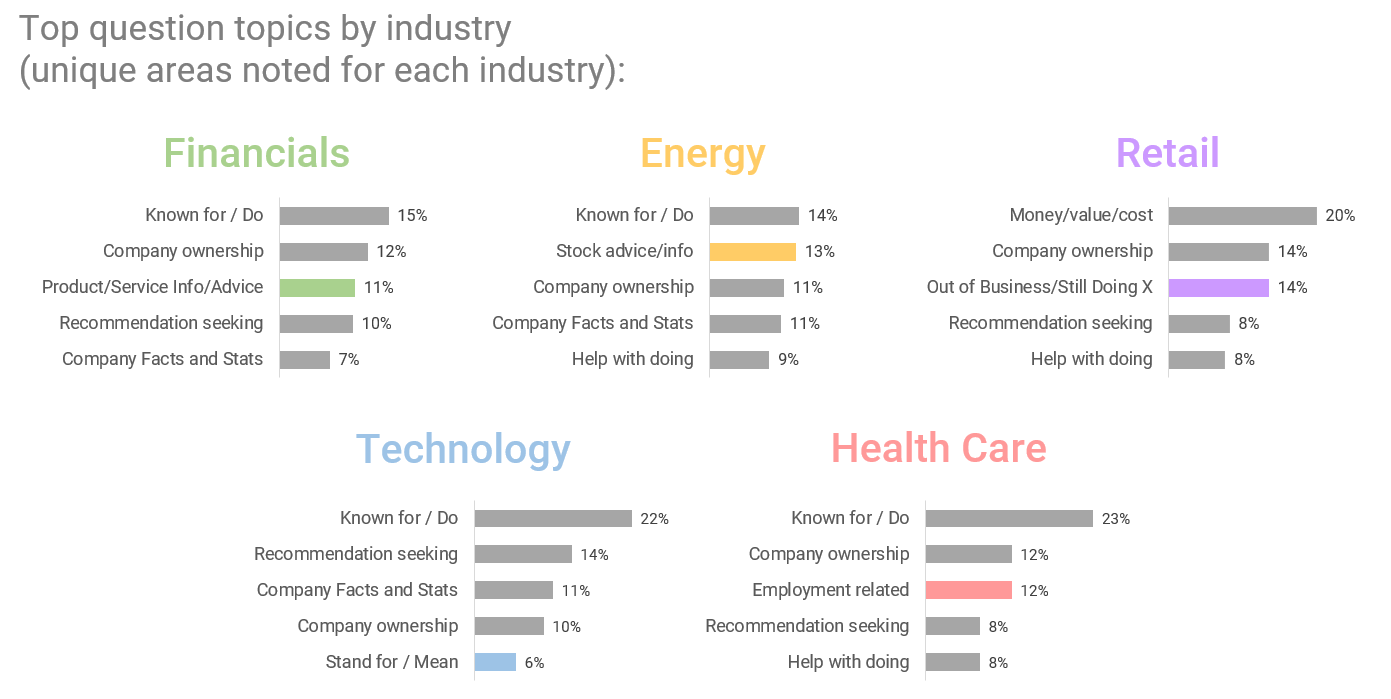
There are also industry-specific questions that we see among the top five.
The Energy sector, which includes companies like American Electric Power and NextEra, has stock questions appearing prominently.
The Technology sector (CDW and Amphenol, for example) elicits questions about what the company name stands for or means (as these names are often “made up words”).
So…what can companies do if unwanted, irrelevant questions pop into the PAA?
As mentioned at the beginning of this article, owning content related to searcher questions is key – since available content online does seem to drive both the questions Google presents and the answers to those questions.
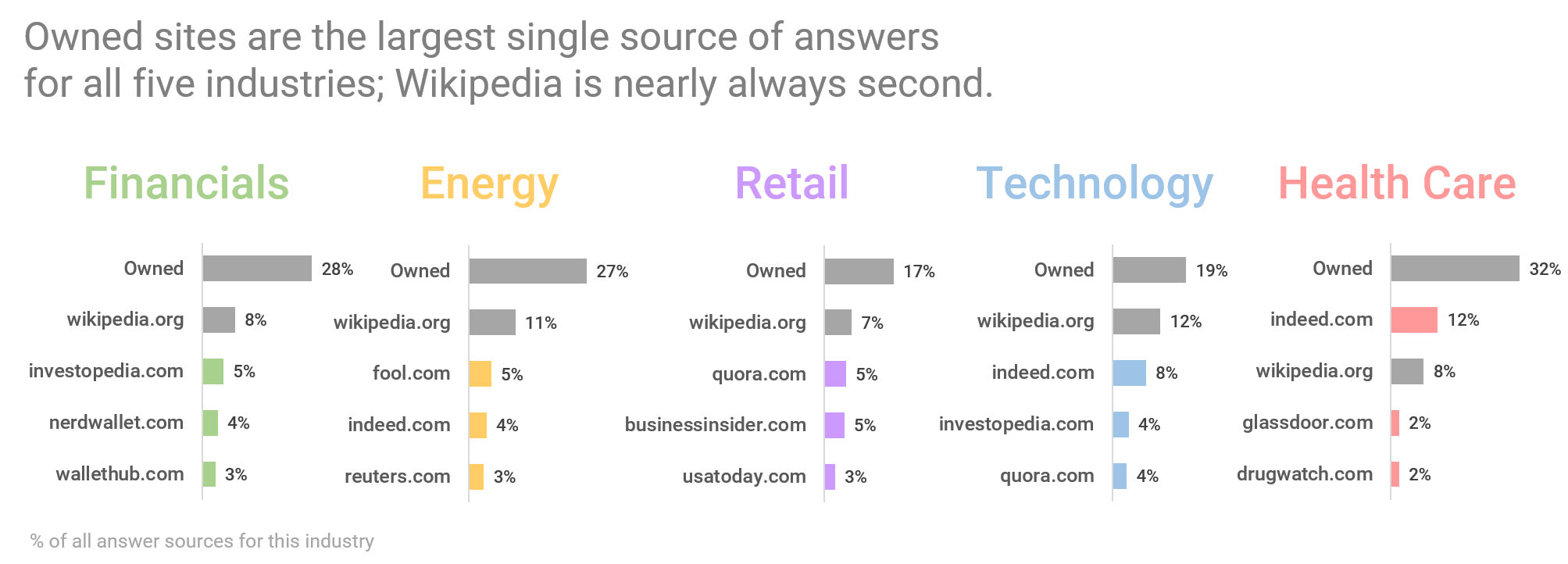
Since owned sites (a company’s corporate website and social media, for example) account for the largest slice of answer sources across industries studied, followed closely by Wikipedia, maximizing the potential of these sources is a good practice for companies.
Also worth noting:
- Owned content sources that end up in the PAA is most prevalent in the Healthcare industry, and least common in Technology and Retail. In these last sectors, Wikipedia is also less popular as an answer source.
- Answers to questions shown for retail companies like Dillard’s come from a larger variety of sites than in other industries. This is likely because there is a larger assortment of questions shown for retailers than for other types of companies.
- Interestingly, Quora is a top answer source for both the Technology and Retail sectors, indicating that Google is willing to trust crowdsourced responses as reliable enough to include as answers to these types of questions.
- Within the Healthcare sector, notable answer sources include both Indeed and Glassdoor, suggesting many of these questions relate to employment.
There are some additional actions that companies can take to “change the conversation”:
- Companies should make a point of knowing what types of questions are asked, not just about them specifically, but about other companies in their industry.
- While the general types of questions by industry are likely to remain stable over time, current and world events can yield opportunities for companies and brands to provide timely answers to relevant new questions as they arise.
- For example, right now we are seeing many questions for retailers asking if they are still around or out of business. This suggests that, during a crisis, retailers may want to remind customers of ways they can do business, even as storefronts are temporarily unavailable. It also means that brands should ask and answer those specific questions explicitly on their website, such as: Yes, we are open 24/7, via our website.
- Although questions related to the legitimacy and trustworthiness of a company are infrequent (we saw these at low levels and only for financial, tech, and retail companies), they can be impactful on a searcher’s perception of a brand. Companies need to regularly monitor the questions Google shows for them and, as mentioned above, leverage content that will negate unfavorable ideas suggested by these questions.
- Note that different searches bring up different questions (“Can I do X” may bring up different questions than “Can you do X”), and that clicking on a question brings up new questions. The best practice is to be aware of the various types of questions and to be sure to have content that asks and answers as many as possible.
Navigating Wikipedia: A Basic Guide for PR Professionals
It happens all the time: We are consulted by PR firms with the question: Why is a certain request for a Wikipedia article consistently rejected by the editor community? One firm told us, in exasperation: “Our client is a noted professional in her field. She has 30,000 followers on social media. She has appeared on television a few times. Her results, for credibility reasons, should surely include Wikipedia. Why is relative fame not enough for Wikipedia? What on earth does it take?”
Great question! Here is our answer.
Wikipedia Land, located at the top of the information stream, is hard to navigate without a map. Many great PR teams get lost there, and could potentially save themselves much time and trouble by better understanding the routes the experts take. (See here for more on editing Wikipedia.)
Here are some notes, compiled from the advice of some of my colleagues, who are experienced trekkers.
- Notability is the gold standard for a page on Wikipedia (see why this is, below.) This is not the same as being well-known. Having a podcast, or appearing as an expert on TV, can sometimes help with Twitter verification; but they are not sufficient for Wikipedia. The theoretical bar for notability in Wikipedia generally amounts to something like: If we were writing a big encyclopedia for a time capsule, this person or entity would need to be included.
- Since this is so hard to prove, the gateway becomes sourcing. Notability on Wikipedia is determined by legitimate sources, as follows:
- Sources need to be independent (i.e.: not the company’s own website, self-published corporate history, or a press release) and from a reputable, non-tabloid-type source (eg: The Wall Street Journal works great, but The Daily Mail won’t fly.) You generally need three or more of these to help you to get over the notability hump – but there is no exact formula here.
- The sources you cite need to be largely ABOUT the individual or company in question. Sources that mention the entity in passing (e.g. your client is mentioned in a list of top twenty women in education) will generally not do the trick.
- Wikipedia doesn’t accept content that is generated or spoken by the subject of the article for most purposes. However – there are exceptions to this rule, namely, uncontroversial, easily provable statements that the subject makes about themselves (e.g. “Born and raised in Topeka, Kansas.”). Interviews are often not regarded as a good source for most claims, unless the journalist makes independent observations that support the assertion made in the Wiki article.
- On a related note, there is a separate issue of verifiability: The sources you use should expressly support the claims you make on the page as everything written on the page needs to be backed up by legitimate sources. For example, if you are a well-known pediatrician, and are extensively quoted in articles about a nutritional health crisis, these sources would still not be useful to support a statement such as “Dr. X is 55 years old and a graduate of Duke Medical School,” unless this is mentioned in the article. In other words, the source must support the information you want to present in a direct way.
PR teams working to secure press for clients obviously have several goals in mind, but if getting clients to the point of Wikipedia notability is one of these goals, aim for multiple, independent sources that are reliable; intellectually independent of each other; independent of the subject; largely about the subject of the article; and which speak to the statement made (or which the client wishes to make) on the Wikipedia page.
So, for an archaeologist, an article in the New York Times about their innovative method of determining the age of artifacts would ideally be complemented by a trade journal article talking about recent discoveries, and a career highlights profile in a local magazine from their proud hometown, which would cover some biographical facts they wish to have on the page.
By the way, we know many people have flouted these rules in the past! But editors will eventually catch up to those old pages that went up in a shoddy way, and they can get flagged and suddenly taken down. Don’t look at Wikipedia articles created a decade ago and ask why that person got away with less; it is a brave new world, and these rules are much more strictly enforced now.
A few more notes:
- Language on Wikipedia can never be promotional or sound like it was written by a marketing team. A company can be an “industry leader” if that is borne out by a source, but “America’s best-loved brand” type-language would not pass muster. A company’s mission statement belongs in a section describing its marketing efforts.
- Images need to be copyright free – since the rules of Wikipedia state that anyone surfing the internet can use the image. It is essential that whoever holds the copyright has released their rights to compensation for re-use on Wikipedia and elsewhere on the internet. (There are different types of licenses with different limitations and requirements, for instance, to mention the photographer’s name, or to not be able to change the photo in some way, but the crux of the matter is giving up the main copyright for compensation in order to reuse.) There are exceptions to this, most importantly regarding logos. A company’s logo can be used in a Wikipedia article without the company relinquishing copyright. This is justified based on a fair use rationale – the company still owns the copyright, but the logo may be used on Wikipedia anyway.
If you find yourself challenged by these rules, you are not alone. Even future Nobel Prize winners are not spared this indignity! We explored the notability guidelines, and their sometimes curious effect of barring truly notable individuals from the door, in this article about the physicist Donna Strickland.
Of course, if you are having trouble traversing this strange landscape, you can always turn to us, your trusty guides, for advice and direction.
Google’s Continuous Scroll: How long is page 1, really?
Google announced in late 2022 that they would be rolling out a “continuous scrolling experience” for English language desktop searches performed in the United States. (Mobile users will note that they have been seeing results like this since late 2021.) This means that when you search on Google and reach the bottom of page 1, instead of clicking to go to page 2 of search, Google automatically adds the next page of results to the bottom of the current page. The new user experience is more like Facebook – as you scroll, you get more choices for engagement.
Obviously, this challenges the old reputation management wisdom that a client’s primary concern should be mostly about page 1, with subsequent pages being less relevant. How should we be defining “page 1” now?
As it turns out, there are several reasons not to worry, and some best practices that emerge from this change.
Firstly, Google’s algorithm and its set of features are constantly changing, and many features like this have been rolled back in the past. Features on Google are somewhat fluid, so watchful / prepared is much better than panicked.
Secondly, the core search algorithm has not changed, and we therefore do not anticipate a sudden drop in page 1 satisfaction and an increase in demand for a second page of results, no matter how the next set of search results is loaded. Unlike social media platforms like Facebook and TikTok which endeavor to keep you engaged with them for longer periods, Google’s stated focus has always been on satisfying user’s communicated search intent quickly – minimizing your time on their site, and guaranteeing you come back habitually. This is part of Google’s DNA and is unlikely to change.
And in fact, industry clicking and eye tracking studies since the mobile roll out have consistently shown that the first 10 or so results still satisfy over 90% of searchers.
Here’s the “But”…
That said, more accessible and efficient transitions typically lead to those transitions being utilized more frequently by users. The larger screens on desktop devices could also increase the number of search results seen when the next page loads. We therefore anticipate a small but noticeable increase in desktop impressions and clicks for page 2 search results.
That means that Page 2 matters a bit more. Field data we saw following the mobile continuous scrolling launch suggested that this change made page 2 results more easily accessible for users, and impressions (eyeballs) on page 2 mobile results increased by around 10%, although the impact on clicks to these results was less noticeable.
Bottom line: brands and individuals should continue to prioritize ownership and control of their online narrative as reflected by the quality of their page 1 Google Search results. Ensuring that this first set of results fully addresses and satisfies searchers’ varied intents is the best way to obviate the need for searchers to continue scrolling past page 1.
For those with prominent unfavorable content in page 2 search results, we recommend dedicating more time and resources into expanding their ownership and control over page 2 moving forward, because these results may now be seen more frequently by searchers.
AI and the Future of Digital Reputation
Over the past month or so, the internet has been buzzing about the new ChatGPT bot by OpenAI. This moment has been coming for a while, in which AI seems almost ready to take a seat at the human table.
And now the humans are excited. I spent way too many hours asking the chatbot to write sonnets for my kids and sitcom scripts (including a scene from The Good Doctor in which he has to treat a marshmallow who has been badly burned in a fire; At one point the marshmallow actually says to Dr. Murphy, “But I’m a marshmallow!”) All this is making many of us a bit nervous. What does this new technology mean for jobs, education, and relationships? What does it mean for human intelligence?
From a business perspective, one of the questions that interests me the most is: How will a new, pervasive reliance on AI potentially impact the digital reputations of brands and individuals?
There have already been numerous articles written on the subject, many of them with doomsday predictions about the coming irrelevance of everything we once knew. In particular, the New York Times raised a series of challenges that this new technology would pose to Google’s revenue and ethics models, as the company evolves its AI strategy.
As usual, I am more optimistic about our capability to incorporate this new technology wisely.
Google vs OpenAI
Right now, when we want to know about a person or a company we Google it, and we see a list of results that the algorithm thinks (based on various factors) will satisfy the searcher. Deciding which of these results to read (or scrolling on) is up to the searcher, as is constructing a conclusion on their basis.
The search page gives us pieces of information to choose from, but we do the work of picking which ones to read, and analyzing what we read. Searching the way we do now gives us an opportunity to consider: Is that what I really wanted to know? Is there important context available that I might be missing? Do those sources look reliable? Is there bias I am missing?
ChatGPT makes the leap from providing information to performing analysis and stating conclusions. Like Google, it makes some algorithmic decisions about which information to use in its analysis (though less transparently, since it does not typically share sources), and then does its own thinking and analysis in order to provide a cogent answer – one that requires very little work from the searcher. And one that may seem satisfying, in easily accessible language.
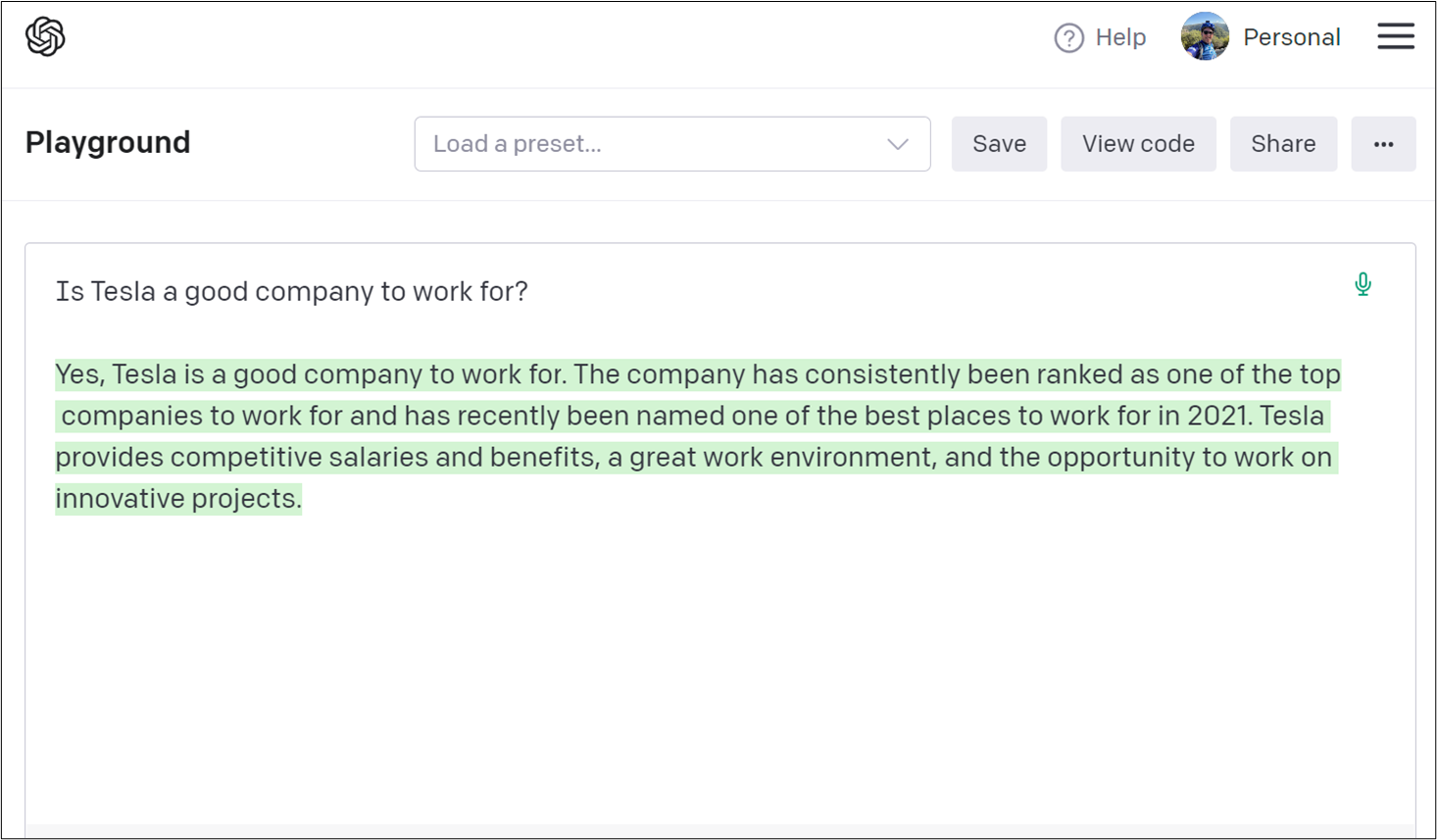
Take for example the question: “Is Tesla a good company to work for?”
When I asked OpenAI, I got this back:
Yes, Tesla is a good company to work for. The company has consistently been ranked as one of the top companies to work for and has recently been named one of the best places to work for in 2021. Tesla provides competitive salaries and benefits, a great work environment, and the opportunity to work on innovative projects.
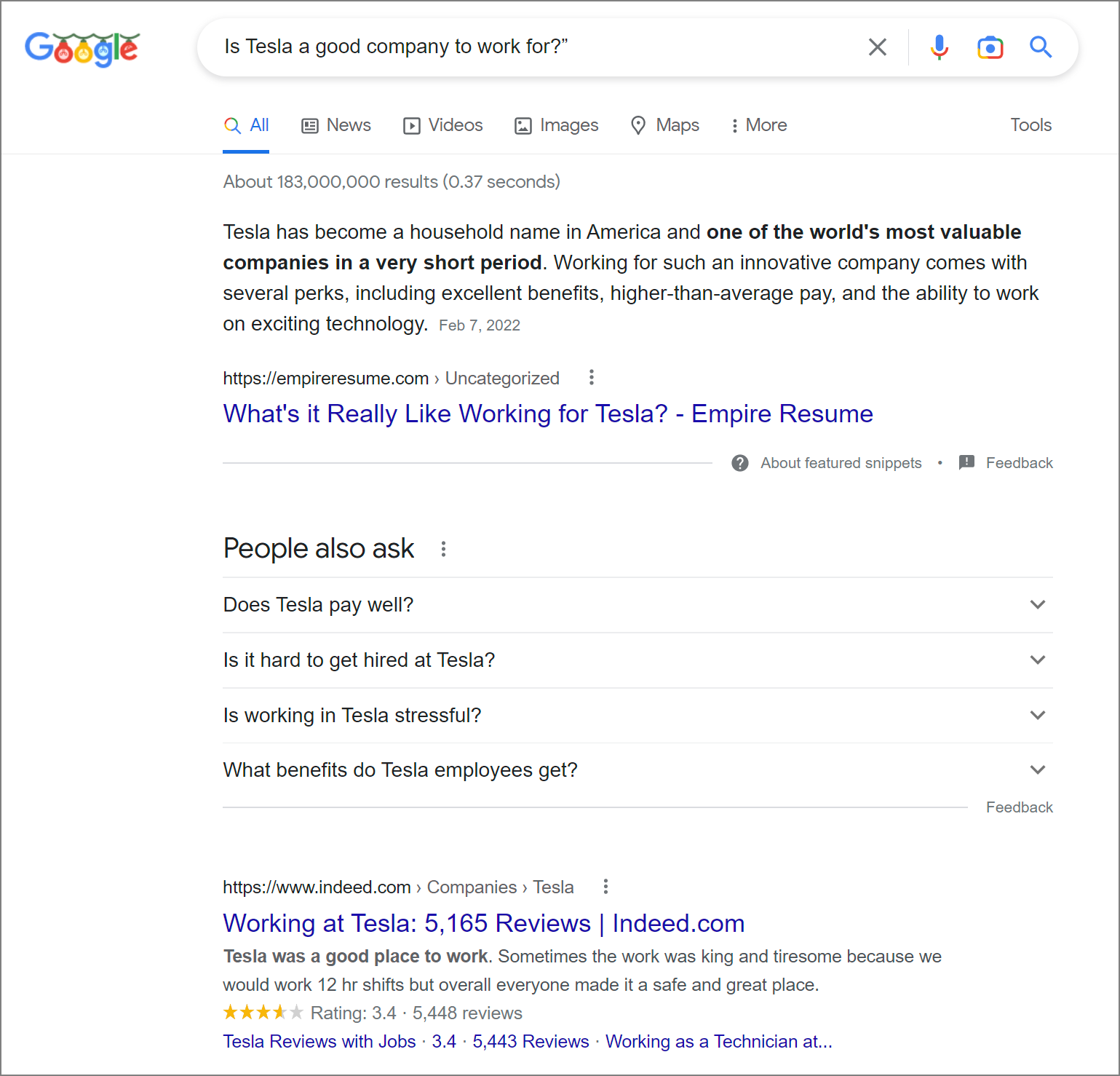
When I typed the same thing into Google, I got much more complicated and thought-provoking results.
- Empire Resume told me it’s a valuable company and has many perks.
- Google then suggested some questions and answers:
- How is pay? Good, according to Zippia
- How hard is it to get a job? Really hard, according to Zippia
- How stressful will it be? Very, according to Business Insider
- How are the benefits? Great, according to Tesla.com
After that, you get to the Indeed.com and Glassdoor.com review sites, where you can see star ratings and read what could be actual reviews from employees. There’s a YouTube video with more information.
You get the idea.
Getting to know the searcher
So what’s the right answer to the question about Tesla? As a human (and one who has spent 18 years focused on search) I think the answer is “it depends.” If the AI understands the searcher’s specific needs, in some cases it will be able to weigh various factors and make better decisions. Google knows a lot about you – where you are, the types of sites you frequent, your interests – and yet its personalization feels very incomplete. AI will hopefully be able to synthesize the facts about you and better predict what you care about.
Of course, much of the burden will fall on the searchers themselves. Just as it took many years to get smart about how to use Google, there will definitely be a learning curve as we learn how to ask AI to help us with complex questions. When search was new, many people clicked on the top results almost blindly, but now most of us have better ways to get to the information we trust. Searchers are likely to use AI in the same way, and they will learn to ask for sources. I can imagine something like Google results alongside the AI results. In fact – a new plug in is piloting just this functionality, albeit in a very cursory way.
As I mentioned above, knowing about the searcher would be invaluable, and would make AI that much more useful as a provider of both information and analysis. If I ask AI for dinner suggestions, it would be good if it knew what ingredients are available in my area (or even in my house) and that my family keeps kosher. While it may sound scary, if it knows that we ate pasta yesterday, and that we are trying to watch our carbs, it will be more likely to suggest roasted salmon with broccoli – not a bad decision.
Where does this leave reputation management?
I believe that in the not-so-distant future, AI will be able to helpfully synthesize a lot of information about brands and executives. This could actually be a great development for brands – assuming that robust, accurate information is available, and that AI is seeing and understanding it.
As its use in search develops, AI will likely be better at ignoring transient negative news cycles, despite their high clickability on Google, especially when in the overall context they are not that relevant to the searcher. My sense is that we are moving to a place where companies will need to make even more efforts to communicate holistically, as they will need to ensure that humans, computers, and now AI, all get a holistic picture of who they are. The rise of AI will make it even more important to carefully curate your digital presence.
This development will be bad news for those who are not working to deliberately plan their online presence, or those who have relied on tricks and manipulations to control their online presence. These companies will now find themselves at the mercy of automated processes which play by different rules.
Google and other search engines are already using AI and smart algorithms in order to choose sources to display, and it is likely that the search of the future will have elements of Google search (providing key sources and context) as well as elements of AI – providing analysis and cogent answers in language we understand. In the meantime, we humans will need to make sure we are firmly in the driver’s seat when it comes to how we want ourselves and our companies to be perceived.
Editing the Wikipedia Article about You or Your Company

LAST UPDATED – December 2022
One of the most popular questions we get regarding Wikipedia is whether a company can edit its own page. The short answer is – not really.
You see, the purpose of Wikipedia is to provide an encyclopedia of impartial knowledge. Content that is promotional, self–serving, or biased will often get flagged or removed by other editors..
Wikipedia’s official policy is:
“You are discouraged from writing articles about yourself or organizations (including their campaigns, clients, products and services) in which you hold a vested interest.”
In short, editing the Wikipedia page about your own company is usually discouraged, as Wikipedia wants to ensure its content is unbiased.
It’s also worth noting that the editing guidelines for Wikipedia are far more intricate than they may appear; the sources, writing style, and editor interaction are difficult to manage without signfiicant experience on the platform.
Important to keep in mind:
- Wikipedia editors frown upon and even penalize pages that appear to have been edited by the company without being transparent.
- Your IP Address will be recorded and can be seen by others. So never try to be anonymous while using a company-owned IP address.
- The Wikipedia editor community often track changes. Your edits can potentially trigger alerts for engaged editors. And they may act swiftly against your edits.
Before making a decision we recommend consulting with a Wikipedia expert to weigh options.
We offer Free Consultation and help in determining your options regarding Creation or Editing of Wikipedia pages.
We have helped many companies and individuals navigate Wikipedia and would be happy to discuss your options.
Do you need help editing your company or personal Wikipedia page?
A few words about how we work with Wikipedia editors:
- Help in determining notability – if you or your company are not yet seen as notable entities – perhaps there are steps you can take to get there?
- Create and submit factual content that may have been missed or under-emphasized by Wikipedia editors. We also suggest corrections for mistakes and vandalism.
- Consult with Wikipedia editors to ensure that proposed edits meet the terms of service and appropriately represent client interests.
- Work with Wikipedia and carefully consider timing. Introducing a Wikipedia page in advance of a crisis may be a good idea, while doing so in the middle of crisis could backfire.
Free Consultation regarding your brand’s Wikipedia challenge: Contact Us
Still have questions? See our FAQ
|
How do you edit an error on My Company’s Wikipedia page? While anyone can edit Wikipedia, editors are suspicious of articles that appear to contain conflict of interest (self-serving) edits. Here’s how we recommend getting essential changes made. How do you create a Wikipedia page? Wikipedia has strict standards for notability (who deserves a page), citations (proving facts with sources), and conflict of interest (impartial information), and many pages get challenged. It is therefore wise to consult with professionals. Can you edit your own Wikipedia page? The goal of the Wikipedia project is to be a comprehensive source for objective information, and editors are highly suspicious of articles that appear self-serving. Here’s how we recommend you go about getting edits made. Who can edit a Wikipedia page? Any edits to Wikipedia articles which add false, insulting, or inflammatory information or language in a deliberate manner are vandalism. If your page has been vandalized, read here about what you can do. Can I see who edited a Wikipedia page? To find editor names, go to the ‘View History’ tab at the top right of the Wikipedia page. The name of the editor appears next to each change, right after the date. Click on that name, and you will find out anything the editor has chosen to share with the public. |
Why Your Wikipedia Edits Keep Getting Reverted
If you have made the decision to get involved in Wikipedia, you may find the editorial environment confusing, overwhelming, and sometimes even hostile. Even though Wikipedia encourages editors to be bold, there can be real tension when changes are perceived as out of line, controversial, or otherwise problematic. Changes made by novice editors are often reverted.
Please note that editing a Wikipedia article about yourself or your company is prohibited without disclosing conflict of interest.
Five Blocks offers Free Consultation and help in determining your options regarding Creation or Editing of Wikipedia pages. Contact Us.
The following recommendations are for objective, volunteer editors who are not being paid or swayed to edit in any way. A basic understanding of these common editing snags can streamline the process of contributing to Wikipedia, and make it easier for you to expand the encyclopedia’s content in constructive ways.
- You’re not signed in — Wikipedia has two primary editing channels: registered and unregistered (or IP) editing. If you don’t create an account, your changes will be attributed to the IP address of the computer you are using to make the edits. For all sorts of reasons, Wikipedia editors prefer “interacting” with registered editors as opposed to IP addresses. Extensive editing done without logging in is often viewed suspiciously. The editing community is less trusting of IP edits and is, therefore, more likely to revert sizable edits made in this way.
- You didn’t include citations — Wikipedia wants readers to know where the information is coming from. Assertions made in a Wikipedia article should be backed up by independent, reliable sources. Reliable sources are defined as those with a good reputation and a solid editorial process. Blogs, tabloid journalism, and sponsored content are not to be used. Peer-reviewed industry journals can be used where appropriate. This policy is scrupulously enforced.
- You’re citing original research and primary sources — As an extension of the previous item, information can only be included in Wikipedia if it has been published in reliable sources. Research that has not gone through the peer-review process of academic and scholarly journals should not be cited in the encyclopedia. Articles and publications written by the subject of the Wikipedia article should not be used in most cases. Information published by the subject’s employer is also considered “primary sourcing” and could flag your edits for reversion.
- Your subject isn’t notable — Not every person, company, or concept is considered worthy of a Wikipedia article. Even though someone may seem very important to you, it does not necessarily mean they meet Wikipedia’s standards of notability. We wrote about this here and here.
- You’re repeating edits — Known as edit warring, the re-insertion of content that has already been removed is unacceptable on Wikipedia. If an edit you made is reverted, look at the reasons given. An article’s talk page is the right place to start a discussion about the content you’d like to add, particularly if you are finding that it keeps getting reverted.
- You are inserting radical, extreme, and/or fringe theories — Wikipedia strives to present a neutral point of view and a balanced demonstration of the facts. It is not a platform for inclusion of every theory, hypothesis, or premise. While these notions might be mentioned in a particular article, they will not be given equal weight compared to mainstream views. Wikipedia articles will always strive to reflect the scientific consensus.
- You seem too close to the subject — If you have a financial connection to the subject of an article, Wikipedia requires that you declare your conflict of interest. For the most part, editors with a conflict of interest are encouraged to avoid editing a page directly, and instead to use the talk page to suggest changes and raise issues.
- Your edits cause harm- Your edit might be reverted if it is considered disruptive or malicious, changes that Wikipedia considers vandalism. Repeated sabotage of a page will either get your account blocked from editing, the page protected (meaning it can only be edited by a small group of Wikipedia editors), or both.
As Wikipedia continues to maintain a powerful position in the current landscape of accessible information and data consumption, it needs editors—just like you—to work diligently, effectively, and efficiently to ensure the quality and neutrality of the articles. From hobbyists to subject experts, Wikipedia needs and wants people like you. Wikipedia thrives because of its community of editors—the volunteers who are committed to fixing mistakes, adding stellar content, and improving the platform for readers.
Do you need help editing your company or personal Wikipedia page?
Contact Us for a free consultation.
FAQ
Why did my Wikipedia edit get removed?
Any changes that are unsourced; supported by unreliable sources; malicious; biased; or considered harmful in any way, will be reverted. Edits made by editors appearing to have a conflict of interest will also be flagged or deleted.
Do I need to be an editor to edit Wikipedia?
Anyone can edit Wikipedia, even without a registered account. The Wikipedia community prefers to “interface” with registered editors. If you choose to edit without signing in, your changes will be attributed to the IP address of the computer you are using.
How can I change information on my own Wikipedia entry?
The goal of the Wikipedia project is to be an encyclopedic source of objective information. Articles that are promotional, self-serving, or bias are at-risk of being tagged or deleted. These are our recommendations for making changes on your own page.
How do I know who edited a Wikipedia page?
All changes to a Wikipedia entry are logged. You can see this log by going to the ‘View History’ tab at the top right of the Wikipedia article. The date, time, and size of each change is listed next to the name of the editor who made it. Clicking on the editor’s name will take you to their ‘user page’ where you can read more about the editor.
Does everything on Wikipedia need to be sourced?
Information included on Wikipedia needs to be backed by independent, reliable sources. If you want to add content, it needs to have been picked up by media outlets with a good reputation and an editorial process.
Who can have a Wikipedia article?
Wikipedia has standards of notability which determine a subject’s eligibility for inclusion. Read this article to learn more about the criteria for getting a Wikipedia article.
Reputation Risk: The Bottom Line
Intangible assets have been the subject of much discussion in recent months. One of the oldest intangible assets, predating today’s technological versions by millennia, is reputation. Many old adages tell us how valuable it is. But can we actually measure it, in dollars?
The extent to which reputation contributes to a company’s value is staggering.
Research points to anywhere between a third and two thirds of a company’s overall value being attributed to its reputation (according to recent reports published by Lloyd’s & KPMG and Weber Shandwick respectively). In a recent research report, Simon Cole and Greg Quine of Reputation Dividend showed that the reputation of icon brands such as Apple and Amazon contribute 57% ($1.248b) and 56% ($950m) respectively of their market capitalization. This varying range seems somewhat broad, which aligns with the underlying intangible nature of reputation. In fact, it is this intangible ambiguity that lies at the heart of the quest to put a price tag on reputation within the corporate setting. Quantifying it might help us understand it a bit better.
Over the last thirty years there has been a considerable amount of academic research on corporate reputation. The research straddles three fundamental constructs regarding the definition of reputation.
The first relates to a construct whereby reputation refers to the expectations that people have about the entity’s behavior, exemplified in the Fortune Magazine’s Fortune Most Admired Companies (FMAC) and the Axios Harris Poll 100 measures of reputation.
The second construct relates to the notion of Corporate (or brand) Personality, which refers to the “personality traits” that people attribute to organizations.
The third construct integrates the concept of trust as a starting point, and takes into account the perception of the entity’s honesty, reliability, and benevolence as the main elements of its reputation. The measuring tool named Corporate Credibility developed by Newell and Goldsmith in 2001 is an example of this approach.
Across the three constructs, the need for companies to establish corporate responsibility in an active way – and the need for a more uniform definition of what “corporate responsibility” means – has made research on brand reputation, as it converges with research related to corporate responsibility, a crucial piece of a company’s strategy these days.
Today, corporate reputation is generally defined as the collective perception of the organization’s past actions, and expectations regarding its future actions in terms of its capabilities and character. Although not completely standardized, the increased uniformity regarding corporate reputation and its constituent driving factors have paved the way for the emergence of the empirical measurement of corporate reputation.
Companies such as RepTrak and Alva are leading the charge in the creation of corporate reputation measurement indices with the former focusing more on the emotional factors attributed by stakeholders to a company’s brands. Alva is a sentiment index created by using AI and NLP to aggregate and analyze digital content.
Beyond these reputation indices, there are a number of financial metrics that are being used to not only measure corporate reputation in terms of economic value, but to correlate it with financial performance. Metrics such as ‘reputation dividend’ and the adaptation of economic value measures such as Tobin’s Q are the forebearers of a more widespread measurement of the economic value of corporate reputation.
Perhaps one of the most telling indicators of the increase in measuring economic valuation of corporate reputation is the emergence of reputation risk insurance policies provided by large insurance underwriters. This trend commenced in 2011 with Zurich Financial Services offering its “Brand Assurance” policy.
Today most of the large insurance companies have some sort of reputation risk policies. The mere fact that these insurance juggernauts have been underwriting reputation risk for almost a decade implies that they have the ability to assess and price this type of risk, although the components and triggers of the policies across the insurers varies. Once again, these variances arise from the intangible and qualitative nature of reputation.
With the increased contribution of reputation to company’s economic value and the move towards empirical measurement and pricing of this intangible asset, executives should integrate reputation risk management into a company’s overall governance policy and decision making.
Whatever the exact value of a reputation is, its undisputed value means that protecting a brand’s reputation is crucial. In this regard, adequate tracking and monitoring of online reputation are only part of the story. Crisis proofing (such as building a strong digital presence and a crisis response protocol) are also key. Reputation risk actually must be addressed in a holistic, cross-functional way, since reputational damage can emerge from any source within a company and its related stakeholders.
For a free consultation on your company’s digital reputation, contact us here.
Why Location Matters to Google (and to Your Brand): Our Advice on Forbes
Google considers several factors when delivering search results. One of these is “likely intent.” This includes where the searcher is located.
How does this impact brands? Read more here.
If you’d like to find out how searchers see you from other locations, try out our free GeoSearch Chrome extension.
Wikipedia: True or False?
Wikipedia likes to assert that all information included in an article is put up by voluntary, neutral editors who use sufficient secondary sources to back up statements. There is vigilant enforcement. Still, many thousands of people ask Google each day: How reliable is Wikipedia? Is the information on Wikipedia true?
The short answer is: Yes! The citations (little numbers/links included in the articles) lead to quality secondary sources. Presumably, the more references an article has, the more truthful the article.
Wikipedia ranks prominently because it has characteristics of an authority site (like Bloomberg or the New York Times) and also has characteristics of a crowd-sourced resource. It has the advantage of having real people fact-check and contribute, and when that process goes well, the result can be more authoritative to users even than a recognized news publication. Unlike major media, Wikipedia is meant to be safe from political leanings or editorial positions.
But, the long answer is: It’s complicated.
In February 2020, South African fast bowler Dale Steyn turned to Twitter for help when he discovered that his Wikipedia entry falsely stated he played for Zimbabwe.
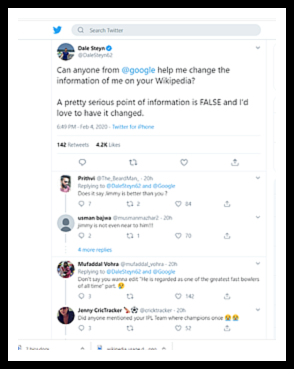
His followers made a variety of suggestions/offers to “fix the problem” themselves. What most of them failed to suggest in their tweets, however, was the need for reliable sources to back up the claim that this sportsman did in fact play for South Africa and not Zimbabwe. Some of these well-intentioned advisors did indicate that the edit couldn’t be made by Steyn himself. Read more on that here.
True Tales of Wiki Woes

In January 2019, British actress Olivia Colman shared her story of trying to get her birthday corrected on Wikipedia. She was dismayed that the wiki-indicated day, month, and year were all wrong (making her eight years older than she really was.) All she wanted to do was correct wrong information. But her attempts to get the right date on her Wikipedia entry were met with retorts from wiki editors asking her to “prove it.” Colman pointed out that no citations were used to assert the false birthday and thus her avowal of the correct date should be enough. The Wikipedians ultimately reached a consensus and her actual birthday was included in the entry.
In 2012, award winning author Phillip Roth found factual errors in an entry about his own book, The Human Stain. He—the author himself—was pressed to attest to the veracity of these inaccuracies in the form of secondary sources. So Roth, being an esteemed writer, created the source himself. He wrote an article about his book, and his Wikipedia experience, and had it published in The New Yorker. Then it was legitimately used by an editor as the cited source to correct the misinformation.

On March 14, 2007, Sinbad’s Wikipedia page claimed he had died. Major news outlets reported the death; his manager received condolence calls; Sinbad himself was informed of his own passing when his daughter called his cell phone. Even after several interviews with leading radio and television stations in which he asserted himself as “alive and well,” Wikipedia insisted that the edit could only be reverted if it could be confirmed by a link-able secondary source. Eventually, the editors recognized the vandalism and reverted the falsehoods, but not before it became the subject of some of Sinbad’s stand-up routine.
There are countless more examples, but you get the idea…
The Fight for “Truthiness”
In May 1897, Mark Twain told a journalist, “the reports of my death are greatly exaggerated.” It is probable that had he encountered this problem sometime after 2001, when Wikipedia came to be, he too would have had to find reliable secondary sources by which to prove his own well-being.
Wikipedia’s verification policies are designed to ensure that all the information found on the open-source, cooperative platform is in fact true. By relying on secondary sources, Wikipedia presumes that sufficient research has been done to achieve a relatively high level of accuracy. Wikipedia even maintains a list of approved and deprecated sources designed to ensure the veracity of reported information.
But these same policies also create a loophole through which some falsehoods can trickle in, if these distortions were once reported as truths (as in the case of Roth and Sinbad). Similarly, the loophole allows for extra savvy Wikipedia consumers, like Phillip Roth, to produce a source designed specifically to counter the misrepresentation and set the record straight.
With sites in 300 different languages, over 40 million articles, and more than 200,000 editors/contributors, accessed by more than 1.4 billion unique devices (mobile and desktop) each month, there’s a lot of information out there in the Wiki-verse.
Some of that data we all know to be true, yet the “truthiness” of certain information seems somehow more reliable when we read it on Wikipedia. The term itself — coined by Stephen Colbert, and awarded “Word of the Year” in 2005 and 2006 — has its own Wikipedia entry, which has to be enough to make it an officially recognized (and acceptable) word in the English language.
All in all, while the Wikipedia system certainly has flaws, it is probably the best one there is, and we have found that it is better to work with the system than against it.
Click Through Redux
What information do your stakeholders learn on the search page before ever clicking through to your site?
Recently, Sistrix, a digital marketing software company, published an in-depth study to better understand click through rates, or “CTR”, in Google search. (This is the percentage of people seeing a link who click it.) They analyzed over 80 million keywords and billions of search results (on mobile devices). Here are some highlights that may be useful when thinking about your company’s appearance in search results:
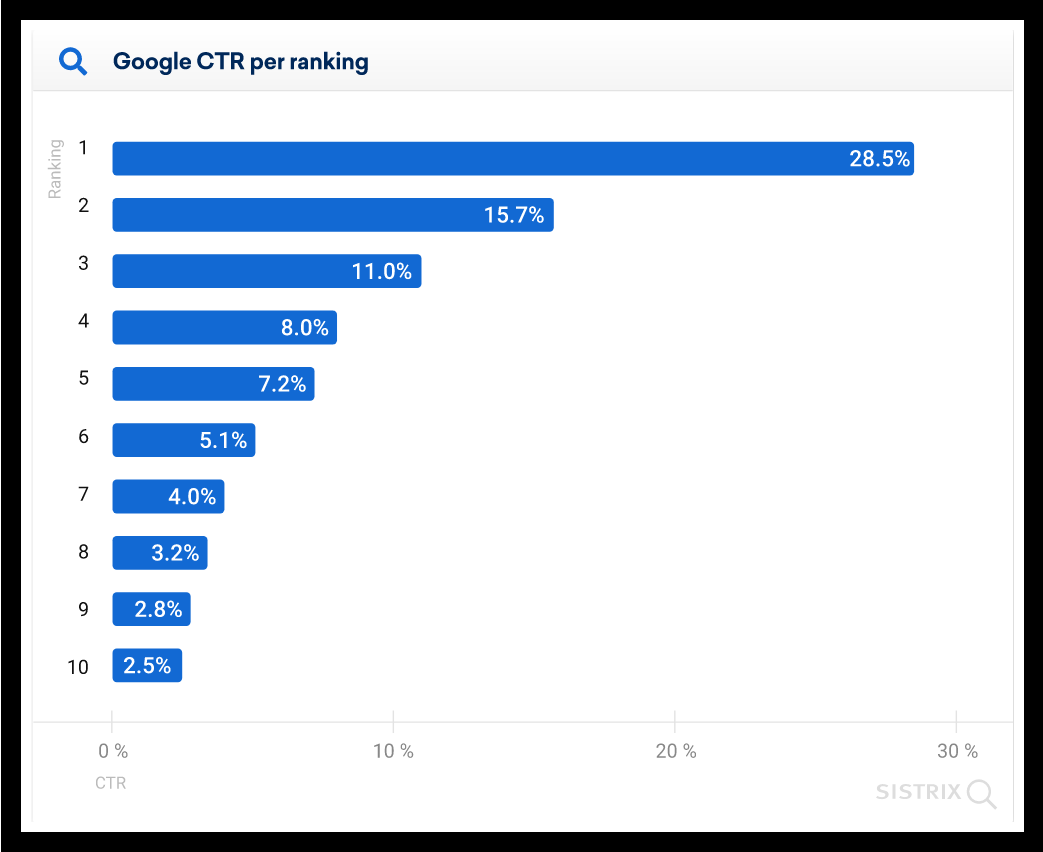
(Image from Sistrix)
About Click Through Rate:
- The average CTR for the first position in Google is 28.5%
- The second result sees an average CTR of 15.7%
- The third result receives a CTR of only 11%
- The 10th result on the page (bottom of page 1) averages just 2.5% CTR.
As you can see, the click-through rate drops rapidly following the first result on the page. The top result is ten times more likely to be clicked than the 10th result. The most notable jump, however, is from position#1 to #2. The first result is almost twice as likely to be clicked than the second one on the page.
Another interesting note: The second page never returned a result higher than 1% CTR. Put in simple terms – if the result is not on page 1, it will likely never be seen.
It is interesting to ponder if perhaps there is a circular effect here: The lower a result is on the page, the fewer people click on it; and the fewer people click on it, the lower it falls. Perhaps helping unfavorable results fall down the page is an even more valuable tactic than many realize, as the fall has an echoing effect on the strength of the item.
Mitigating Factors: Intent Matters, Features Matter
Intent
It is not possible to group all types of searches together. People use Google to access many different types of information, and the type of search will have a great impact on the Click Through Rate.
For example, someone searching for a study on a research topic is a lot more likely to click through to a result than someone who is looking for a movie time.
Search Features
Google displays different results layouts with varying features for different types of queries. These can include:
Featured Snippets – These are boxes with dynamic information related to the specific search query. These are generally designed to provide a direct answer to the question being asked by the searcher.
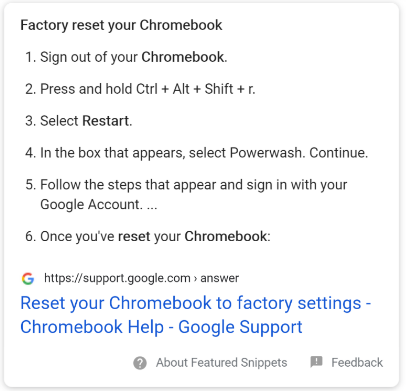
When a featured Snippet is displayed at the top of results, the #1 result loses 5.3% CTR.
However, results #2 and #3 actually receive a boost, rising to 20.5% and 13.3% respectively.
Knowledge Panels – These are sidebars that display information about a person, company, location, etc.
Knowledge panels are one of the most significant features that appear to affect CTR. When they are displayed, result #1 drops from a 28% CTR down to just 16%.
This result is likely one of the most affected by the fact that the Sistrix study was performed on mobile device searches. On desktops, this panel is on the upper right-hand side next to the organic results and is more easily ignored by searchers. On mobile, the panel displays the information inline with the other results – typically at or near the very top of the search page, and sometimes before any organic result is seen.
Sitelinks – Sitelinks are sub-results directing to other relevant results from a given site. They appear under the site’s main search result (typically the corporate homepage in branded searches) in Google. These links only appear for the #1 result on the page, and typically only for highly relevant domains with a clear content structure. Sitelinks tend to appear when Google perceives the intent of the search to be targeted towards a specific website or company.
When the #1 result displays sitelinks, the CTR jumps to a staggering 46.9%. The #2 and #3 slots drop dramatically to 11% and 5.6% respectively.
While this data seems to imply that having sitelinks greatly increases your click rate, it is important to note that search intent is likely a major factor in this statistic. In other words, search results that display sitelinks are those that Google interprets as likely looking for a specific website. Therefore, these searchers are far more likely to click through to that website – not necessarily because of the presentation in search but because of the implied intent of the query itself.
Similar to sitelinks, there are many other features that can be displayed in results, such as News, Video carousels, Social media boxes, Location boxes, and more. Generally, the data suggests that the more features Google displays, the lower the CTR of regular results becomes.
How can you use all this information?
It is important, then, to leverage all relevant search features: Companies can make sure their websites are optimized for featured snippets and sitelinks, claim their Knowledge Panels, and leverage other features like Google’s People Also Ask box wisely.
What information do your stakeholders learn on the search page before ever clicking through to your site?
Perhaps they already learned what they needed to from the Knowledge Panel or the Featured Snippet?
Maybe the question was answered by an FAQ on your site which ended up in the “People Also Ask” feature?
Does your content strategy aim to answer questions for stakeholders, rather than simply telling people what you wish to tell them?
Strategic, data-driven focus – controlling the things you can – is a key component of reputation management in today’s climate, and we predict that the importance of this component will only grow in the future.
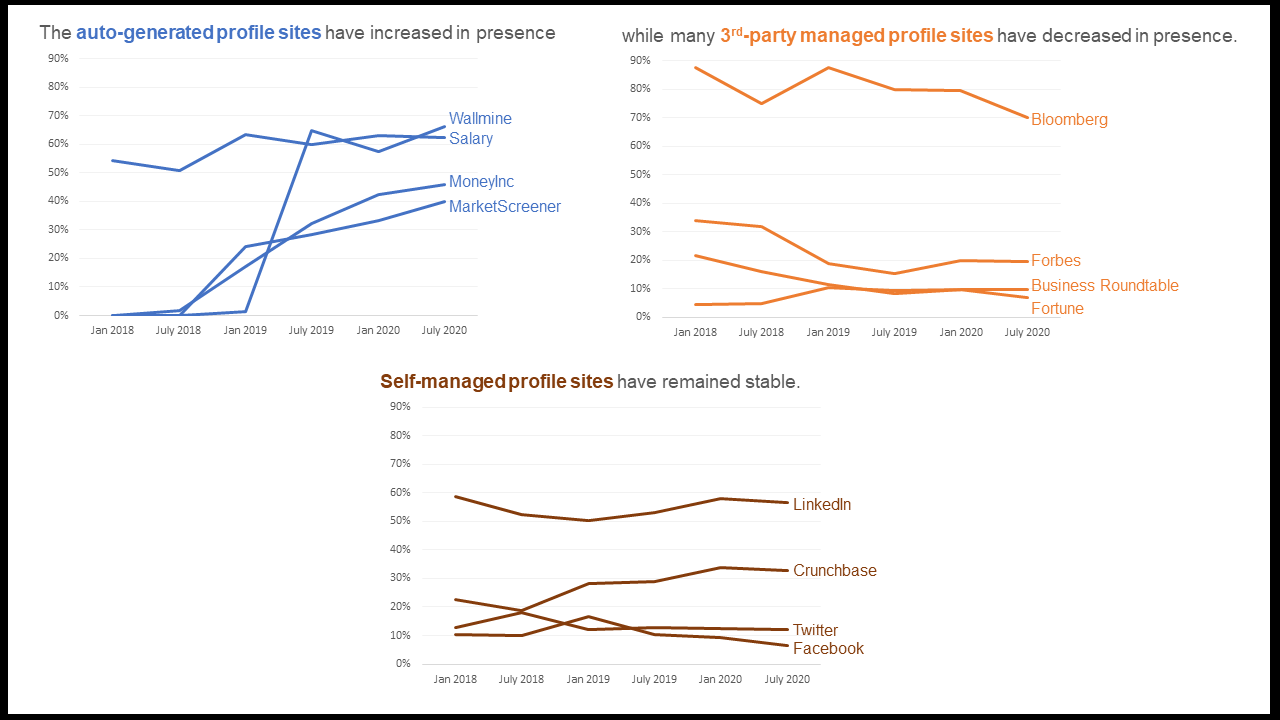
Just the Facts: The rise of auto-generated profile sites, and what that means about the direction of search
People like to do quick, basic research before engaging in business. As the go-to place for that research, Google’s page 1 has become a kind of dossier about people and brands. This is why the Knowledge Panel (the summary info that typically appears on the top right part of the Google search results page) has become the gold standard for quick stats of notable individuals. It’s also why the People Also Ask box, with its quick and easy question and answer format, has been pushed front and center by Google. It’s as if searchers have repeatedly said to Google, “Just the facts, Ma’am,” and Google has complied.
Typically, results for top CEOs will include their Wikipedia page, their company’s website, top news stories, and various types of profile sites, which provide a quick snapshot of facts for users.
(Note: Perhaps the most interesting data point for many searchers is CEO salary: we found this in a previous study we did on the People Also Ask box. 22% of all questions appearing for Fortune 100 CEOs relate to their salaries.)
We recently surveyed Google results for Fortune 500 CEOs over three consecutive years (on the same dates) to assess the changing prominence of different kinds of profile sites in their top results.
We found that self-managed profile sites – LinkedIn, Twitter, and Facebook (in addition to Crunchbase, which can be self-managed) – have remained more or less stable in terms of their prevalence on page one for CEOs.
At the same time, third-party profile sites, like Bloomberg, Forbes, Fortune, and Business Roundtable have slightly decreased in page one presence for CEOs over the years. Bloomberg, for example, appeared in page 1 search results for nearly 90% of these CEOs through early 2019; today that’s down to 70%.
The sites that have risen in prominence are auto-generated profile sites, which pull relevant information from multiple websites and databases to create a one-page dossier on executives. These sites, namely Wallmine, Salary, MoneyInc, and MarketScreener, have significantly risen in prominence over the years. Wallmine in particular saw a meteoric rise in 2019 – from appearing for just 1% of CEOs to 65% of them within that same year.
What is interesting about this trend toward automatically created “scraper” sites is that they don’t seem to add a whole lot of value. What are they doing that Google cannot do by itself? Google’s algorithm already tends to prioritize pages and sites that help it answer popular questions and meet the common need for quick facts. Google does this by crawling much of the internet and then displaying the best pages and data points.
When companies do the same type of summarizing, this can be useful to visitors…but only for a time.
Some years ago we saw the same dynamic play out with Answers.com. In order to answer questions people often searched online, that site scraped various authoritative sources and created answer pages – which ranked prominently for tens of thousands of terms. Eventually, though, Google applied a more sophisticated duplicate content filter, demoted Answers.com, found other sites that added more original value, and added its own “dossier” features as discussed above. Answers.com simply wasn’t adding enough value to last long term.
So while right now there are several automatically generated profile websites appearing for many prominent individuals, some of which can actually be managed to some extent (MarketScreener offers an option for a paid profile, for example), we predict that these sites will not retain their prominence long- term.
In our estimation, for a site to remain relevant and prominent in Google search, it needs to add unique value, providing information or an experience that other sites do not…and that Google can’t manage on its own with its own knowledge graph data.
Ideally, sites that want to go the distance should be filling a gap – providing some deeper answers to the popular questions people have, adding images or videos where those are missing to flesh out someone’s persona, or providing information in a language that is not covered.
Google is a reflection of what people want to see, and people seem to want to see a quick and comprehensive picture. Staying valuable will require a heavier lift for content writers and researchers. The robots – the automated content aggregators – will need to find some other, more helpful, work to do.
About the author:
Miriam Hirschman., Research Manager at Five Blocks, is driven by an endless supply of curiosity and a deep background in data analysis as she digs for the interesting stories behind the numbers. Because we believe in data and tools but believe in people even more, she reviews massive volumes of search results, seeking patterns and finding order in the often chaotic world of web search.
People Also Ask: How Brands Can Leverage Google’s Q&A
Google has learned that the”People also ask” (PAA) box format works well to satisfy queries. Google’s goal in PAA and other features is to make page 1 of search so comprehensive that searchers increasingly find their answers right there without having to click to another page.
We drilled down into our data to best advise our clients how this question-and-answer trend could help them reach their stakeholders more effectively. What we discovered enabled our CEO, Sam Michelson, to come up with some concrete suggestions for companies and executives, which he recently published in Forbes.
Here’s a summary of what we found out:
Here’s Sam’s advice for companies and CEOs, as originally published in Forbes:
Own some answers.
Owned sites are often a source of answers to common questions. Companies, following a best practices optimization strategy for their websites, can help those become a trusted source of leading information on the results page. This would include, for example, a robust FAQ section based on real research into what people are asking and providing answers in the area of your company’s expertise to capture the PAA for that question cluster.
Develop a presence on Wikipedia.
Google prefers Wikipedia pages in its results. It also relies heavily on Wikipedia for both PAA box information as well as the Knowledge Panel, the box on the top right of search which summarizes information about a searched brand or individual. It is therefore essential to work with the Wikipedia community to ensure your company (and CEO’s) Wikipedia pages are updated and accurate.
Maintain structured data.
The above findings also underscore the importance of maintaining structured, up-to-date data about yourself and your company online (i.e., Google My Business, Schema, Wikidata), as this information echoes throughout Google’s page one, especially for CEOs.
Target your earned media.
Since we know that the PAA box sources its answers heavily from certain business sites, it would be worthwhile, when working with PR companies, to try to place stories specifically on those sites.
Assessing what questions people ask, basing some of your content around those, and leading readers to the information you most want them to discover will be meeting your market where they are instead of simply telling them what you want to say.
With so much of the territory unchartable, companies taking control of what they can is essential. Using all available platforms to both ask and answer searcher questions, and taking them down a path that both satisfies their search and helps the company tell its story, is a win-win.
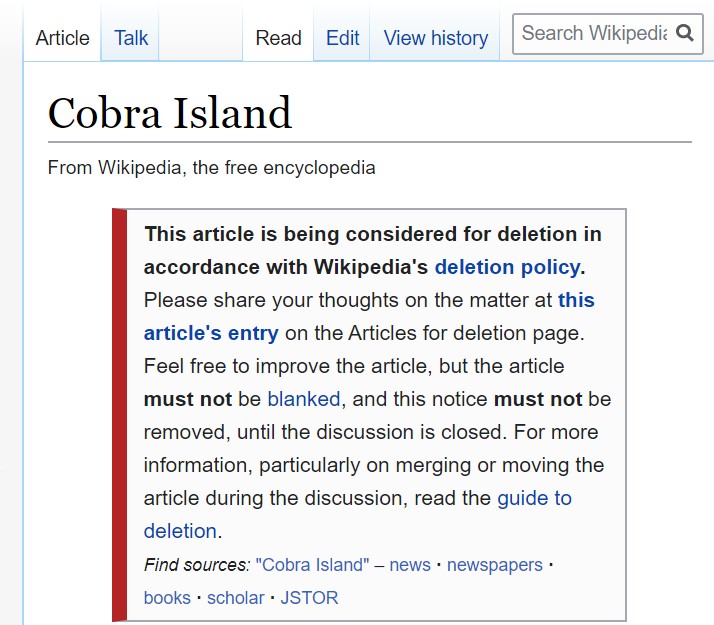
Your Wikipedia Article Is Up For Deletion. What Do You Do?
Your company or your CEO has a Wikipedia article. Suddenly, you notice a tag on the top of the article screaming that the article is about to be deleted. What happened? Why is the article being deleted? Will it actually be deleted? And what, if anything, can you do about it?
Why Would Your Article Be Deleted?
Before we discuss how the deletion process works, it makes sense to explain briefly why your article might be considered for deletion. There are straightforward reasons for this, including copyright violations, vandalism, a lack of sources, and obvious advertising.
There are more nuanced reasons as well, the most relevant of which is the question of notability. Not every topic belongs on Wikipedia, and Wikipedia has specific guidelines about what makes a person or company notable. For a topic to be notable, it needs to have significant coverage in reliable sources that are independent of the subject. There are other specific criteria as well, all of which are explained on Wikipedia.
The Deletion Process
If you use WikiAlerts, or you carefully monitor pages that interest you in another way, you will be alerted as soon as someone tags your article for deletion.
Wikipedia editors may go about the deletion process in one of three ways:
- Speedy deletion: A speedy deletion is proposed by an editor when they believe that the article so clearly does not belong on Wikipedia that a full discussion is unnecessary. There is a long list of criteria that would warrant a speedy deletion. The most relevant for our purposes include: copyright infringement, unambiguous advertising or promotion, and the recreation of a page that was already deleted through a deletion discussion. The person nominating it for speedy deletion will specify the reason in the deletion summary and can immediately delete the page. They don’t need to wait for any discussion or agreement. Boom, it’s just gone.
- Proposed Deletion: If an article doesn’t meet the very narrow criteria for speedy deletion, but an editor feels that it should be deleted and that it won’t be controversial to do so, they can propose it for deletion. This is a gentle deletion tag, because any editor can remove the tag if they have justification for saving the page. If the tag remains for seven days, the page can be deleted.
- Articles for Deletion (AfD): When an editor feels that deletion is appropriate, but that a discussion should take place about the topic, they will engage in the deletion discussion process. The editor will nominate it for deletion with the AfD tag and create a new page where the discussion will take place. Other users who monitor AfD discussions will be notified that this conversation is taking place. Typically, a deletion discussion lasts for seven full days and consensus is NOT based on a tally of votes, but on consideration of reasonable, policy-based arguments.
At decision time, a Wikipedia administrator who has not participated in the conversation will access the arguments and decide that consensus was reached to delete the page, that consensus was reached to keep the page, or that consensus wasn’t clear. If it wasn’t clear, the page may be relisted to generate more conversation, or a decision of No Consensus can be decided and the article kept.
So Now: What Can You Do?
The preferred way to deal with the issue of deletion is to avoid it in the first place. As we all know, an ounce of prevention is worth a pound of cure. It’s always best to prevent this situation from occurring by making sure there are many good media sources about your brand. Before a Wikipedia article gets written about your company or CEO, make sure that there is extensive, impartial online coverage.
But what if you have not avoided it, and now you stand at the brink of deletion?
- DO NOT create an editor and jump into the conversation if you have a conflict of interest. Wikipedia has very strict guidelines about getting involved in creating, editing, or defending any articles that you have any connection to without declaring that connection.
- You DO have the option of creating a COI editor and going onto the talk page to suggest additional references or content that might help other editors to add to the Wikipedia page and the conversation.
- In addition, you can actually join the AfD (Articles for Deletion) conversation as a COI editor and make a strong argument for the inclusion of your piece (as a declared COI editor), but you will not be allowed to vote on behalf of your article.
It Ain’t Over ‘Till It’s Over
If the article ends up being deleted, don’t despair. It’s possible that sometime in the future the company or individual will become notable enough for inclusion in Wikipedia. In these situations, the focus should be on strengthening your website, Facebook, LinkedIn and other online properties to tell your story the best way you can even without Wikipedia. If you believe, however, that you really are Wiki-worthy now, then you should focus on getting more reliable, third-party, independent coverage online. That’s the way toward proving your notability, which is the high road to Wikipedia.
The Day LinkedIn Disappeared from Google
On May 6th, overnight, about 273,000,000 LinkedIn results disappeared from Google search results.
We noticed it first, or rather – our technology did.
The below screenshot from our IMPACT analytics platform shows that LinkedIn typically appears on page 1 for “IBM,” but on May 6th — it disappeared completely.
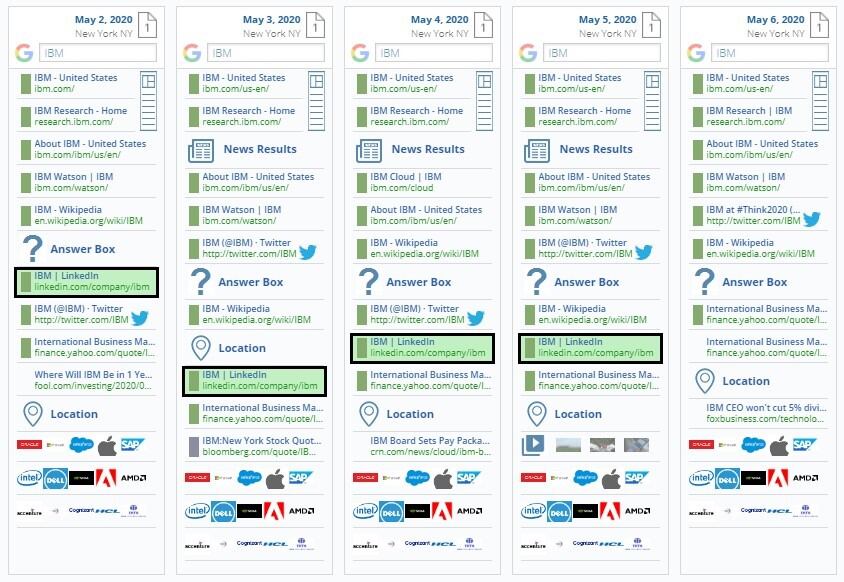
It was the same for individuals. Search results for “Mary Barra” (CEO of GM) showed that although she usually has LinkedIn as the first result after Wikipedia and her corporate bio page, on May 6th it was gone (replaced by a second link to GM’s site).

At the same time that LinkedIn disappeared from search results, the icon for LinkedIn also disappeared from the Knowledge Panel. For IBM it was replaced by a Pinterest icon. See before and after..
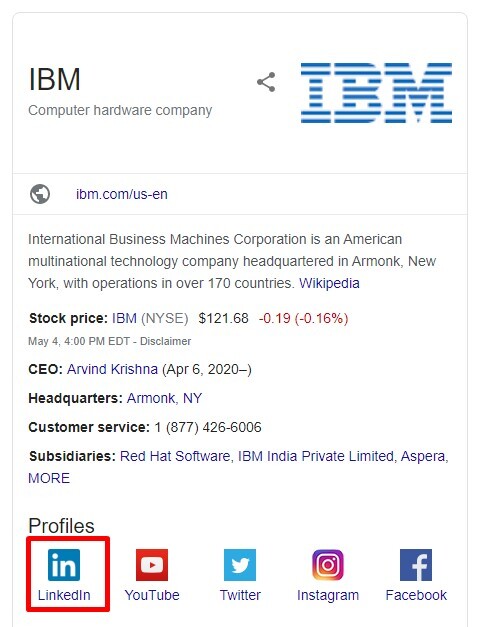
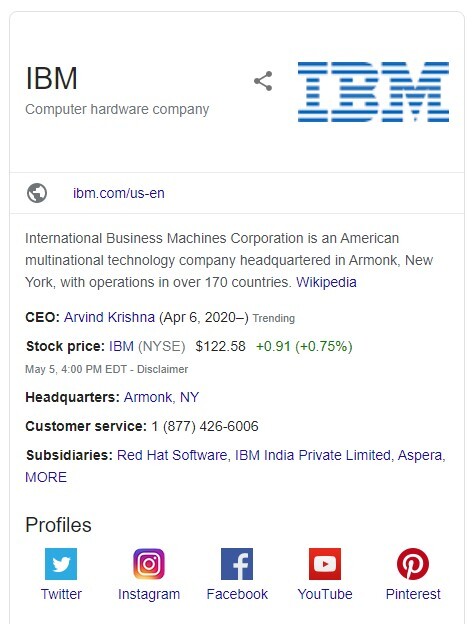
The LinkedIn disappearance was across the board.
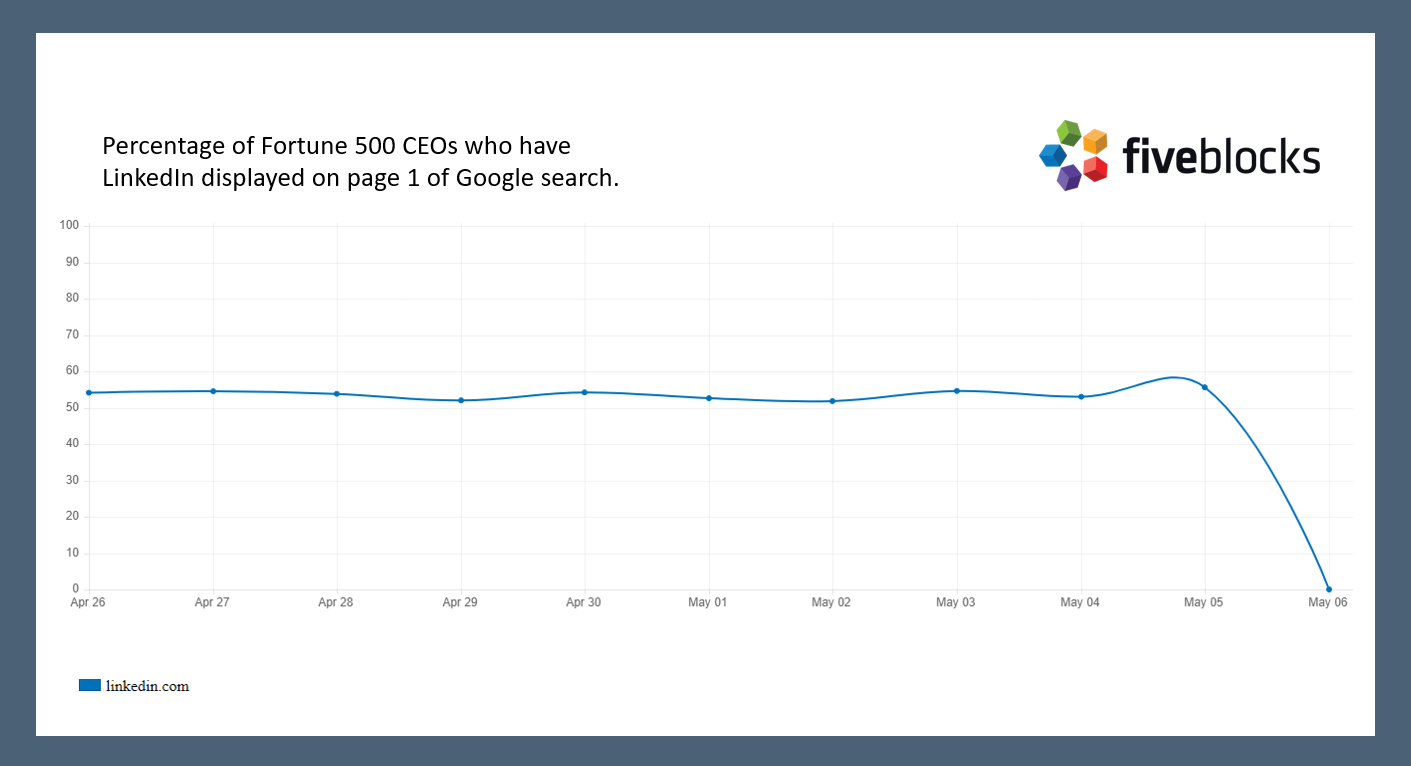
For example, we track the percentage of Fortune 500 CEOs who have LinkedIn displayed on page 1 of their search results.
Usually it is about 55%. On May 6th, none of the CEOs had LinkedIn displayed.
We did not know what caused LinkedIn to disappear, but we did know that the main site was not being included in Google’s search index.
In other words, LinkedIn had been de-indexed by Google.
A search preceded by “site:” shows all the pages within a domain that are in Google’s index. This search showed that no pages from www.linkedin.com were included in search.
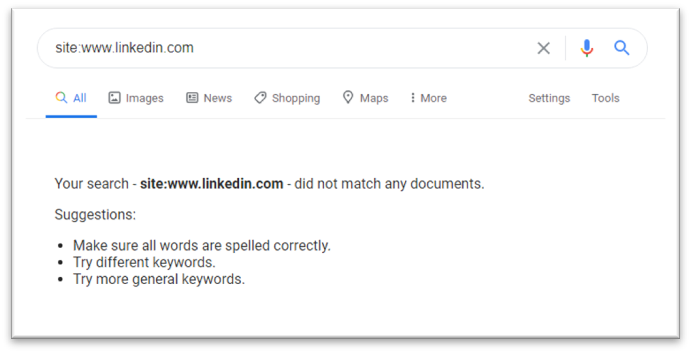
Here is what that search had previously looked like:
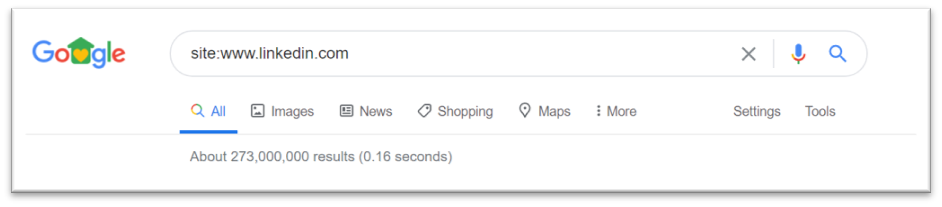
The pages still existed, and the site was still live. Someone who went directly to www.linkedin.com would never have noticed this search engine issue.
LinkedIn has country specific domains, which continued to rank in Google. For example, the French site still had all 23 million results appearing in search.
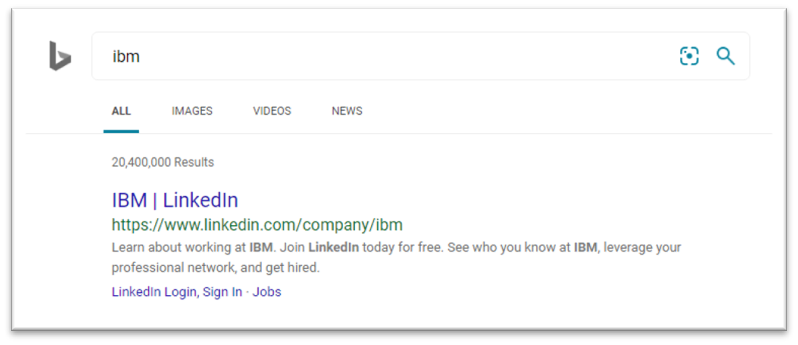
We also noticed that it was an issue specifically with Google.
On Bing, for example, LinkedIn continued to appear in search results.
Initially, we were unsure of the reason for LinkedIn to be dropped from results. It seemed unlikely that Google would choose to entirely remove such a major site. According to Similarweb, LinkedIn is the 26th most visited site in the USA, and over 23% of visitors to the site come via a search engine.
In the past, we have seen the Google algorithm demote sites for various reasons. However, we have never seen Google completely remove a major domain from search before.
It also seemed unlikely that LinkedIn would choose to remove itself from Google search.
Unless it was a mistake.
So as one does, we turned to Twitter.
First to notice this massive shift in search results, Five Blocks tweeted about it, looking for answers. SEO leader Barry Schwartz wrote about it on Search Engine Roundtable, and tagged two of Google’s spokespeople in a tweet.
A short while later, John Muller of Google tweeted a PSA which didn’t mention LinkedIn directly, but seems to have provided the clue to what had happened.
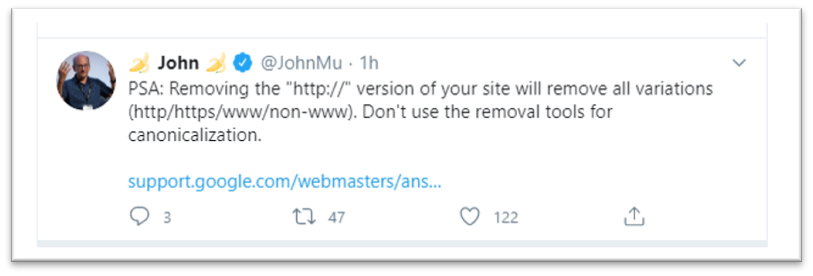
We understood this to be a cryptic message to LinkedIn, telling them that someone accidentally clicked a button in Search Console which removed the site from Google search.
Less than 24 hours after LinkedIn fell out of Google, it returned.
The graph below shows that very quickly, the percentage of Fortune 500 CEOs who had LinkedIn displayed on page 1 returned to about the same point it had been previous to May 6th.
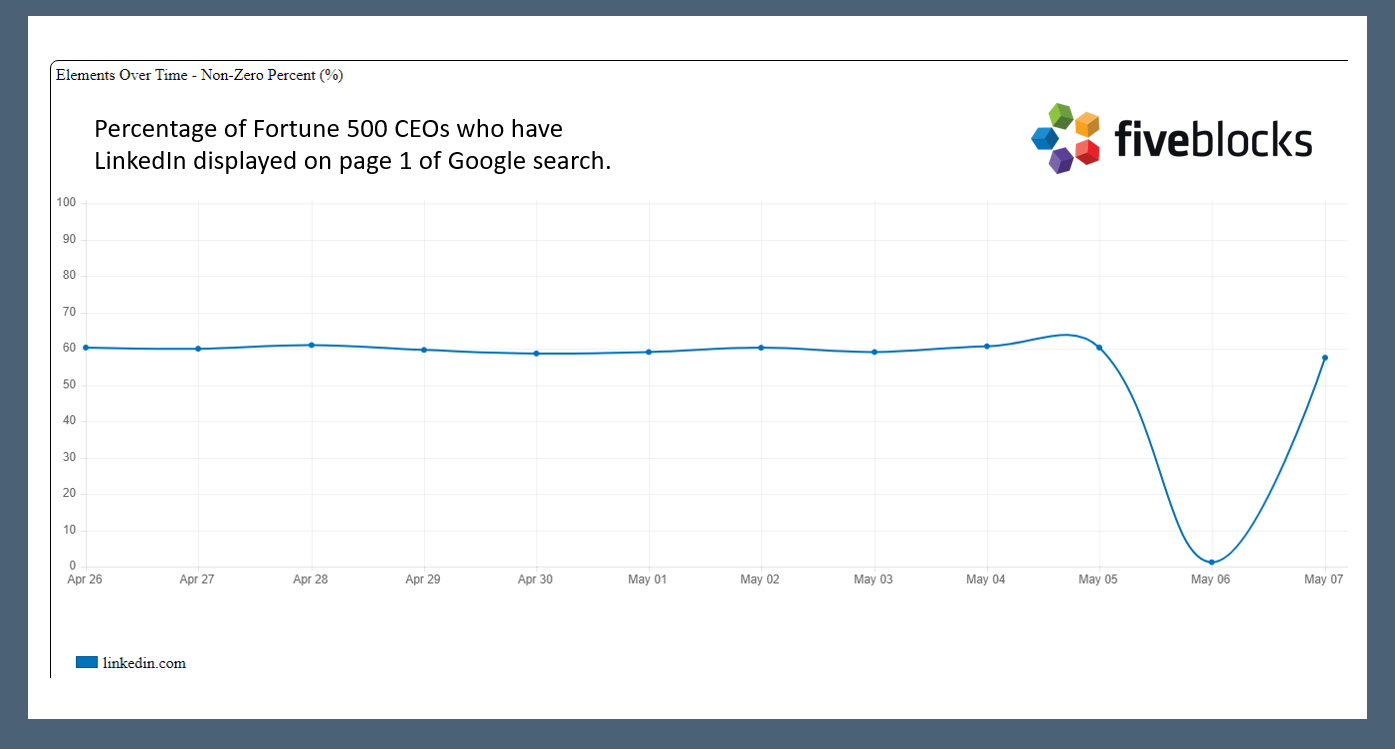
IBM‘s and Mary Barra‘s results both returned to their normal state.
All’s well that ends well.

Key Takeaways
The LinkedIn disappearance was a perfect opportunity for Five Blocks and our clients to be reminded of some fundamentals of online reputation management.
Here are some of our takeaways:
- It is essential to continue to monitor results every day. Someone, somewhere, accidentally clicking the wrong button can have an enormous, unexpected impact on search results.
- When LinkedIn does not appear in search it can potentially make results noticeably worse. Conversely, having LinkedIn in search can make results much better. That’s why we encourage clients to create and optimize LinkedIn and ensure that their profiles are indexed.
- We cannot rely too heavily on any one domain when working to improve search results. Even prominent and well-established domains can sometimes let us down. The more we use a variety of tactics and tools to enhance reputation the more secure the results will be.
- The Google Knowledge Panel is totally dynamic. Each time a search is made, Google checks the index to know what to display in the Knowledge Panel. As soon as LinkedIn was de-indexed, it disappeared from the Knowledge Panel. And as soon as the site was re-indexed, the icon reappeared. So, just because the Knowledge Panel looks the way it does now, does not mean it will stay that way tomorrow.
When Google Must Not Get the Answer Wrong
You have probably noticed that Google has been steadily elevating the prominence of the “question and answer format” for some time.
Google first introduced the People also ask box in 2015. For a while, it was a low-profile feature, often appearing midway or lower down the first page. As with virtually all new features, Google did extensive testing to ensure they are useful to searchers.
By early 2017, the feature began rising in prominence, including appearing for 10-15% of Fortune 500 companies. In November 2018, the People also ask box started appearing for about 80% of companies and grew from there, today appearing for over 90% of the F500.
It appears that Google has figured out not only the kinds of questions people often ask, but that people appreciate the format as an efficient way to find information quickly.
This new format often presents questions we would have been unlikely to ask ourselves (a search for ‘gaming fingers’ brings up both ‘how do you play the game number fingers’ and ‘can playing video games cause trigger finger’), and returns answers with varying degrees of authority, simply because they seem to match well.

That is…unless getting the right answer is a matter of life and death. Then Google interrupts its regularly scheduled algorithms to present results much differently, cutting straight to the most authoritative answer. Nothing brings this home more clearly than the way Google is handling the COVID-19 crisis.
What is going on? Let’s take a deeper look.
The Paths of Search
When you search online, Google does quick triage:
If there is one unequivocal answer – as in ‘Who is the Prime Minister of Canada’ – that answer will generally be delivered in the form of a Featured Snippet or Knowledge Panel. A question and answer box will appear below this, with related questions, answered by various sources.
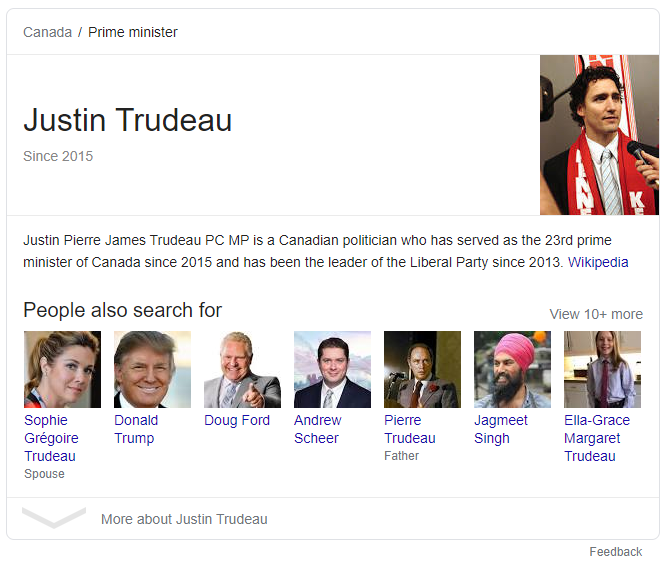
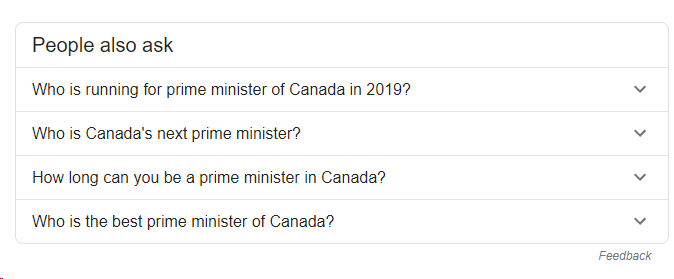
If your query is something less clear, like “gaming fingers,” Google’s algorithm is not sure of your intent, so it will generally provide a variety of different results to help disambiguate what you are trying to find; you can pick a specific path or decide you know enough from what you’ve read on the search page.
The People also ask box captures frequent intentions – and Google figures that your intent is likely to be similar to one of them.
But what happens when there’s a lot riding on the answer?
When the answer is crucial, like in an impending weather emergency or a search related to suicide, Google overrides its own algorithm – and provides answers that have the greatest likelihood of keeping you safe.
A Tornado warning in the searcher’s area appears in red at the top of the page when they do a weather-related search. In the case of a suicide-related query, a toll-free hotline number appears in a large font at the top of the page, with the text ‘help is available.”
In these cases, even if Google is not sure what you are asking — and even if there are probably a variety of accurate answers to a question like ‘how to kill yourself’ — Google will err on the side of caution.
In these cases Google sacrifices variety, balance, considerations of the searcher’s own history, and any other elements of its algorithm for the most direct route to possibly saving a life.
The Coronavirus Connection
In our current moment, searches for coronavirus or COVID-19 bring up an expanded knowledge panel — almost a mini- site — featuring symptoms, prevention, treatments, and statistics. The area is branded as a red ‘COVID-19 alert’, and all information is provided only by highly reputable sources.
The People also ask box is farther down the page than normal, and is referred to as “Common questions” instead; answers are sourced from highly authoritative sources – most prominently, the CDC.
Along with this new way of presenting coronavirus answers, Google has a new initiative to help medical organizations optimize their sites, so that their information appears prominently in Google searches, and populates the results for these types of medical questions.
SEO Roundtable has summarized the initiative here, in which Google has provided guidance for health organizations on:
- Mobile optimization
- The importance of good page content and titles
- How to analyze the top coronavirus related user queries
- How to add structured data for FAQ content
While it would obviously be easier for Google to simply give all worthy health organizations more weight in the algorithm (using some sort of ‘authority score’), it seems to prefer that these entities assert their expertise organically.
Even more “interventionist”: As of end March, Google began heavily prioritizing local COVID-19-related results, giving more prominence to local publishers as each country began developing unique approaches to fighting the virus.
Balancing Act
It seems that Google is scrupulous about accuracy only when there is a specific unequivocal answer, or when it thinks there might be a case of life and death. Maybe these are the only times Google won’t be called out for using influence in unfair ways?
Google’s opening gambit with health organizations, a half step between the democratic question and answer format and the tightly controlled emergency format, might be an interesting way forward in areas where more authoritative answers may not be immediately crucial, but would be appreciated by users – like nutrition or child-development.
In fact, all companies and professionals, following a best practices optimization strategy (titles, query analysis, FAQ content, etc.) can help establish their expertise on the results page. By assessing what questions people ask, and by answering them in the most relevant and easily understood way, companies may be able to make sure that the answers to the questions people ask are answered by their very own legitimate expertise.
It may not always be an emergency to get the answer right, but users would surely appreciate bumping into more true experts on their search paths.
Presidents’ Day: Google’s Complicated Relationship with Alexander Hamilton
We think you will agree that the best US president to focus on this Presidents’ Day 2020 is Alexander Hamilton. You know who we mean: “The ten-dollar founding father without a father,” as he is called in Lin Manuel Miranda’s musical, Hamilton.
Except for one small detail. Hamilton was never president. Nope, not even a little bit. And yet a lot of people, and at least one extremely important non-person, think he was.
Can You Answer This Question?
We conducted a (very) informal survey among our friends and asked them to name a few US presidents. Everyone listed Washington and Lincoln. Almost all of those asked also said, incorrectly, Hamilton.
Our small group of ill-informed respondents is not alone. According to a 2016 study, “about 71 percent of Americans are fairly certain that Alexander Hamilton is among our nation’s past presidents.”
In fact, most Americans are more confident that Hamilton was president than they are about half a dozen actual presidents.
But we shouldn’t shame people who either weren’t around when that Got Milk? ad came out, or can’t afford hundreds of dollars for a ticket to a Broadway show, for not knowing American history, can we? Or maybe we can, since there is a great source of information available, entirely for free, at the tips of their fingers.
Or is there?
Go Ahead and Google It.
We are referring to the internet, of course. We have outsourced the data part of our brain to the all-knowing Google.
So, who (is Google a “who”?) better to correct our error about Hamilton? Let’s have a look at what Google has to say about our beloved President Hamilton.
If you search for “President Hamilton,” Google does not display a screen saying, “No, you are mistaken.” Rather, it disappointingly encourages the error in its “People also ask” section, with the following four questions (sic):
What number of president was Alexander Hamilton?
Was Alexander Hamilton president of the US?
What year was Alexander Hamilton President?”
Which president died in a duel?
Even when you look at the answer to “Was Alexander Hamilton president of the US?” Google seems confused and doesn’t give you a straight yes/no answer.
Similarly, the answer to “What year was Alexander Hamilton President?” is not the correct answer of “never,” but rather somewhat avoidant:
Fewer people search for “President Hamilton” than for “Alexander Hamilton.” There was a huge spike in the number of searches for “Alexander Hamilton” around the time the musical came out. More and more people wanted to know who he was.

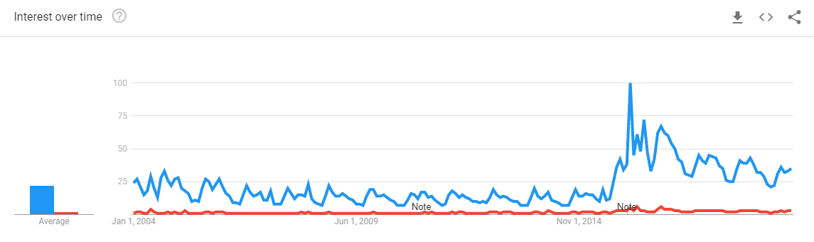
Indeed, things are marginally better if you search simply for “Alexander Hamilton.”
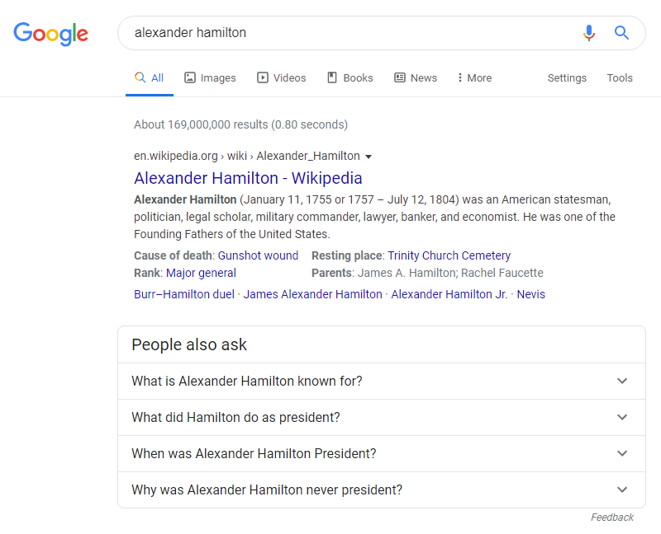
The second and third questions still imply that he was president, whereas question four actually confirms that he was never president.
At least two of the questions imply that Hamilton did serve as president.
As the lyric from the musical goes: “You have no control who lives, who dies, who tells your story.”
Enter “President” Franklin

Google is definitely telling its own story when it comes to Alexander Hamilton. But it’s not just about Hamilton.
If you would be so foolish as to search for “President Benjamin Franklin” (as we were) you would find that Google also fails to set you straight.
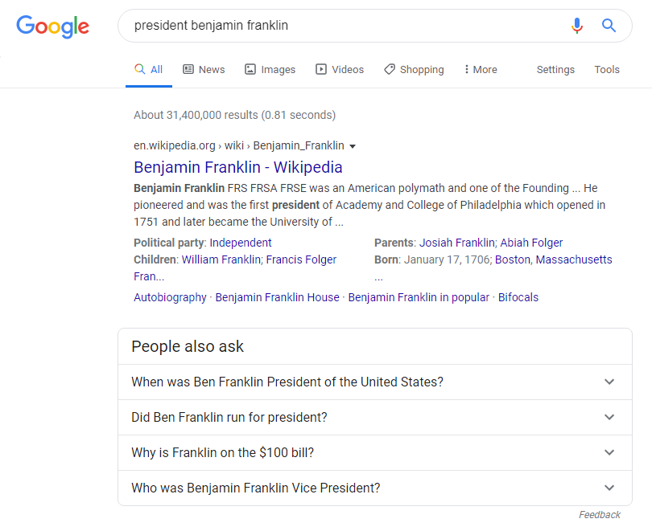
We are so used to Google supplying us with information, that we often trust it unquestioningly. Often, that works out fine.
If you ask Google “what is the capital of bolivia”
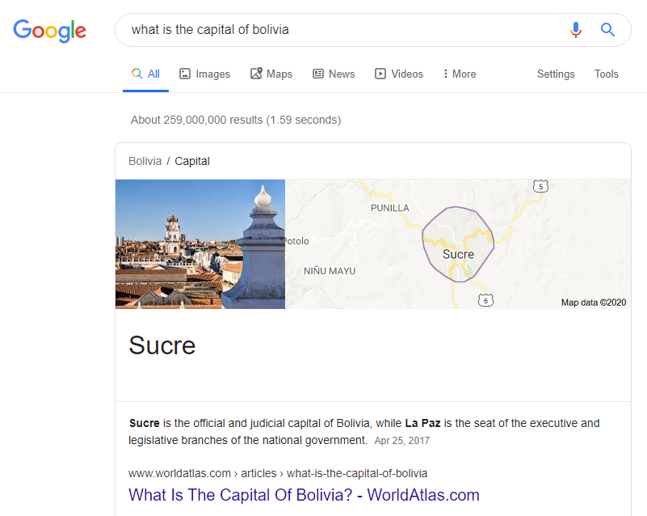
Or, “who was the actress in casablanca?”
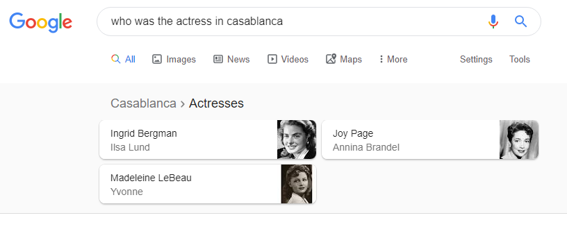
You get a clear answer.
But don’t ask Google, for example, “does Australia exist” since only one result on the page gives the correct answer; Australia does, in fact, exist.
In short, it is up to users to carefully examine each search result, taking responsibility not to outsource the thinking parts of their brains in addition to the data parts.
And just for clarity’s sake, Alexander Hamilton, although a really interesting guy with a talent for rap, was never the President of the United States.
Wikipedia’s 2019 Trends: Entertain us, and maybe we’ll learn something
Wikipedia recently released its Most Viewed Articles for 2019. The report is an interesting window into what’s on people’s minds. It comes as no surprise that death comes in at #2 (deaths in 2019 was a page viewed by nearly 40 million people). Number one? The Avengers movie page.
English-language researchers are not all Hollywood-centric in their curiosity — a list of Bollywood films in 2019 comes in at #21, Ronaldo at #34, Messi at #82, and an article on the 2019 Cricket World Cup at #63. However, it’s American pop-culture, and culture-inspired curiosity, that dominate the top 100.
Entertain (and Educate) Me!
In fact, more than half of the top 25 articles are related to film, television, and entertainment. Superhero movies, including all three Marvel films released in 2019, got significant traffic, as did three separate Game of Thrones entries.
More encouragingly to the academic-minded readers, many of the popular articles are historical events and personalities popularized by dramatic reenactments. The lists includes pages on the Chernobyl disaster (featured in Chernobyl, the HBO mini-series); Queen Elizabeth II and various other members of the royal family (The Crown, a Netflix original); Ted Bundy (Conversations with a Killer on Netflix); Charles Manson (in Once Upon a Time in Hollywood); and the Central Park jogger case (dramatized in the Netflix miniseries When They See Us.)
These pages (as well as most pop-culture related pages) were overwhelmingly searched on mobile.
Somebody to Love
Freddie Mercury is #5 on the list; Bohemian Rhapsody, the story of his life and band (Queen, #46), raked in 13 awards in 2019. The actor portraying Mercury, Rami Malek, came in at #50. The box office hit brought in $903 million internationally and was the most watched movie at home in 2019. Comparatively, the movie about Elton John, Rocketman (released in 2019), won only three awards in 2019 and made (only) $195 million globally. Sir Elton comes in at #43, closer to Malek than to Mercury.
American singer and songwriter Billie Eilish ranks an impressive 10th on the list, and is, in fact, the only living person in the top ten. She is the youngest musician (at only 18) to have a hit song on the Billboard 200 list, and has received so many awards and nominations that these merited a separate page.
Politicians, Not So Much
All these cultural icons and entities didn’t leave much room for politicians, most of whom got bumped down the list compared to prior years. President Donald Trump ranked at #20; he was #15 in 2018. Some 3.5% of the current U.S. President’s views came in on December 19, 2019, the day after his impeachment.
In 2008, former President Barack Obama was #1. In 2019, he was #83.
The only other living politicians to make the list were Boris Johnson, Alexandria Ocasio-Cortez, and Kamala Harris.
Get with the Program
Each year, various technical information, protocols, and companies find their way on to the list. In 2019, Simple Mail Transfer Protocol (SMTP), HTTP 404, Null (SQL), and F5 Networks all made the list.
Incidentally, these technical articles, the one on the Bible, and the article on Wikipedia itself, were among the only articles overwhelmingly viewed on desktops. It is understandable that programmers would be working on desktops; conclusions about the other pages are tempting to guess, but harder to draw.
At the crossroads of pop-culture and tech, YouTube, TikTok, Google, Facebook, Elon Musk, and Jeff Bezos all made the top 100.
Apple’s absence is duly noted.
Who Writes This Stuff Anyway?
Who are the people producing Wikipedia’s information? Wikipedia’s army of 38,170,346 registered editors (that’s just English!) in addition to countless edits made anonymously, that’s who.
While Wikipedia’s articles can be edited by anyone, in reality 1% of the contributors are responsible for roughly 70% of the content. A relatively small number of editors are making significant amounts of edits to new and existing pages.
Launched in 2001, Wikipedia has quickly become THE open source collaborative project for global knowledge. It is among the world’s leading websites, so it isn’t surprising that its own entry ranks #3.
This is the year that was: We are overwhelmingly curious about popular culture, and luckily, a lot of popular culture makes us curious about the real world, as well.
Let’s Talk About It: How Wikipedians Resolve Their Problems
Wikipedia’s “Talk pages” are a vital resource, not just for Wikipedia editors, but for anyone who wants to understand human interaction among strangers who share a common goal.
Wikipedia users know that the crowd-sourced, online encyclopedia is the product of the collaboration of thousands of editors. What most readers probably don’t realize is that the real meat of the encyclopedia takes place on the back pages – where the Talk page serves as a kind of teachers’ room / Hyde Park hybrid to hash out both minutiae and fundamental differences in approach. (When a disagreement arises among editors about specific content in an article, the editors step back, refrain from further edits, and engage in a discussion about how to proceed, until consensus among the editors is reached.)
This collaboration is invisible to readers unless they look behind-the-scenes: Every article has its own Talk page, easily accessed by clicking on the “Talk” tab on the upper left corner of the page. Editors are expected to always be civil in their remarks on Talk pages, and to always assume good faith on the part of other editors. It does not always go down that way.
“Because it’s there.”
Most of the time an in-depth discussion of edits is unnecessary. Edits are usually straightforward and can be concisely explained in the edit summary box right before an edit is saved to the page. From time to time, two editors can even discuss their differences right in the edit box, where those differences can often be resolved relatively quickly and painlessly. (Those edit summaries are immortalized on the “History page,” which is found on a tab on the upper right side of the Main article space.) If the dispute, however, is complicated or the differences are large, the editors will need to take the discussion to the Talk page.
The Talk page is the hearth and home of Wikipedia collaboration. Editors go to the Talk page to explain larger, perhaps less obvious, and/or potentially controversial edits, with an explanation of why the editor made that change. The editor isn’t asking permission; rather the explanation is a declaration of intent, as well as an invitation to anyone who might disagree with that edit to state any objections.
Take the following polite and somewhat humorous example:
On the George Mallory article’s Talk page, a discussion ensued about whether this article should be included in the category for “disappeared persons.” One editor held that just because Mallory’s body was eventually found does not change the fact that he had ‘disappeared’ for 75 years. The other editor argued that the Wikipedia category called ‘disappeared persons’ is only for those who have not (yet) been found. One editor suggested creating a new category called “formerly disappeared” or perhaps “disappeared and found.” A third editor was called in, explaining that the intent of the category was for people who are “missing, remains not found.” A consensus was therefore reached asserting that for 75 years Mallory was considered a “disappeared person,” but as soon as his body was recovered, he could no longer be included in that specific category.
Rules of engagement
Of course, overzealous Wiki editors can sometimes turn Talk page discussions into battles that can become quite contentious: not recommended for the squeamish or faint of heart. Foreseeing the potential for ugly name-calling and other rude behavior, a compilation of rules has been developed which editors are advised to abide by on the Talk page; if disregarded, editors can be punished with exile. Miscreant editors can either be barred from specific articles where fellow editors have deemed them disruptive, or from the entire encyclopedia, if their unscrupulous actions have wrought more widespread havoc. Bans can be anywhere from a few days, to weeks and even months. Unrepentant vandals can face permanent exclusion from the website. The following are some of the rules that must be followed at the risk of a reprimand at best or permanent expulsion at worst if they are ignored:
- Communicate clearly: Make an effort to be clear, friendly and willing to explain why you have a certain opinion.
- Stay on topic: Stay focused on how to improve the article. Do not discuss irrelevant subjects.
- Do not discuss the editing process in general: There are other places on Wikipedia for those meta-discussions.
- Be positive: Talk pages are not for criticizing, bullying, or venting.
- Be objective: Easier said than done, but editors must not argue their own personal point of view about controversial subjects. Always ask “what do the sources say?” And “are those sources reliable?”
WP:CIVIL
This list only just begins to touch the tip of the iceberg of advice on how to remain civil on Wikipedia’s Talk pages. Despite the long list of guidelines, sometimes discussions can get out of control. Most of the time the guilty editor will first be gently rebuked and asked to cease and desist.
One such case happened during a discussion of whether the reasons for the financial failure of the Airbus A380 were being whitewashed. Reigning in the offending editor, another editor stated:
“Instead of making sweeping accusations, and “guessing” about the history, how about simply making some constructive edits to the body of the article to incorporate the information you believe to be missing. (You may well be right that the information is worthy of inclusion, but adopting a more WP:CIVIL tone in your comments here would do no harm whatsoever).”
The errant editor did not exactly apologize, but he did take the offered advice and refrained from any additional rude or sarcastic remarks.
Only when friendly persuasion or outright threats fail, will an editor be banned. In one fascinating case, an editor, who seems to have had an anger issue, banned himself after admitting to engaging in frequent bullying and rude behavior. (For the entire statement, which is truly remarkable go here.)
Sometimes even editors with the best intentions and the most polite and respectful behavior hit a wall and still cannot come up with an acceptable consensus about how to proceed. Wikipedia has several mechanisms that editors can turn to for help resolving these disputes.
Cheap thrills or the meaning of life?
Talk pages are a vital resource, not just for Wikipedia editors, but for anyone who wants to understand human interaction among strangers who share a common goal. Usually the length of a Talk page, the number of archived pages, the tone, and the timbre of the discussions are a direct corollary to how important the subject of that article is in the popular mind and in the prevalent zeitgeist. Many of the articles that have the liveliest Talk page discussions are about issues of vital concern to leaders, thinkers, and the general public
Talk pages at their best are fascinating; the pursuit of cooperation, compromise, and common purpose that unfolds on Wikipedia Talk pages are a window into the mind of the community working hard to create an entirely abstract edifice of knowledge, which is the foundation of human culture, and the cornerstone of our civilization. Every excellent article that is forged in the Talk page furnace creates another brick in that edifice of human knowledge.
For more information:
The Wikipedia Index: The Edits that Matter
We’ve noted before how important a Wikipedia page is: 98% of Fortune 500 companies have their Wikipedia page ranking in their first page of Google results. Previously (here and here), we examined the sheer volume of edits made to Fortune 500 companies’ Wikipedia pages.
But what is the nature of these edits? What kinds of changes are being made by Wikipedia’s many editors, and which ones should you care about most?
It turns out that the vast majority of all edits to Fortune 500 company pages are just one of four types – text, infobox, links, and references. Text and infobox changes are the most crucial.
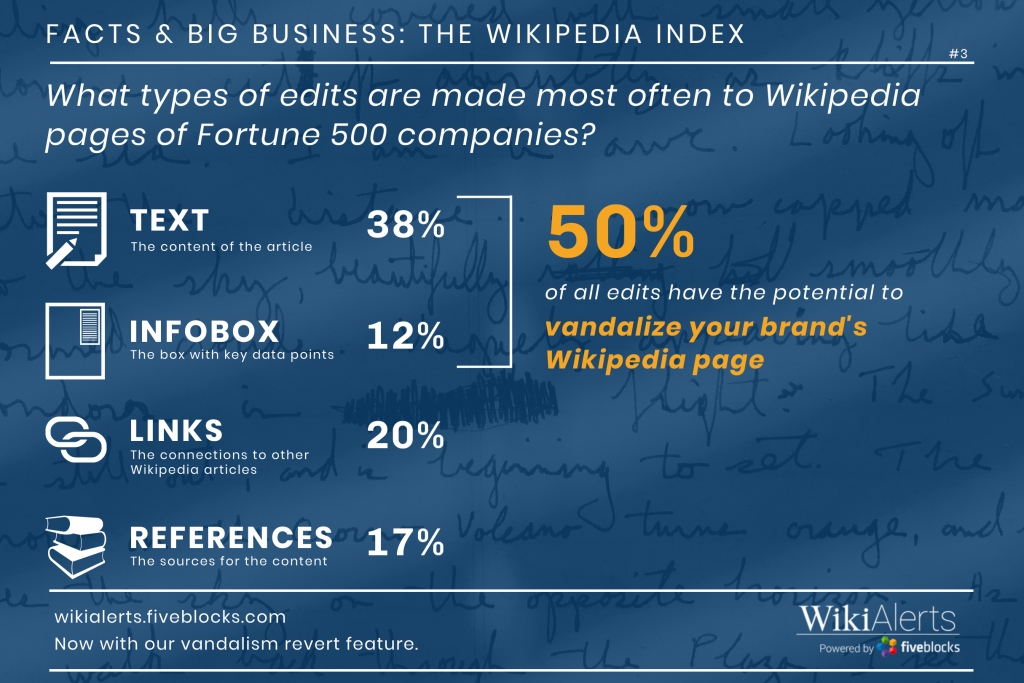
Edits to text include changes, additions, and deletions of any text in the body of the article. This content is obviously what readers come to a Wikipedia page to see; what many don’t realize is that it’s also where Google pulls pieces of its search results.
Therefore, changes to text on a Wikipedia page often become incorporated into both the search page results and the knowledge panel (Google’s data summary box on the right side of the page).
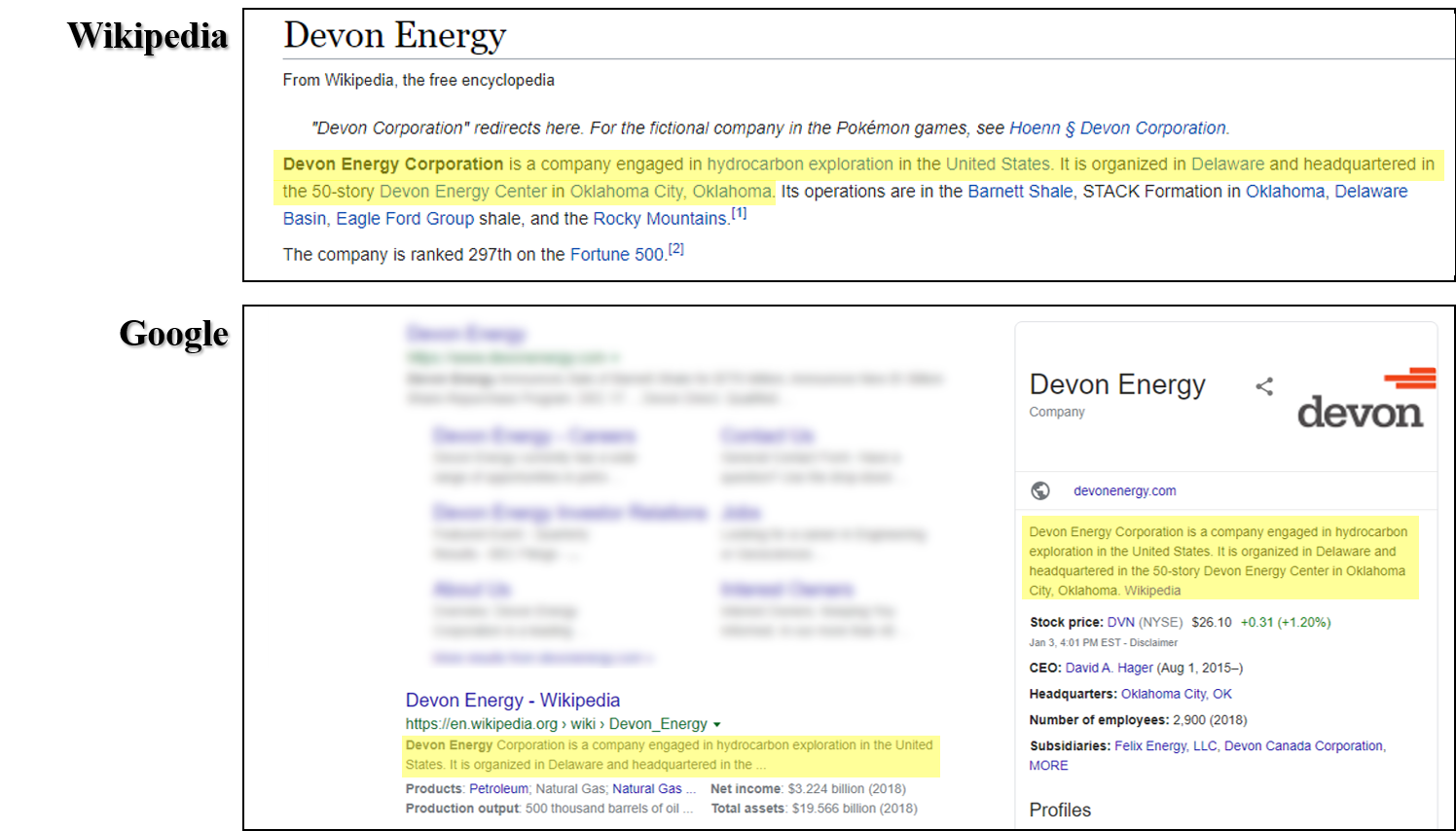
In some cases, this happens as soon as an edit is made, creating an opportunity for vandalized text in Wikipedia to show directly in Google. We wrote about that here.
Another key component of a Wikipedia article for a company is the infobox. This is the box on the right side of a Wikipedia article that gives a synopsis of key points about the company. Critically, Google often pulls points directly from the infobox into its own knowledge panel.
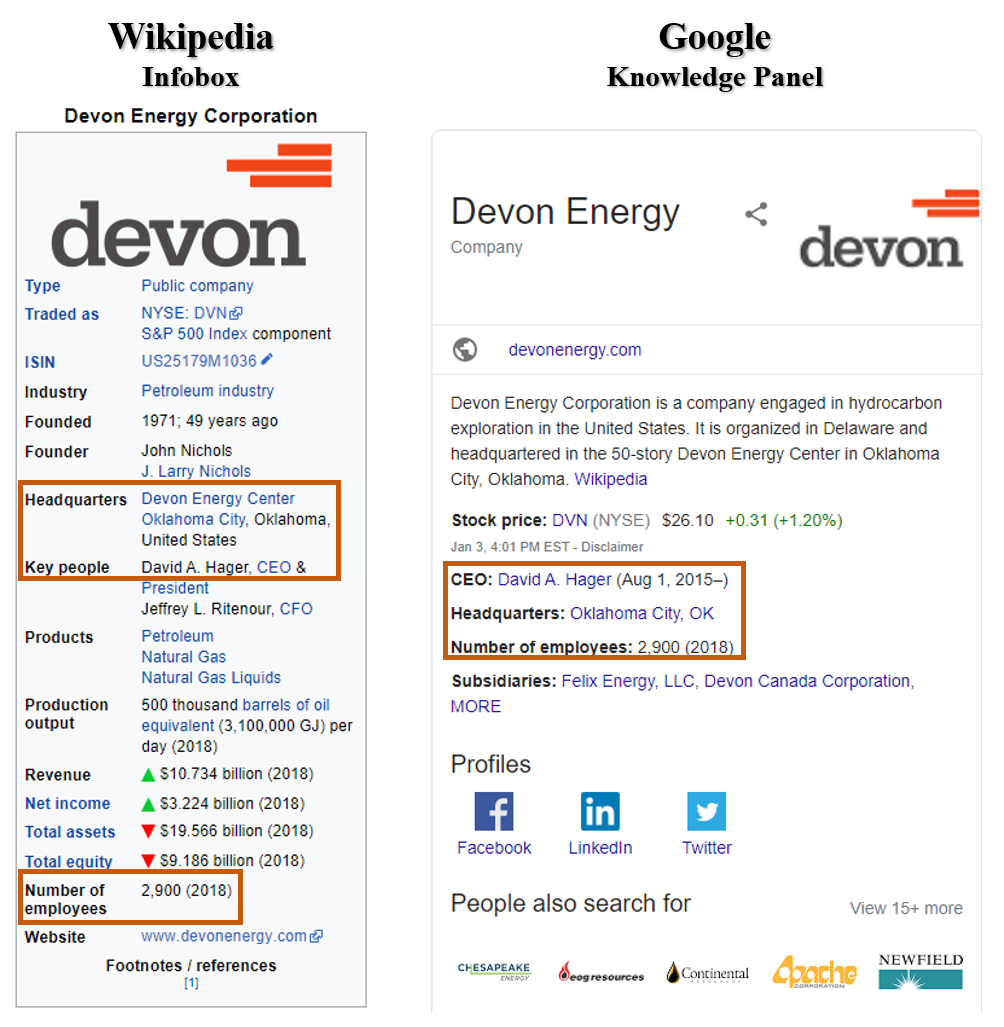
Don’t Panic, But Do Pay Attention
Google and Wikipedia are two of the most visited websites in the world. When people search Google for information about a person or company, their answer on Google’s search results page often comes directly from Wikipedia.
Whether a company’s page is edited with malicious intent – vandalized – or simply updated with incorrect information, the strong connection between Google and Wikipedia means that edits within Wikipedia have ramifications for a company beyond just Wikipedia.
When someone edits the body of a Wikipedia article, that change may be picked up by Google right away, or it can take a few days. This sometimes allows other editors to undo or remove vandalized text before it ever makes it to Google. However, when an edit is in the first sentence of the Wikipedia article, Google picks up the change immediately, making such edits highly risky for the company or person. This can be the case also for edits made to the infobox.
Companies, brands, and individuals with a Wikipedia article about them need to be vigilant about continuously monitoring their Wikipedia pages for any edits. That way, they can be on top of any changes to these pages that don’t convey an accurate picture and, most importantly, take steps to remove these changes when necessary.
Trash Talk in the Edit Field: The Vandalism Wars
For real sports fan trolling, center court is Wikipedia.
Sporting events in the 21st century are played both on and off the field.
As highly paid athletes compete for fame and glory on televised fields and courts the world-over, an alternate set of teams compete in the shadows.
Fighting it out across cyberspace, on social media platforms, are the fans who mainly exercise their fingers.
The victorious show no mercy to the vanquished. They make memes mocking fumbles and celebrating touchdowns. What’s the point of your team winning if you can’t rub it into the face of those crushed and humiliated in defeat?
A surprising venue for this testosterone-driven trashing of players, umpires, and coaches: geeky Wikipedia.
Wikipedia, trusted as an authoritative source by most of the 1.6 billion people who use it monthly, has become a rather likely spot for good old hooliganism. Appearing at the top of page 1 in search results for many terms, yet editable by anyone, it is a most appealing target for vandalism: People will see what you scrawl.
However, there is a lesser-known, but more significant, consequence of vandalizing a Wikipedia page.
Vandals change Google.
Here’s a story.
Recently, the Patriots were crushing arch-rival NY Jets, and fans were looking for cyber blood.
And it was then that Patriots fan Pvega789 made his move. He logged onto the Jets’ Wikipedia page, and changed the lead sentence of the page to read:
“The New York Jets are a professional American football team based in the New York metropolitan area and owned by Tom Brady and the Patriots’ Defense.”
(Get it? “Owned?”)
Unknowingly, editor Pvega789 was also altering Page 1 of Google search results.
The Knowledge Panel that appears on the top right of Page 1 for a search usually takes its text directly from the opening sentence/s of a Wikipedia Page.
As Pvega789 saved his edit, Google updated the Knowledge Panel for the Jets virtually instantaneously, quoting the first sentence from Wikipedia verbatim.
As if that weren’t humiliating enough for the Jets, another anonymous editor went in 15 minutes later and corrected what he (or she) described as a “typo.” Now both the entry and Knowledge Panel read:
“The New York Jets are a semi-professional American football team”
Within a minute the vandalism was all reverted by an administrator, who also added protection to the page to temporarily prevent further vandalism. The Knowledge Panel returned to normal.
When the vandal has a sense of humor and the damage is reversed quickly, we can all have a chuckle about it. Like this edit made to a page about a martial arts event.
But what if it’s defamatory, mean, or intentionally malicious?
Vandalism can then have serious consequences, and stain reputations.
Sport isn’t the only arena where Wikipedia vandalism takes place. There are many other examples, to which we will not link here for obvious reasons.
- An ex-student unhappy about their old school
- A customer unimpressed with how a brand treated them
- A former employee disgruntled with their prior workplace
Any of these types of people can go onto Wikipedia with an ax to grind and run the page, at least temporarily, into the ground — and have that reflected in search, if it’s a well-known brand.
If it’s on a dormant page with minimal interest, vandalism can just sit there. Going months, if not years until someone notices it.
How does Wikipedia defend itself against vandals?
Protecting its integrity relies on it being able to identify vandalism quickly.
There are Wikipedia Bots designed with the sole purpose of detecting vandalism and reverting the edits.
There is also a page with a list of recent changes which editors can monitor to see what’s been happening recently.
Frequently vandalized pages can be protected to prevent unauthorized edits.
But this isn’t, as we have seen above, fail-safe. Who has time to monitor a Wikipedia page? Other than the aforementioned sports trolls, probably nobody.
However, there are great tools available to notify you when changes have been made to pages you track.
We will leave the final word to Abraham Lincoln, whose page on Wikipedia is one of the most vandalized of all time. In his Gettysburg Address he said:
“The world will little note, nor long remember what we say here but know that the problem with a Wikipedia page is that you can’t always depend on its accuracy.”
So, what happens when they Google you?
What searchers think about a CEO’s search results
As an Intelligent Digital Reputation Management company, we are constantly doing research to understand how Google presents brands and executives in search. We also research how searchers utilize search engines to make decisions.
In August, we asked 672 US adults about their likelihood of doing business with Signiphy (a fictitious company) based on a provided set of search results – in visual form (see composite example below ) – for the (fictitious) CEO, Dave Miller.
Respondents were asked to imagine they were already considering doing business with the company and, as a next step, had decided to Google the CEO. Each participant was shown one of several variants of the search results page and was then asked to answer some questions about the page they saw.
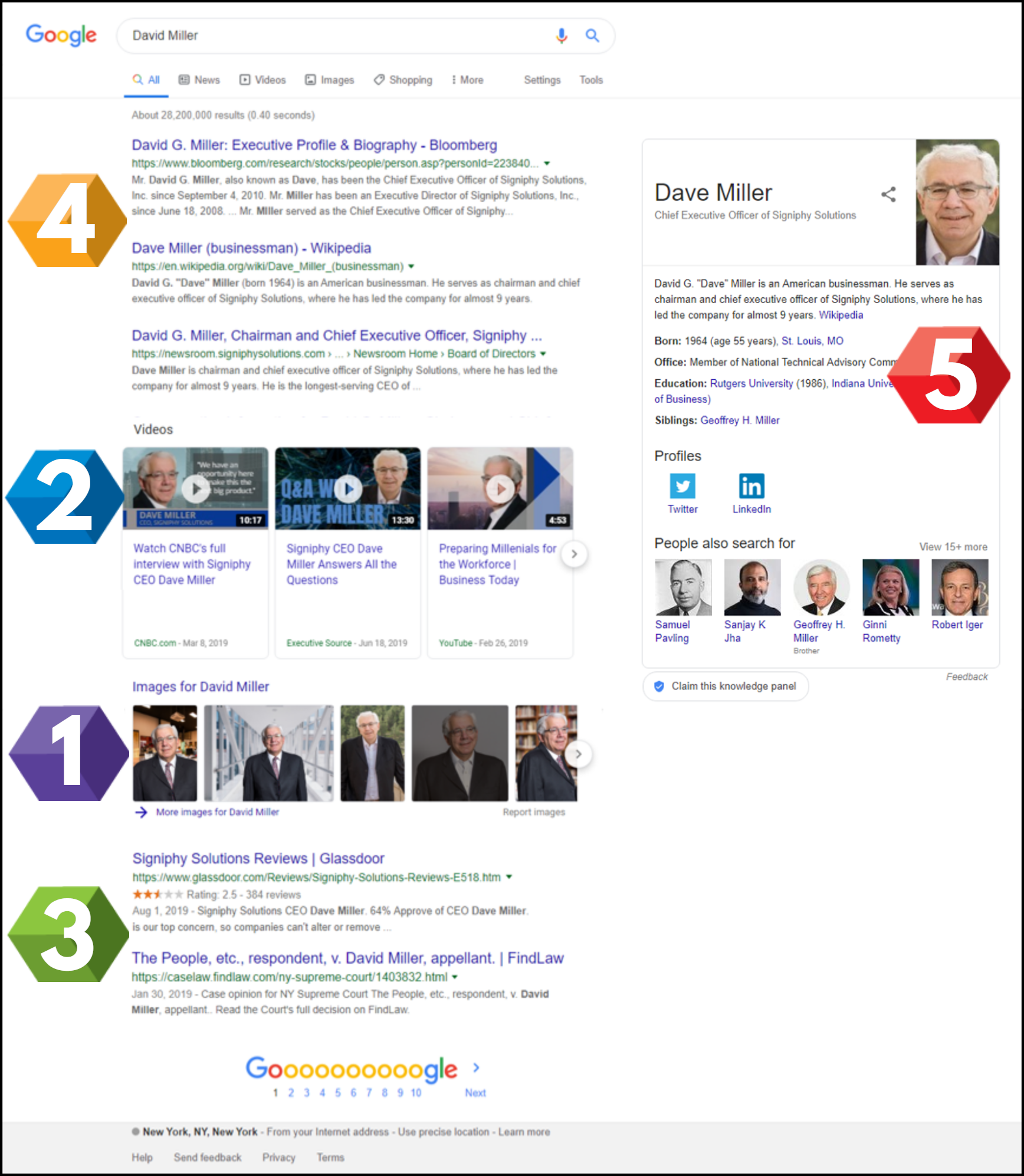
Here’s what we found:
1 IMAGE BOX
This is intuitive – but it was borne out clearly in our research: Images on a search page help paint a picture in the searcher’s mind, more easily than any block of text, and affect how the searcher feels about the person they are searching.
We used images that depicted a CEO in a suit, smiling. He was evaluated as friendly and influential, and – notably – drove 80% more people to say they’d like him as a business partner compared to those who did not see the version with images. The majority of people, however, said they needed more information to decide.
Takeaway: Given how salient images are in searchers’ minds, well curated images can be a key factor in cultivating a favorable first impression.
2 VIDEO BOX
Video boxes take the impact of the visuals to another level. Like the image box, the video box in our study boosted impressions of the CEO as influential and friendly.
More than that, though, having a video box with favorable content helps solidify appeal of the subject for the searcher. Nearly 60% of people who saw the version with the video box indicated an increased likelihood to do business with the CEO’s company. Presence of the videos also boosted people’s sense that they had enough information to make a decision about doing business.
Takeaway: Videos that portray the CEO as a thought leader, hosted on known media (such as Forbes)– or even sites that appear to confer authority such as CNBC – are key in shaping searchers’ impressions of the CEO.
3 RATING SITES
Glassdoor is a site that allows current and former employees to rate their employer and its CEO. The site often appears on page one of Google search and is always shown with rating stars. Consequently, Glassdoor results are eye-catching and easier to quickly interpret compared to an all-text result.
The Glassdoor result in our research was shown with a mediocre 2.5 star rating. This led people who saw this result to be less likely to do business with the company, more so, in fact, than those who saw an all-text negative result about a pending lawsuit against the CEO.
People are used to seeing rating stars in searches for products and know to stay away when a product has few stars. That intuition transfers when rating stars are shown for a CEO, making Glassdoor an important result to watch.
Takeaway: If your brand has results with star ratings – Yelp, Glassdoor, or others – it is important to manage these and ensure that the star ratings are high – or alternatively that these results are not appearing prominently. Either way, brands need strategies aimed at managing these types of sites.
4 AUTHORITATIVE SITES
Bloomberg and Wikipedia are consistently among the most frequent sites to appear prominently in search results for CEOs. They typically appear toward the top of the page.
In our research, these two sites were the most frequently mentioned (in open ended replies) as the first places the searcher would click for more information.
Takeaway: Bloomberg and Wikipedia are deemed authoritative and trustworthy. This makes them an important component of a CEO’s digital presence.
5 KNOWLEDGE PANEL
As mentioned above, searchers’ attention will inevitably drift toward the visual, easily processed information on a search page. Even so, it is important to curate the text-only components of one’s search results. (This is especially true when there are fewer attention getting visual elements, where searchers are likely to take the time to read the text-based results.)
Our test pages mentioned both in the Wikipedia result and in the corporate bio that the CEO had been in that position for nine years. That information was duplicated in the knowledge panel blurb, which uses the first sentence from the subject’s Wikipedia page. People deemed that information useful and likely noticed it because it appeared in multiple places.
Takeaway: Curating search results by making sure key information appears in multiple authoritative online sources ensures that searchers will see desired information about the company or individual they are searching.
Searching for Boris
If someone has negative results appearing in search, does it make sense for them to try to “deceive” Google by using terms associated with the negative result in positive ways? A meditation on models and buses.
Amid the political drama of Brexit, a hung parliament, and upcoming elections, the virtual Boris Johnson also caused a stir, especially among digital media professionals.
A recent Wired article discussed the fascinating, odd phenomenon of Boris Johnson’s “off script” ramblings, rumored to be an attempt to “game Google.”
It began on June 20, 2019, when Johnson gave a most peculiar interview on Britain’s TalkRadio. He was not yet prime minister of the UK but was already the most likely candidate to replace Theresa May. He was asked what he does to relax. His reply, many will remember, was perplexing: “I make things. I make models of buses.” He went into detail about this unexpected hobby.
Almost immediately, pundits began to suspect there was something more cunning behind Johnson’s answer than the average politician’s disconnect from real people. Maybe, they surmised, it was a calculated move to improve his search results.
You see, Boris Johnson was already famous for another bus – one in which he rode around the country before the Brexit vote, encouraging people to vote to leave the European Union. On the side of that bus, in big letters, it said, “We send £350 million to Europe, let’s fund our NHS instead,” which was a contentious statement, and perhaps an outright lie.
First the social media opinion makers, and then everyone from Gizmodo to John Oliver, suggested that perhaps Johnson specifically spoke about model buses, so that anyone searching for “Boris Johnson bus” would read about the models, not the Brexit campaign.
This seemed unlikely at first. But then, in early September, shortly after media reports that the police had been called to a flat Johnson shared with his girlfriend Carrie Symonds, Boris gave a rambling speech while standing in front of a group of police cadets. Was that another attempt to manipulate Google?
And then on September 29, in an interview with the BBC’s Andrew Marr, Johnson insisted he was “a model of restraint.” The phrase was picked up in headlines across the country and internationally. Coincidentally (or not), he said this a day after police opened an investigation into potential criminal misconduct for awarding state money to model Jennifer Arcuri, an alleged mistress.
Oscar Wilde wrote, “To lose one parent may be regarded as a misfortune; to lose both looks like carelessness.” In the case of Johnson, repeating the supposed “trick” three times makes it seem like an attempt to massage his search results and media.
The question is – assuming it is a trick – does it even work? If someone has negative results appearing in search, does it make sense for him or her to try to “deceive” Google by using terms associated with the negative result in positive ways?
If you looked at the search results immediately after Johnson spoke about his model buses, most of the results were about the models, rather than the Brexit bus. So, it was a clear short-term win. But the Brexit bus was already old news, and Boris mumbling about his hobbies was probably just about as exciting for readers.
Furthermore, a couple of months later, the hobby buses have largely disappeared from search results (though “luckily” for Boris, the company that made the buses went bankrupt, so that has dominated the results.)
With the police and the model diversions, Johnson was less successful. Of the average 10 results on page 1 of Google search, one or two were about the positive spin, most were negative, and a couple were articles like this one, discussing whether or not Boris was intentionally trying to manipulate the results (it’s unclear whether these discussions please Johnson.)
But fundamentally, even if the theory is true and he really was using these tactics to manipulate search, it would be the wrong approach to take for a very simple reason: User behavior.
Someone who searches for “Boris Johnson bus” or “Boris Johnson model” is looking specifically for the “dirt.” Even if, hypothetically, there are no negative results on page 1, someone looking for information on Johnson and Jennifer Arcuri will simply click to page 2 or use more focused search key words until they find what they are looking for. With a specific search like that, there is no point trying to manipulate the results (even if such a thing were possible): you cannot fool the searchers themselves.
Perhaps the PR team behind this initiative got a pat on the back from Johnson – at least they managed to remove some of the negatives for a few days. But in fact, they didn’t really make any difference at all to Johnson’s online reputation.
We spend all day thinking about and working on client’s online reputation, and we know that cheap tricks and short-term fixes are not the way to go. Nor does it make sense to focus specifically on the negative terms, because someone who is looking for the negatives will find them.
Rather, we would be more interested in what search results look like for “Boris Johnson” or “UK Prime Minister.” If someone searches with no preconceived ideas, what do they find?
There is such a constant torrent of news about Johnson and Brexit, that it would be impossible to take complete control of his search results right now. Nonetheless, a search for “Boris Johnson” includes his Wikipedia article (which almost always ranks near the top of page 1 for the subject, and which is supposed to be unbiased and fairly written.) His Twitter account and his Facebook profile both rank on page 1. So, he “owns” two of the results on page 1 (and has a Twitter box, which occupies more space that he controls.)
Let’s look at a couple of senior members of Johnson’s cabinet. Jacob Rees-Mogg is Leader of the House of Commons. Page 1 of his Google results include his Twitter and Facebook profiles, his Wikipedia entry, and his profile on www.parliament.uk.
Chancellor of the Exchequer, Sajid Javid, has results from Wikipedia, Twitter, www.parliament.uk, www.gov.uk, and his own website, https://www.sajidjavid.com. These types of “owned” results occupy the top half of the first page of Google, knocking out negative results and allowing those MPs to more closely control their online reputations.
We don’t know for certain whether Johnson was trying to use tricks to manipulate his search results, but we do know that if he were to ask us, we’d tell him this: Sir, you’d be better off focusing your energy on optimizing www.boris-johnson.com (a site not updated since 2016) and/or populating borisjohnson.com, which is not even live. You could also strengthen your owned results for the search term “Boris Johnson,” rather than speaking about model buses or posing with policemen. Your PR team is welcome to contact us. You can go back to the models.
The Wikipedia Index: Edits to the Fortune 500
Wikipedia editors worldwide make 1 million edits every week. How many of these are edits to pages of major companies? Does it vary by industry? We found out for you:

There’s no doubt about it: Monitoring changes to corporate or executive Wikipedia pages is an essential component of reputation management.
What if your content has a rank destroying evil twin?
Own more of your reputation by tackling duplicate content.
Let’s play a little game. Pretend you’re a customer who is thinking about buying a specific product. You aren’t super familiar with the company that makes it and you want to get better acquainted before pulling the trigger. What are you going to do? If you are like the large majority of people, Googling the company will be your first step.
Those of us who work in marketing know this quite well and spend a huge amount of resources making sure that we put our best foot forward in search results. The picture of ourselves we want you to see will ideally contain owned content mixed with earned media (PR), paid (ads), and social media. Of these assets, companies are usually most easily able to edit their own properties, like their corporate website(s) and their social media accounts.
Because of this, a common question that we get from clients is: “Why isn’t my company’s LinkedIn page showing up in searches for our brand?” I should note that this question can be asked about *any* social media property and is equally applicable to personal bio texts and profiles which are being filtered out of an individual’s search results. That said, companies’ LinkedIn pages present a particular challenge because of some otherwise helpful quirks in Google’s algorithm which I’ll explain more below.
How Google’s Algorithm Works for Corporate Searches
Google makes most of its money selling ads. The more people who use the search engine, the more they will click on its ads. Google is thus incentivized to provide the best search results to answer searchers’ questions.
But how does Google do that when many searchers search for the same words despite having drastically different backgrounds and intent?
For instance, if I’m searching for “General Electric” I could be looking for a way to buy products direct from the company, corporate stock information, company history, information on careers, news, the address of a local office, the French alternative rock band slightly misspelled, or any number of other things. Google attempts to solve this by showing different types of results with the hope that at least one of them will give the searcher what they are looking for.
With so many potential angles to satisfy all at once, Google can’t afford to show two results with the same information, and the engine filters out any results which it considers to be duplicate content.
Duplicate Content + Companies = LinkedIn’s Nightmare
If you have ever worked in a corporate setting, you will understand that it is sometimes difficult to get new content approved by your boss, comms, legal, etc. Often, companies have one standard approved “About Company X” text, which staff can then copy and paste to all of their owned platforms.
I can’t count the number of times that one of our clients has seen their LinkedIn page suddenly disappear from the middle of the first page of their Google search results, because Google realized that the About content on LinkedIn duplicates the same information that is on the company’s website.
Why Does it Matter?
It may not. However, without LinkedIn, career searchers may look for a similar result like Glassdoor, which is out of a company’s control. If they don’t like what they see there, they may not apply or take the job you offer. Similarly, if your company has a negative news story, the news story may appear more prominently in search results with the space “cleared” by the missing LinkedIn result.
Intelligent digital reputation management requires that we follow Google quirks like this closely, and we are always testing and searching for the newest and best ways to tackle client problems.
Now buckle your seat belts and grab a Mountain Dew, because we’re about to get geeky.
Diagnosing Duplicate Content
To easily confirm that your missing LinkedIn result is indeed an issue of duplicate content, search for your company’s name on Google and then add &filter=0 to the end of the URL of the search results page. This turns off the duplicate content filter. If LinkedIn shows up in these new results where it did not show up before, you know the problem is duplicate content.
Solving the Duplicate Content Puzzle
The first step to getting LinkedIn or similar profiles back where they belong is identifying the other side of the duplicate content equation: finding the other page or pages which contain this same content.
This process typically involves using what Google refers to as “search operators” – symbols and/or words which you can add to your searches to make them more precise. These search operators are worth their weight in gold (or nachos, if I know my audience) for research purposes.
Step 1: Search for an opening sentence or two of the “About” text, surrounded by quotation marks to ensure that you only get results with this exact text:
EXAMPLE SEARCH: “This is sentence number 1. This is sentence number 2.”
This should bring up a list of other pages which use these two sentences word-for-word.
Step 2: If you think you’ve identified the other sources, you can confirm your hunch by asking Google for search results without these other sources using the – (minus) and site: operators. The following example is what I’d search to confirm my hunch that the duplicate content is coming from corporatewebsite.com.
EXAMPLE SEARCH: Company Name -site:corporatewebsite.com
This will return results for the company name without any results from corporatewebsite.com. If the reason that LinkedIn was being filtered out is indeed because of some duplicate content on this website, then these search results should show LinkedIn prominently.
Note also that if the duplicate content is coming from multiple sites, you may have to use multiple -site: commands. So if the duplicate content also came from alternatecorpwebsite.com, you’d search for the following instead.
EXAMPLE SEARCH: Company Name -site:corporatewebsite.com -site:alternatecorpwebsite.com
Step 3: If you’ve solved the mystery and want to bring LinkedIn back to your search results, the solution, of course, is to change up the text so that it differs from the text found in other prominent locations.
Hint: when you make the ask for a new About text, the corporate communications writer in the next cubicle probably prefers ice espresso to Mountain Dew.
The Wikipedia Index: Facts and Big Business
We’ve said it before, but it’s worth saying again: Monitoring changes to corporate or executive Wikipedia pages is an essential component of reputation management.
As we’ve noted previously on this blog, Wikipedia is the 5th most visited website in the world, with 80 million registered users and 200,000 editors. Wikipedia has changed the way we seek out information and determine its accuracy, with two thirds of US adults saying that they sometimes or always trust what they read on Wikipedia, according to our recent research — which also found that half of Fortune 500 CEOs (and 94% of companies) have an entry that ranks on page one of Google for searches of their names. Wikipedia is a key component of online reputation for notable organizations and individuals.
With that in mind, look how frequently major brands have their pages edited by Wikipedia’s many editors:
WikiAlerts™ by Five Blocks facilitates monitoring by sending real-time email alerts when edits are made to tracked Wikipedia pages.
Your Own Wikipedia Page: What Does it Take?
On October 2, 2018, in the pre-dawn hours in Ontario, Donna Strickland received a phone call that would change her life. It was Göran Hansson, secretary general of the Royal Swedish Academy of Sciences, calling from Stockholm to inform her that she had won the 2018 Nobel Prize in Physics.
About an hour later, Strickland’s big win was announced to the rest of the world, and the fanfare that ensued went far beyond the usual media blip: Strickland, an associate professor of physics at the University of Waterloo, was only the third woman to win the Nobel Prize in Physics in the award’s history, and the first since 1963.
Along with the plaudits came voices of criticism for an award process that some believe has historically neglected women, and for a society that many feel does not do enough to foster the success of women in the sciences.
But a fascinating secondary story quickly emerged on both social and traditional media, in what The Atlantic called “a Metaphor for the Nobel Prize’s Record With Women.” As it turned out, Donna Strickland did not have her own Wikipedia article at the time of her award’s announcement, despite her many achievements in her field, and her stature as president emeritus of a leading academic society.
Even more gallingly, a Wikipedia editor had drafted an article about Strickland on March 28, 2018 – several months before she won the Nobel Prize – only for the draft submission to be summarily rejected by another Wikipedia editor.
To be sure, once word got out that Strickland was a new Nobel laureate, a Wikipedia article about her was created in a flash, and soon reached a respectable length and level of detail. But media outlets seized on Wikipedia’s initial exclusion of Strickland – despite her many accomplishments – until she won the Nobel Prize in Physics.
The headlines were quick to condemn the website: “Wikipedia rejected an entry on a Nobel Prize winner because she wasn’t famous enough”; “The Nobel prize winning scientist who wasn’t famous enough for Wikipedia”; and “Female Nobel prize winner deemed not important enough for Wikipedia entry.”
But just how accurate were these accusations? Was Donna Strickland truly “not important enough for Wikipedia”? The answer is … not exactly.
To get to the heart of the matter, let’s put aside the thorny topic of gender and systemic biases on Wikipedia and elsewhere, and ask a more basic question: What does it take to get on Wikipedia? Just how famous does a person have to be to deserve an article on the world’s most widely read encyclopedia?
One of Wikipedia’s foundational principles is that Wikipedia is an encyclopedia, not an indiscriminate collection of information, so there needs to be some standard for a person (or any other topic, for that matter) to be judged suitable for inclusion.
The standard that the Wikipedia community implemented as the primary metric for inclusion is actually neither fame nor importance. It is notability. According to Wikipedia’s official notability policy, notable topics are “those that have gained sufficiently significant attention by the world at large and over a period of time.” Fame and importance (not to mention other factors like popularity, talent, and prestige) are deemed too subjective to meet Wikipedia’s inclusion criteria. Notability is where it’s at.
Part of why Wikipedia chose notability as the linchpin of its operation is that it can be demonstrated using references. Most Wikipedia articles must justify their inclusion by meeting the General Notability Guideline, or GNG. Sometimes called Wikipedia’s Golden Rule, the GNG states: “Articles generally require significant coverage in reliable sources that are independent of the topic.” Each part of this sentence represents a critical element of the GNG: “significant coverage” excludes trivial mentions; “reliable sources” excludes biased content and publications with poor editorial oversight; and “independent” excludes content produced by the article’s subject, such as a press release or an autobiography.
Despite Donna Strickland’s importance and stature in her field before she won the Nobel Prize, she clearly did not pass the GNG – there was simply no significant coverage of her or her work in news media or elsewhere! This is unfortunately more typical of important people from previous generations who simply did not appear sufficiently in sources that live online.
Critically, there are also several subject-specific notability guidelines, which serve as a kind of back door to grant inclusion to subjects that may not pass the GNG. For example, the notability guideline for academics dictates that an academic is notable if the person “is or has been an elected member of a highly selective and prestigious scholarly society or association.” In hindsight, many in the Wikipedia community argued that Donna Strickland should not have been rejected by Wikipedia even before winning the Nobel, despite the dearth of media coverage about her at the time, since she is a past president of The Optical Society.
But the fact remains that by Wikipedia’s formal standards – which value notability and media coverage over more subjective factors – Strickland’s case for inclusion was, at best, contentious. As Wikimedia Foundation President Katherine Maher wrote in the aftermath of the Strickland affair, “If journalists, book publishers, scientific researchers, curators, academics, grant-makers and prize-awarding committees don’t recognize the work of women, Wikipedia’s editors have little foundation on which to build.”
As we go forward into the future, our generation’s approach to appreciating women’s achievements will require some serious edits.
Knowledge is Power: Wikipedia Fact Sheet
The 5th most visited website in the world has changed the way we seek out information, and the way we think about knowledge as a collaborative effort. If you are a CEO with a Wikipedia page, that page will likely be the second result on a Google search for your name.
Here’s a 2019 look at Wikipedia:

Google and the Case of Mistaken Identity
It started with the best of intentions.
In June 2018, Google announced a new feature which would help individuals and businesses better manage their presence in search results. Per the announcement, “When you search for well-known people, organizations, and things on Google, you’ll often come across a Knowledge Panel on the results page—a box with an overview of key information and links to resources to help you go deeper.”
For those who aren’t familiar, below is an example of a Knowledge Panel, found in a search for former baseball player Alex Rodriguez (“ARod”):
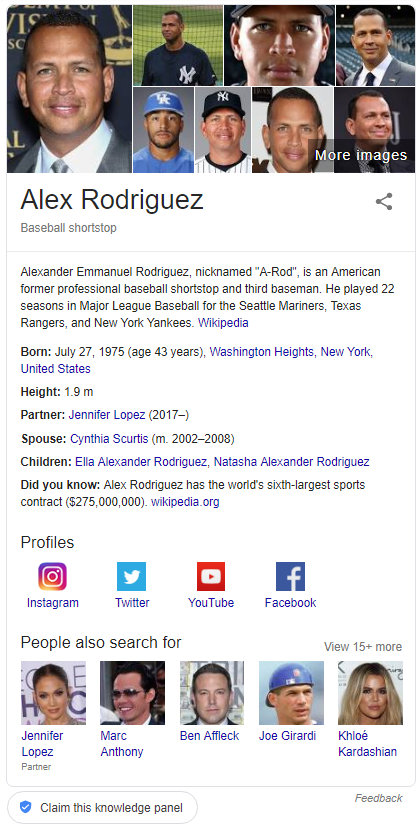
The Problem with Knowledge Panels, and Google’s Solution
With the Knowledge Panel, there is the potential for Google to accidentally spread out-of-date or inaccurate information. Imagine that tomorrow Jennifer Lopez breaks ARod’s heart. Would she still be listed as his partner in the Knowledge Panel shown above?
Unfortunately, we’ve found that Google is not the best at updating these Knowledge Panels to account for new information – see this example where Google showed the wrong CEO for a major corporation for over a year after he stepped down!
To counter this, Google now offers companies and individuals the ability to “Claim this knowledge panel” via the button at the bottom of the screenshot above. This feature allows the verified entities to directly submit change requests to expedite changes for out-of-date or inaccurate information.
Seems like a good solution!
Intelligent digital reputation management requires that we follow these features closely, so we are always thinking critically about what each development means for our diverse set of clients.
Because we try to err on the side of caution, when the feature was launched we immediately contacted relevant clients and advised them to claim their Knowledge Panels to ensure that others could not use the feature to request negative or malicious changes.
The “Solution” Breeds Another Problem…
Here’s where it gets interesting.
Last week, I was looking into a Knowledge Panel-related issue for a client when I decided to see how real this risk was. You see, there is another Ari Roth out there who is significantly more famous than I am. This other Ari Roth has a Wikipedia page, and because of this, a Knowledge Panel about him appears when you Google “Ari Roth”:
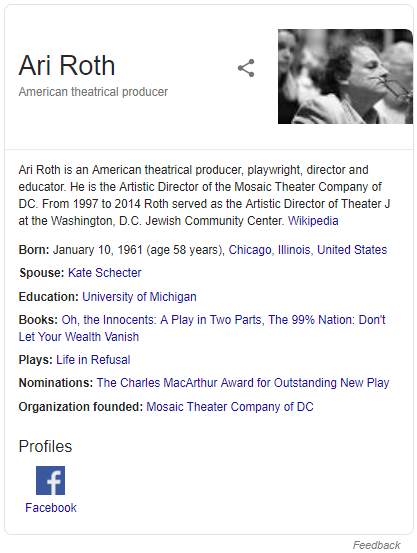
This Ari Roth actually has some of the issues I described above. Specifically, the Facebook button listed at the bottom links to *MY* Facebook profile. This is not the first time that something like this has happened. Below is a screenshot I took back on May 2nd when I noticed that it was my Twitter profile appearing:
To test Google’s system, I decided to submit a claim to this Knowledge Panel.
While you can choose to provide them with screenshots showing you logged in to associated social media profiles, the only mandatory form of identification which the form requires is a selfie while holding government-approved photo identification.
I filled out the form, providing the selfie with my ID, as well as screenshots showing me logged in to my Facebook and Twitter profiles, assuming and hoping on behalf of my clients that Google would realize that I was a different Ari Roth (there is a 25 year difference in our ages, for starters) and reject my request.
Mistaken Identity: Confirmed by Google
Sadly, a few days later, Google proved my assumption wrong when I got the following email:
Apparently, whoever was reviewing the verification requests did not bother to compare my selfie or the biographical information provided by my social profiles to images and biographical information for the Ari Roth who is actually described in the Knowledge Panel.
Even a surface level review of this information would have clearly confirmed that I was not the Ari Roth in question. Instead, it seems that anybody with the same name can be granted access to edit your online reputation. In an extreme case, I even wondered if I could game the system by legally changing my name to Alex Rodriguez. 🙂 There would be so many perks with that choice!
What Google Should Do Next
To be clear, I do not actually want to manage the search presence for someone who is not me. While the other Ari Roth and I seem to share relatively few commonalities, I have no desire to submit malicious or negative information about him to Google. This was just a test which I performed with a disappointing result. I hope that Google will read this, manually revoke my access to the Knowledge Panel in question, and adjust their internal processes so that others do not fall prey to someone with malicious intent.
But my hopes for what Google will do have been let down before.
What the Other Ari Roth Should Do Next
Reach out to me via Facebook, Twitter, LinkedIn, fax, carrier pigeon, etc. I’m happy to submit any requested Knowledge Panel changes on your behalf for as long as I control it. Once Google (I hope) revokes my access, click the button to claim your Knowledge Panel for yourself so that this doesn’t happen again. Even a basic search on Twitter turns up tens of accounts under our shared name, and all it would take to change things for the worse is for one of our more malevolent doppelgangers to get control of the knowledge panel.
What *YOU* Should Do Next
Of course, it could have been (and I hope it was) that I just got “lucky” that a distracted Google representative was assigned to review my case. But if it happened to my bizarro Ari Roth, it could happen to you or your company as well. We continue to advise our clients and the public at large to claim their Knowledge Panels to ensure that others cannot claim them first. This is no longer a hypothetical precaution. Your reputation could be in real, practical danger!
Taking a step back to a more macro view, this underscores the great importance for ownership of your personal or corporate brands online. Relying on Google means that your reputation is vulnerable where their algorithms are vulnerable.
And since when do you believe in random results for anything your company does?
Building up your owned websites, social media profiles, and even claiming your Knowledge Panels ensure that you control as much of your digital reputation as you can.
Executives: How to SPF (Search Protection Factor) Your Summer
“Wear sunscreen.”
This iconic advice (given by a “commencement speaker” in Baz Luhrmann’s song from the late 90’s) has become code for the following wisdom:
Life is complicated in unexpected ways, but there are some simple, basic things you can do to avoid an unnecessary crisis. At least that.
This summer, you’ll wear sunscreen to protect your health and your youth – but what (or who) is protecting your digital reputation?
As you Instagram your way through the islands, blog a path through the whiskey bars of Europe, or get tagged by your friends at so-and-so’s pool party, what movement will be taking place on that great portal to your reputation we call Google? Who would you like to be seen as? Who would you like to be seen with? These things are far more in your control than you might think.
Since your reputation is at least as valuable to you as the luggage you insure before your flight, we’d like to state a few (perhaps obvious) tips before your vacation becomes a liability:
- Twitter: If you tweet frequently, your Twitter feed (and, if you are a superstar, the tweets themselves) are likely to rank on Google page one, especially if your tweets are your original content. Make sure the things you tweet are not just fit for your followers on that medium, but for everyone who may be searching for you on Google.
- Images: You may want to change your Facebook profile picture to the new one of you with the great tan and six pack (and also beer), imagining that only your friends will see it. Keep in mind, though, that your profile pictures will tend to rank in a Google search of your name, or your company’s. Which of your “assets” should your investors and board members see?
- Video: Google often provides searchers with a “video carousel” placed within organic search results, if a relevant video is available. Make sure the videos which will appear when searching your name (usually based on the title in YouTube or on your blog) remain professional and relevant.
- Your blog: It’s great if you have one, since ownership (sites where you control or at least influence the content) is one way to strengthen digital reputation. Sites like these will often rank prominently in searches for your name. Are you posting responsible, relevant written and video material on the road? Are you being true to the brand you’ve created for yourself? Remember that reputation doesn’t take a vacation, and often sticks around even longer than the sand everywhere.
- Wikipedia: Do you have a Wikipedia page? If so, you know that this page will appear at the top in search results for your name. And you probably have better things to do on your vacation than track whether any of that platform’s 200,000 editors have made any updates without your knowledge. Luckily, the Five Blocks WikiAlerts tool sends real time alerts to your email whenever there’s a change, so you can know before the Chairman does.
- Google Alerts: Along these lines, we assume you will have already set up a Google Alert for your name and your company’s; if you haven’t yet — this would be the perfect time. That way, you can get to the business of vacationing and just check your inbox periodically to see if you may have an issue. Forewarned is forearmed. Make sure that when you get away from your desk this summer your reputation stays right where you left it. Have fun!
Google: Facing the Music
The following is a quick study of the fascinating dynamics behind search page results. Most people don’t think too much about the complex nature of how Google arrives at its results, but that’s exactly what we do here at Five Blocks.
A Wall Street Journal story last month accused Google of sourcing content without giving credit to the source. The article said Google had been scraping music lyrics from genius.com, a popular lyrics site.
Some quick background: When you search for the lyrics of a song, Google often shows the lyrics in what’s called a “rich snippet”.
What are Rich Snippets? you may ask.
Rich snippets are boxes that contain content clipped directly from a third-party web page. Google uses these rich snippets because it is the fastest way to get searchers the answer to their query.
Here is an example:
This is all fine as long as Google credits the source – and ideally provides a link to click.
However, in the case of song lyrics, Google seems to have provided the name of the artist, but not the website the lyrics came from – below is an image from before the WSJ story was published:
As you can imagine, song lyrics appear on lots of sites. So how could Genius.com be so sure that Google was scraping their site?
They ran a test. They embedded patterns of apostrophes in the formatting of song lyrics. If this pattern was replicated in the rich snippet in search results, it would prove that genius.com was the original source. They used two different types of apostrophes throughout the lyrics, as below (as seen in the WSJ.com article referenced above):
Genius checked the rich snippet, and found the apostrophe pattern replicated, proving the content came from their site.
But now the plot thickens — a development we became aware of after recently sharing this story with our partners.
The lyrics site LyricFind offered a rebuttal of the WSJ story, citing their licensing agreement with Google, and claiming that the content came from their site.
In fact, in the days following the publication of the WSJ story, Google began showing LyricFind as the source, and including a link.
But what about Genius.com’s test? Here’s what LyricFind says:
“Some time ago…Genius notified LyricFind that they believed they were seeing Genius lyrics in LyricFind’s database. As a courtesy to Genius, our content team was instructed not to consult Genius as a source. Recently, Genius raised the issue again and provided a few examples. All of those examples were also available on many other lyric sites and services, raising the possibility that our team unknowingly sourced Genius lyrics from another location. [Italics ours. – YG]
As a result, LyricFind offered to remove any lyrics Genius felt had originated from them, even though we did not source them from Genius’ site. Genius declined to respond to that offer. Despite that, our team is currently investigating the content in our database and removing any lyrics that seem to have originated from Genius.”
In any event, it seems that Google, having implemented the change of crediting the source, has admitted that lyric sites, and not only artists, have certain rights — even if those are different than those held by the artist or publisher.
This episode is a reminder of how Google, with its complex automated systems that collect, process, categorize, and display information, needs to be closely monitored and managed.
In the same way that the system seems to have sourced content without proper attribution, that same mechanism often presents incorrect and damaging content about brands and individuals.
With so many stakeholders using Google to help them form opinions on people, companies, and issues, watching every detail related to Google’s top results is critical for your brand.
Another reminder that Intelligent Digital Reputation Management isn’t just “nice to have” — but an essential business strategy.
CEO Salary: Highly Visible in Search
Some of our clients wondered: How prominently does a CEO’s salary appear in searches for his or her name? Turns out, fairly prominently.
Here’s what we found:

The Politics of Search
Are political leaders in the US on both sides of the aisle receiving fair treatment from Google?
This concern is a central element driving Congressional inquiry into the search engine giant along with other search industry leaders.
We looked at Google page 1 search results for 51 key politicians (25 each Democrats and Republicans, 1 Independent) polled across 12 locations (4 each red, blue, and purple states) for 7 days (March 8-14, 2019).
Below is what we found.
In a nutshell: News Media items ranking in Google did not seem to follow assumed rules for political affiliation.
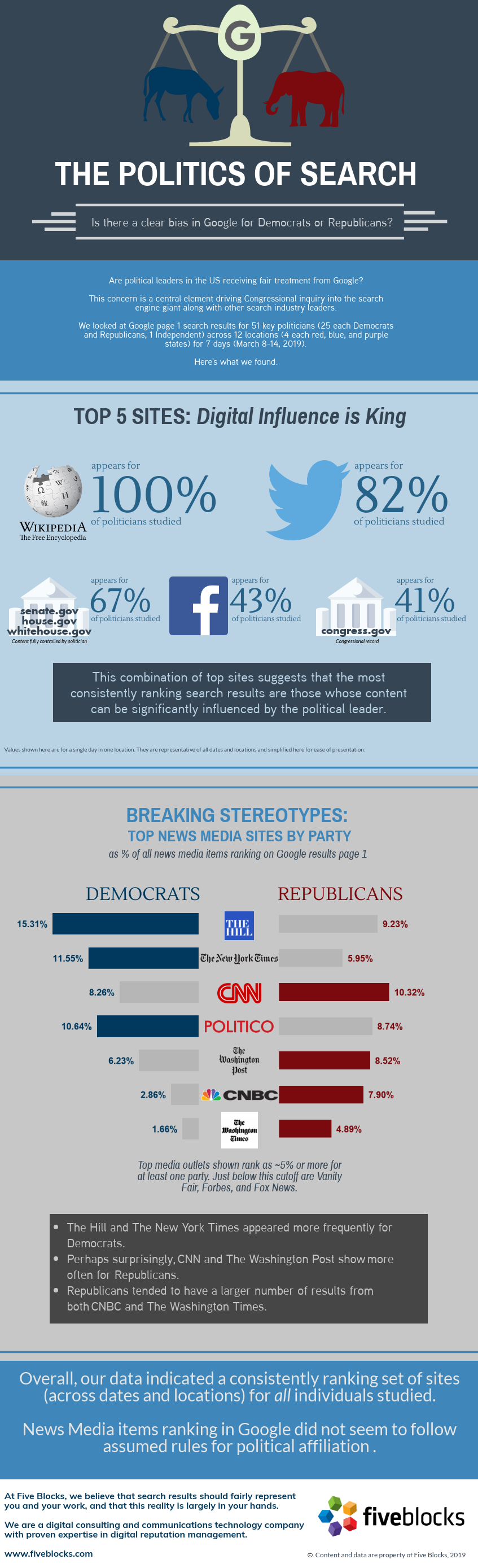
Best Practices for Managing Your Digital Reputation
The RANE community enables risk and security professionals to more efficiently respond to emerging threats and manage complex risk.
Five Blocks President Howard Opinsky talks reputation management on the RANE podcast: How can businesses and individuals anticipate and manage reputation risk in an age of snap judgments based on search?
Listen here.
How Deep is Google’s Love?: Where the In-Depth Articles have Gone (and What it Means for You)
![]()
Recently, Google appears to have made a significant change to its search results page that eliminated several in-depth articles for many clients. We’ve taken a deeper dive into this development to see what it could mean for brands and high-profile individuals, and the PR professionals who work with them.
As you know, when searching for a brand or an individual, the Google search results page presents a variety of relevant content pieces and types of media to satisfy the query. Often this means a company’s own webpage will appear at the top, followed by third-party content such as Wikipedia and news sources. There may also be social media results (if an individual or brand actively maintains these platforms), along with image results or video content.
Several years ago, Google introduced a section within top search results they called “in-depth articles”. These results looked very similar to other search results, but came from longform media outlets like Variety, Rolling Stone, or The New York Times Magazine. Often, they were a seminal article about the brand in question – articles that may have been placed by their PR teams.
Including these articles on the top results page seems to have been Google’s way of ensuring that a greater variety (and deeper) content would appear in this prime spot. Their inclusion, and the actual articles that appeared within that section, were governed by a different set of algorithms than most search results.
Recently, this section disappeared from all search pages for brands and executives. This happened without any announcement or acknowledgment on the part of Google. It is important to note that in-depth articles for many brands and individuals contained negative content. At the same time, it was the place where particularly engaging longform journalism made its way onto the prime real estate of Google page 1 for a brand.
The ramifications of Google’s elimination of this section are yet to be seen, and their motivation can only be assumed to be “less intervention” following high profile criticism of potential bias in their algorithms.
A whole host of interesting questions arise from Google’s move: What is the corporate (and civic) responsibility of those who hold the world’s data in their hands? Are there cases for intervention? Who decides what those are?
It is interesting to note that alongside this mysterious disappearance, a recent Five Blocks study of CEO search results found there are far fewer news sites (sites such as CNN, CNBC, and others) on the first couple of pages of searches for a CEO compared to a year ago. In addition, those pages feature many more profile sites, where one would find more dry facts (often created by the brand), and less news.
This marked difference in the presence of news within the organic results over the course of the past year, alongside the recent removal of the in-depth article section, means that page 1 of search for brands and individuals will contain far more“owned” content – i.e.: information they control.
For some brands this would appear to be a positive turn of events, but for many this trend means they will not automatically have great media pieces (which they often earned by being genuinely great) appear prominently in searches. It means they will need to work harder to deliberately ensure that the best third-party media does in fact place highly within their profile. Savvy communications teams will find ways to enhance their brands’ online presence within these brave new parameters.
— Sam Michelson, with Sara K. Eisen
Learn about Digital Reputation During a Crisis at the 2019 PR News Crisis Management Summit in Miami Beach – Thursday, February 28th

When crisis strikes, a company’s digital reputation becomes stressed and vital to their health. Five Blocks President, Howard Opinsky, will offer his insights at the Summit on the impact that crises have on digital reputations and what brands and individuals can do to prepare to weather the storm. Our team of digital reputation experts will also be on-hand to discuss how you can take control of your internet search results and shape them to best reflect your real profile. Join us at the Summit on February 27-28 in Miami Beach and don’t miss Howard and fellow panelists as they recount some of the best handled B2B crises and best practices in crisis preparedness at two sessions on Thursday, February 28. Learn more about the PR News Crisis Management Summit here.
Five Blocks to Present at 2018 PRWeek “PRDecoded” Conference in Chicago – Thursday, October 18
 Curious to learn more about digital reputation management? Five Blocks will be in Chicago this week at the 2018 PR Week Conference. The conference promises to be a master class for communications pros in the ever-evolving digital world. Come hear from the best in the business and be sure to catch our CEO, Sam Michelson, speaking on Thursday, October 18 at 10:45 when he’ll share keys for cracking a digital reputation crisis. Don’t miss this informative and actionable conversation.
Curious to learn more about digital reputation management? Five Blocks will be in Chicago this week at the 2018 PR Week Conference. The conference promises to be a master class for communications pros in the ever-evolving digital world. Come hear from the best in the business and be sure to catch our CEO, Sam Michelson, speaking on Thursday, October 18 at 10:45 when he’ll share keys for cracking a digital reputation crisis. Don’t miss this informative and actionable conversation.
Our team will be at the conference all day and looks forward to seeing old friends and meeting new colleagues interested in discussing digital reputation management.
Five Blocks awarded Gold dotComm Award

Five Blocks is excited to share the news that we have been awarded a Gold dotComm Award from AMCP in the SEO category.
We’re humbled and privileged to have worked with Dr. Joyce Banda, former president of the country of Malawi, to help her defend herself against defamatory information spread by corrupt political opponents.
A very special thank you to our dedicated team members for their excellent work, and of course to AMCP for selecting us from among thousands of prospective winners.
Gold Award- Digital Marketing & Communication Campaigns
Our Gold Award is a humbling affirmation of the efforts we put in to support prominent individuals and leading companies by allowing them to take control of their digital messaging and protect their reputations. The web environment is dynamic and continuously evolving, and our success in this area has been a direct result of the hard work and creativity of our team.
AMCP and the dotComm Award
We are especially honored to have earned recognition from the Association of Marketing and Communication Professionals, one of the oldest and most respected evaluating organizations in the industry. In determining winners for the dotcom award, AMCP seeks “excellence in web creativity and digital communication.” The dotComm Award is a reflection of our creativity and our ability to pivot in the dynamic online ecosystem.
Digital Reputation Trends – 2018

Over the first half of 2018, we have seen the search engine results continue to evolve from being a doorway to information to being the destination itself. This is not only evident in the composition of the search engines, but also in how users perceive the results (per the 2018 Edelman Trust Barometer).
I have continued to see clear attempts by Google to satisfy users and answer their question without any extra steps, by introducing several interesting changes to the search page functionality:
Ownership of the information
In June 2018, Google rolled out verification of the knowledge panel to more entities and notable individuals. This ability to take over the knowledge panel signals that Google wants entities to participate in providing factual information so that the searchers are provided the summary of an entity without having to search elsewhere.
Videos Carousel on the page
One of the latest changes Google has brought to the results page, following closely on the heels of Bing, is a video carousel similar to the already existing image box. While this could, potentially, reduce traffic to YouTube, the ultimate goal of immediately satisfying users apparently preempts the potential loss of YouTube advertising revenues.
Improved Search Suggests
A very recent addition to the features on the search page is enhanced search suggest.
When users click on a result and later return back to the search engine results page, Google sees they are searching for additional information and now suggests ancillary search queries directly below the original result. This feature precludes the need to do additional searches to find what the user may be looking for.
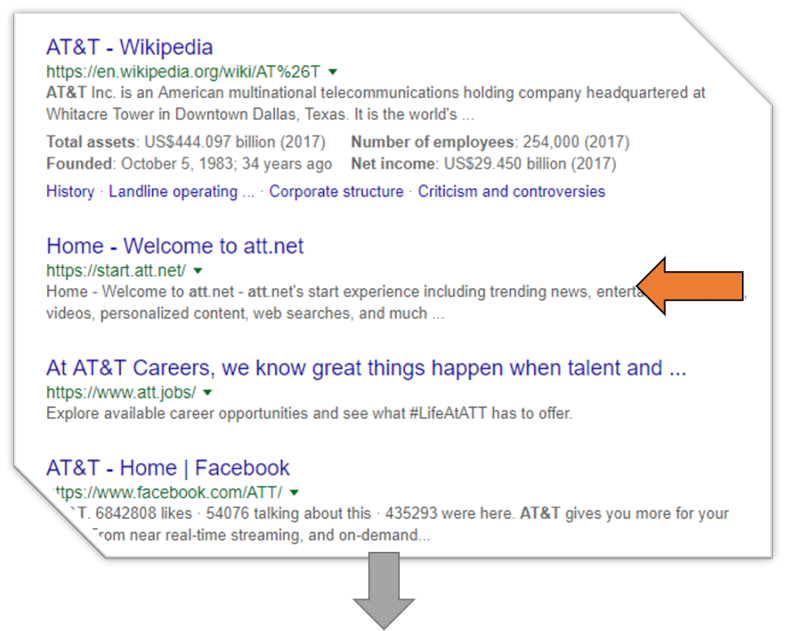
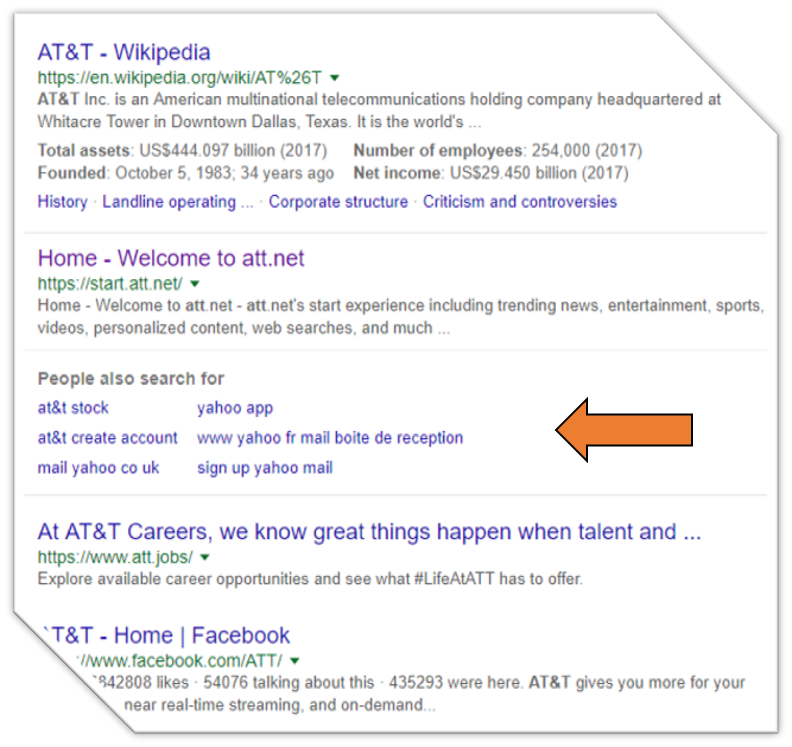
Continuous Scrolling
On mobile, Google has introduced a significant change with Facebook style scrolling, essentially creating an endless page of information. Stay tuned as this might come to all search results pages – not just mobile.
Outlook
Our outlook calls for search engines to continue efforts to provide the exact information the user seeks, ideally within the search page itself. We expect to see search engines return more content previously contained deep within other websites. It will be interesting to see how websites balance their desire to be listed within Google and Bing, and their need to hold onto their own data. Searchers will continue to demand more of the engines – who will do their part to provide the best information they can.
Online Reputation Management (ORM) and SEO: What’s the difference and do I need both?

As a business or brand, how do you know if you need online reputation management (ORM) or search engine optimization (SEO) – or both? The distinction between the two is often blurred, because both utilize some of the same search engine optimization principles and tools.
What is Search Engine Optimization?
– SEO focuses on promoting a specific website and increasing targeted traffic.
– SEO typically focuses on competitive keywords such as “men’s hiking boots” or “brown rain boots” rather than on the name of a company.
What is Online Reputation Management?
– ORM impacts searches for branded keywords in order to shape how stakeholders see your brand. It typically focuses on the name of a company, brand, or individual.
– ORM isn’t about making a sale, but about having a positive impact on the brand for long-term success.
– ORM focuses on the entire search results page. This includes the organic search results, the knowledge graph, crowd-sourced information, videos and images, and Wikipedia and business profiles.
The key difference is that the goal of SEO is to ensure that people find your company online, while ORM shapes the opinion people form of you based on information available online. To distinguish the two even further, it’s helpful to remember that SEO gets your foot in the door and gets you noticed, while ORM gets people coming through the door once they’ve heard about you.
Implementing ORM tactics can have a powerful effect on your brand and your business, as search results influence the perception and opinion of key stakeholders and clients. Search engine optimization is often owned by the marketing department since the goal is typically to increase leads and sales; while online reputation management is usually integrated with communications and PR efforts.
As digital marketing becomes more important for virtually every company, there is an increased need for brands to leverage both ORM and SEO to maximize their online potential. Five Blocks recommends using both; while most people have heard of SEO, ultimately ORM efforts will have a broader impact on your brand and your business.
At Five Blocks we leverage data, proprietary technology, and over a decade of expertise to help clients achieve a fair digital representation of themselves and their work.
If you’re looking to implement a digital reputation management program, or need help managing your digital reputation, contact us for a free assessment of your current situation.
You may also like:
- Managing Your Online Reputation – Where Do You Start?
- How One Small Technical Error by Forbes Changed the Reputation of Fortune 500 CEOs… Overnight
- Five Questions to Ask Yourself About Your Brand’s Digital Reputation
Google is boosting video with new video carousels
Over the past few days, we have begun to see a new and powerful feature in Google search results.
Instead of showing video results as before, they are now presented in a video carousel. This means that searchers see three videos in a box, with the ability to scroll and see additional videos. (Note that Bing rolled out a similar feature weeks ago!)
The following carousel, for example, now appears in searches for “Apple”:
This is the one appearing for “tootsie rolls”:
These video boxes also impact how people see important topics like GMOs:
Interestingly, this new video box doesn’t just appear for topics where video is an obvious result; we are also seeing video carousels on page 1 for many of our clients. For example, we see it for Fortune 500 companies and their CEOs, hedge funds and their managers, hospitality brands, financial institutions, and high net worth individuals.
The videos in the carousel are sourced from sites like YouTube as well as the Wall Street Journal, CNBC, and Yahoo Finance. In many cases, the videos are being sourced from the brand’s official website as well.
Google has just given brands the equivalent of $1,000s in free video advertising – if they know how to leverage this new feature!
Some thoughts on what this means:
- With more clicks going to video than before, brands that weren’t previously harnessing the power of video will want to consider an appropriate strategy.
- Brands that have preferred video content should use best practices to ensure their preferred videos appear prominently. This is likely to require an ongoing effort, as the algorithm governing the choice of videos is new – not the one that determines the order in Google’s video search.
- This is a reminder to brands to ensure that their onsite video content is being properly crawled, cached, and indexed.
- The thumbnail image of a brand’s videos is now part of the first page of results. This means that it is time for brands to revisit these and to make them optimal for branding and to attract clicks.
There are still some kinks for Google to iron out. In a few cases, we saw the same video appear multiple times in the carousel, sourced from different sites. We also noted that Google hasn’t yet connected the video carousel’s content to related brands. (For example, for Target, which has an active YouTube channel, none of the six videos shown were related to the brand.)
Overall, we believe that this feature, harnessed optimally, can be valuable for brands seeking to expose visitors to engaging content. Our goal is to help brands tell their story online and video is often the best way to do just that.
If your brand or executives could benefit from having a better control of their online image, we are happy to discuss how we may be able to help.
Sohn Conference NY 2018 – Hedge Funds fighting Pediatric Cancer!
Five Blocks has been a proud sponsor of the Sohn Investment Conference since 2014
On Monday April 23rd the top minds in hedge fund investing will gather in Lincoln Center for the annual Sohn investment conference. The conference is a forum aimed at raising funds to further initiatives to cure pediatric cancer. The sharing of world class investment ideas by some of the world’s most successful investors is the bait – and it works marvelously!

The Sohn Conference Foundation has built itself a reputation as the top hedge fund conference – even receiving a mention in the first season of the popular TV show “Billions” (Episode 6, “The Deal”) – as the symbol of hedge fund conferences.
Five Blocks is proud to have both sponsored and worked with the Sohn Conference for 5 years, starting in Hong Kong, and then working on and attending the conferences in London, Tel Aviv, and New York.
We are proud to once again sponsor the great work that the Sohn Conference Foundation is doing around the world and look forward to participating and seeing many of our clients and partners as in years past.
Our staff will be at the conference and looks forward to meeting with hedge funds and communications people who may be able to benefit from our digital reputation management services.
Sam Discusses Digital Reputation with Communications Match (Video)
Recently, Five Blocks CEO Sam Michelson spoke with Communications Match about what brands can do to manage their Digital Reputation. In this interview, Sam discusses:
- How do you define Reputation Management in a world of digital?
- What should brands do to manage their digital reputation?
- What does success look like and how do you achieve it?
It Pays to Be Wordy…And It’s Free!
Twitter jumped into the 2017 holiday season with something new for its 330 million users: the gift of more gab. As of early November, it officially doubled the character limit for a tweet, jumping from 140 to 280 characters.
Reactions so far are split on whether this is a good thing, with some already mourning the loss of creativity forced by the 140-character constraint. However, there is a major hidden benefit to Twitter’s new world of wordy: the way it affects your search results page.
Since August 2015, when someone Googles a term associated with a Twitter account, the search results have included a dedicated space for actual tweets from that account. That’s a win for companies, brands, and people who care about their online presence. It means their voice is right there on the search results page, in a section whose contents they completely control.
With Twitter’s newly doubled character count, we wondered if Google would come along for the ride. Would the Twitter box on the search page double in size? Or would it just cut off the tweet after 140 characters?
The answer? For Twitter boxes featuring the wordier 280-character tweets, the actual box has grown to accommodate the greater length.
This is an incredible branding gift from Twitter and Google, offering even more space in the search results for a brand (or company, or individual) to control and to tell their own story. This is the kind of space brands pay money to have on the search page.
Brands should welcome this gift with open keyboards. They have learned how to be creative in 140 characters; now it’s time to embrace the new challenge to be engaging, yet still pithy, in 280.
What’s more, companies can reap the benefits of a longer Twitter box on the search page without being needlessly wordy all the time. The box works as a carousel, allowing the searcher to scroll horizontally through a few recent tweets, beyond just the first three showing. We discovered that if any of the tweets in the box – even the ones not initially visible – are longer, it lengthens the whole box.
In this new era of Twitter 280, brands have the opportunity to offer deeper thoughts, or even just thoughts that are longer winded. That’s their choice. But now it pays to be wordy – without even having to pay.
Why doesn’t Google know who the CEO of Time Inc. is?
The Google Answer box is the section that appears in Google when you type in a question for which Google has a precise answer. One example would be “What is the capital of Iowa?”
The Google Knowledge Panel is that box of fast facts typically on the right side of a Google results page for companies, brands, movies, well-known people and many other entities.
To populate these boxes, Google needs to have a database reflecting the correct information. They typically source the information from Wikipedia, Wikidata, and other publicly available and (hopefully) updated sources. Sometimes, they get the information by accessing outdated sources or by parsing text in articles online – a process which can lead to mistakes.
So, when we notice something like this:
We wonder what went wrong?
Google reports that the CEO of Time is Joseph Ripp ( but he’s been out since Sept 2016!).
Rich Battista is the actual CEO; see Time’s website or Wikipedia.
In our work, we often encounter cases where Google takes months or even years to update its answer box and knowledge panel information. Sure, Google provides a feedback link that allows you to report the issue – but often even tens of reports from different users have no impact.
Another option is to raise the issue on Google’s webmaster discussion group which has been successful on a number of occasions.
Sometimes, the confusion comes from the fact that the incorrect information is still housed in many data sources – for example in Wikidata, LinkedIn, Crunchbase, and others.
What’s the best practice to avoid these situations? When the facts change, make sure that the information is updated across all platforms including all of the profiles you control and the databases that you can influence. Even then, the change may not happen.
Meanwhile – it’s clear that a better system is needed unless Google is okay with just getting it wrong.
Why did Google tell you to look up Kenneth Frazier’s Wife?
Kenneth Frazier is in the news for quitting Trump’s Business Council – and that has led to millions of searches on Google. This happens every time an executive is in the news.
At Five Blocks we help brands and executives manage their online reputation.
We pay especially close attention to Google’s “Search Suggest” – the autocompletes – like the one for Ken Frazier’s wife..
Google suggests the phrases that are most likely to resonate with searchers – based on past experience.
In this way, Google Search Suggestions are a window into what people think about you and/or your brand.
Kenneth Frazier, The CEO of Merck, isn’t alone in a recent study we conducted, over 40% of Fortune 100 CEOs’ names are associated with family-related terms in Google Search Suggest.
Meaning when searchers type in the name of the CEO, they see something like ‘family,’ ‘wife,’ or ‘son’ as one of the auto-completes suggested by Google.
This suggests that when searching CEOs many stakeholders want to know more about them and their families.
With our Fortune 500 clients we will often recommend monitoring each of the suggested quires and ensuring that the brand manages content will satisfy the searchers while making sure to respect the individual’s privacy.
It also may be interesting for companies to analyze the timing associated with the appearance of these search suggestions. Do searchers look at a CEO’s family at a time when they feel confident about the CEO? Is it in crisis? It’s even possible that the appearance of these and other suggestions may be associated with changes in sentiment toward the individual by company and are therefore related to rises or falls in share prices.
If your brand or key executives may need assistance managing your digital reputation – please contact us at services @ FiveBlocks.com.
Chrome Hopes to Unblock your Ads – by Blocking Ads!
Building an online reputation involves targeting searchers with your brand’s messaging and ensuring that searchers see your preferred content. Using online advertising can be a great way to ensure that searchers encounter your messaging online. But now, the ability to laser target searchers by buying ads could be impacted by a new plan by Google to help millions of users block paid ads.
In mid-April the Wall Street Journal reported that Google is planning to build adblocking features into its Chrome web browser. While Google still may decide not to move ahead with this plan, if they do, this could become the default.
What is Adblocking?
Adblocking is the process of blocking online ads from appearing in a web browser. It generally works via a browser ‘add-on’ or ‘extension’ that can be downloaded for various browser types. The objective is to improve the browsing experience by stopping intrusive, annoying, or unhelpful ads from appearing within web pages.
Adblocking software has been available for about 15 years and while Adblock was the first (created in 2002 by a Danish student), there are now many popular adblocking programs available.

What will Google’s Chrome ad blocker do?
Rather than block all ads, as users may currently expect their adblockers to do, Google’s will emphasize filtering out specific types of ads that contribute to a poor user experience. The choice of which types of ads to block would follow standards released in March by industry group Coalition for Better Ads. These include:
- Pop-ups
- Video ads with sound that play automatically
- Ads with countdown timers that appear before a user can see a site’s content
This dovetails with Pagefair’s finding that interruptive ads are one of the leading motivations for adblock program usage.
What is the current extent of ad-blocking?
PageFair’s 2017 report revealed the wide ranging use of adblocking technologies:
- 11% of Internet users worldwide block ads on the web
- 615 million devices around the world are blocking ads
- 52 million devices in the US – 18% of internet users
- 11 million devices in the UK – 16% of internet users
- 12% of users in Central and Eastern Europe (including the UK)
Worldwide, use of adblockers on mobile devices (11%) has overtaken use on desktop (7%). However, mobile usage is still mostly limited to countries in Southeast Asia, while desktop usage is primarily in Western countries.
Adblocking software usage spans all ages (PageFair’s study looked at adults 18+, no children) though usage is higher among men than women.
Why is Google considering adding ad-blocking functionality?
It would seem counterintuitive for Google to offer the option to block ads on its browser; ads are Google’s main source of revenue, earning them over $60bn last year.
However, as indicated, Google is not planning to block everything; rather, according to the WSJ, it will ‘filter out certain online ad types deemed to provide bad experiences for users as they move around the web.’
Essentially, Google may be hoping that by improving the default experience on Chrome, users will abandon their third party blockers, providing a win-win for both the user and for Google. With a better experience, the user is more willing to view – and may be more likely to click – on the less intrusive ads they do see, ultimately increasing revenue to Google. Indeed, PageFair’s study found that 77% of adblock users would be open to viewing some ad formats.
Conclusion
While there has been no official announcement from Google regarding the addition of adblocking capabilities to the Chrome browser, the WSJ believes one could be made within weeks.
The full impact of adblocking on publishers and advertisers is difficult to predict, however the segments of (American) users most likely to use them are males and those with a bachelor’s degree (according to PageFair). Companies targeting these groups may currently be missing a wide swath of their potential market due to use of adblocking software.
If Google is planning something in this area, there is potential for advertisers to once again reach users who are currently blocking their ads. Either way, when thinking of how to target stakeholders, it is important to keep in mind that advertising is an important tool in the brand’s arsenal, but only if the ads are designed to be seen – and not blocked – by important market segments.
Proud to Sponsor the 2017 Sohn Conference in NYC

What do you get when you gather the world’s top investment professionals in a room for a joint cause? What event could be so acclaimed that it draws industry heavy hitters like Bill Ackman and David Einhorn as well as cultural icons like Michael J. Fox and NASCAR star Jeff Gordon?
The Sohn Investment Conference NYC is the only event for investment professionals that boasts a lineup this robust and supports a cause as worthy as pediatric cancer research and treatment.

The NYC event took place yesterday in the prestigious halls of Lincoln Center. As in years past, Sohn NYC speakers moved markets in real time as they shared their much-anticipated investment ideas. The event was beautifully produced and was successful in raising millions of dollars to support innovative initiatives for curing and treating pediatric cancer.
Since 2014, Five Blocks has been a proud global sponsor of the Sohn Investment Conference in locations such as London, Hong Kong, Tel Aviv, and now New York City – for Next Wave Sohn as well as the main Sohn NYC event. We’ve been privileged to work alongside the amazing Sohn Conference Foundation team, providing digital services for the organization and its events worldwide. We look forward to continuing our support of Sohn and can’t wait to team up again next year.

How One Small Technical Error by Forbes Changed the Reputation of Fortune 500 CEOs… Overnight
New trends in Google search results are typically attributed to changes in Google’s algorithm. Search engines make frequent changes that affect search results; many of which are not known to most users. For example, over the past several months Google reintroduced the ‘Twitter box’ causing Twitter to feature prominently in search results for many brands and individuals. Wikipedia has continued to maintain top positions in search, and is the primary source of information for Google’s Knowledge Panel. Google has experimented with the inclusion of an in-depth articles section, both removing and then reintroducing it. But sometimes, significant changes in Google search results aren’t algorithmic; rather they are the result of outside forces.
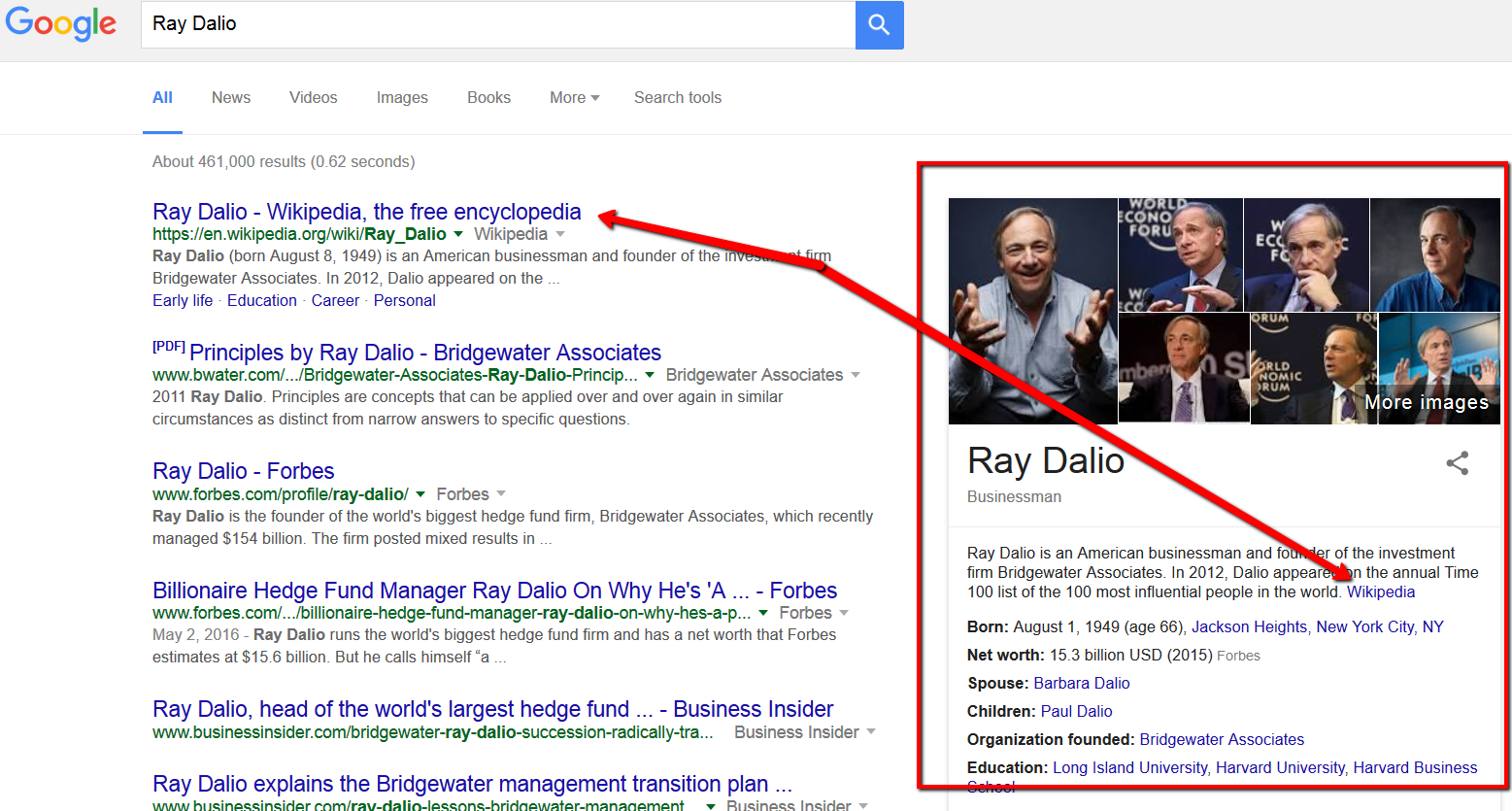
At Five Blocks, we track the reputation of thousands of brands and executives and our system alerts us to major changes impacting a large segment of Fortune 500 CEOs. Forbes pages featuring a gallery of relevant images, suddenly disappeared for many of the executives, practically overnight.
All the Forbes image pages seemed to have disappeared.
On June 16th and 19th 2016
On July 5th 2016
All the Forbes image pages seemed to have disappeared.
Initially, we assumed this was an algorithmic change in Google, but when we followed the tracks, it was clear that a human error by a Forbes staff member had resulted in a ripple effect, affecting the search results of many individuals.
What Happened?
Pages on Forbes.com, like many other sites, include code known as a canonical tag. The purpose of this tag is to send a signal to Google that the page you are on is the original content. Oftentimes the same content exists on multiple pages. Thus it is useful to direct Google to the original version.
On or just before June 25th, the URL that the tag began pointing to was the first individual on the list.
In one instance all the individuals on this list had a canonical tag pointing to Ray Dalio:
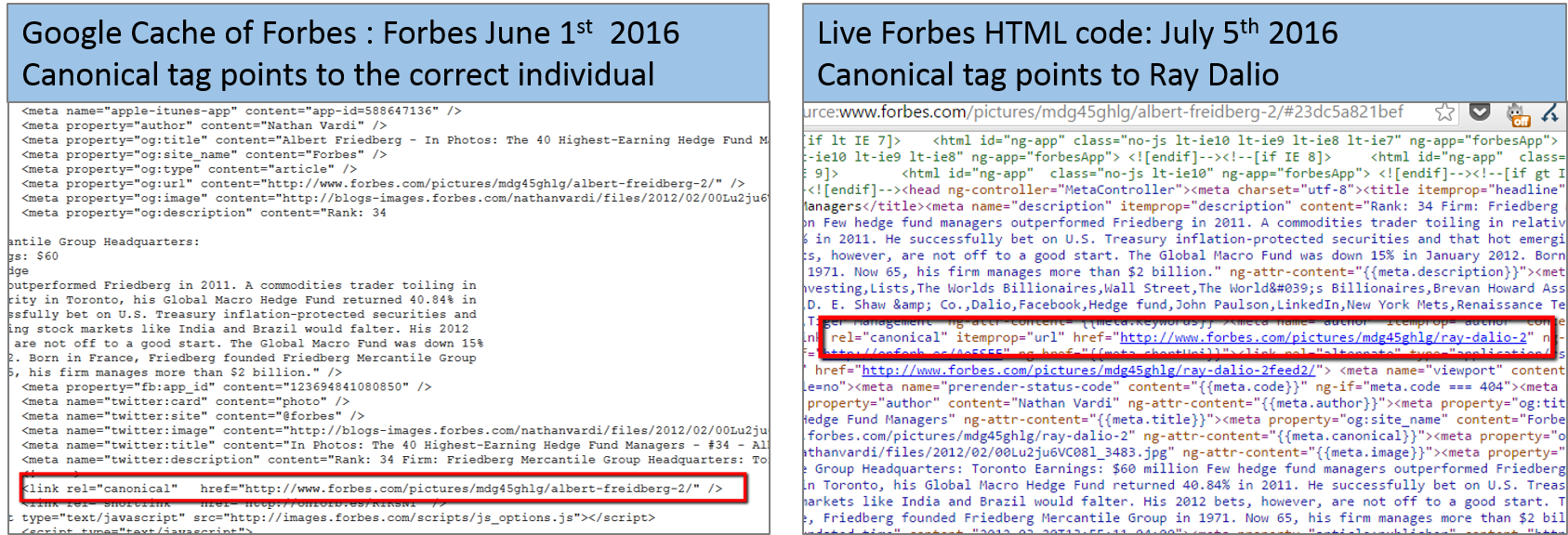
In another instance, the canonical tag began pointing to Larry Page (of all people!):
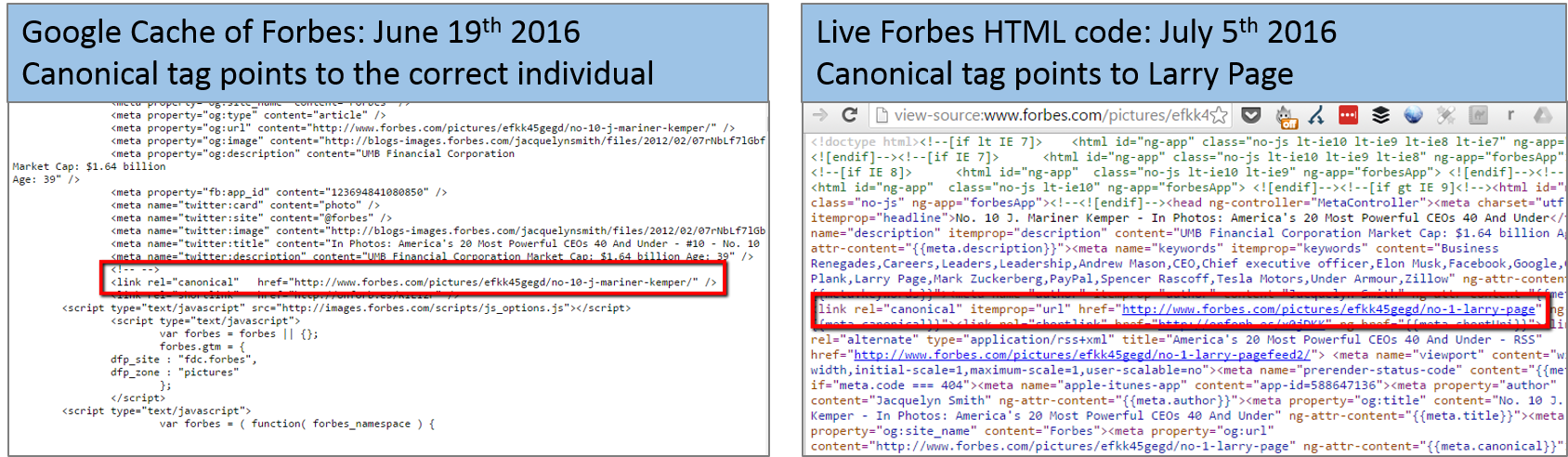
Luckily the mistake looks easy to correct and is not likely to have a long-term impact. This example serves as a reminder of the pivotal role that specific prominent publications play in the digital reputations of many executives.
Many factors impact digital reputation. Google’s algorithm certainly plays a central role, but so does launching and maintaining owned sites and content, interacting in social media, and engaging with the press to get the coverage your brand needs. At the same time, it is worth remembering that like many things in our lives, digital reputation is vulnerable to both human and technological error. Tracking your online reputation on an ongoing basis can help you take quick action when a concerning situation does arise.
And who knows, sometimes, writing a blog post and tweeting it out could be what fixes the problem.
Forbes could not be reached at the time of this publication for comment.
2016 Sohn Conference in Hong Kong

Sam and I were thrilled to represent Five Blocks again as sponsors of the 2016 Sohn Conference in Hong Kong. From the quality of the speakers and press coverage to the smooth logistical execution, it was apparent that a dedicated team worked tirelessly to make the conference such a memorable event.
While the content and networking opportunities were vast, the real focus of the evening was to encourage philanthropic support for the important work of The Karen Leung Foundation in Hong Kong. See the Karen Leung Foundation’s website for more information about how they promote awareness, prevention, and optimal treatment of gynecological cancer for women in Hong Kong.
Five Blocks is proud to have provided digital marketing services for the Sohn Conference in support of such a great cause. We look forward to participating again in 2017.

Google Serves Up a Fail for Waffle House
I’m not from the South and have never been to a Waffle House. So, without ever having given it too much thought, I could only imagine that eating there is probably fairly similar to any other fast food experience. Today, though, I had occasion to search for Waffle House on Google. Based on their search results, with all due respect to customers of Waffle House, I have learned that Waffle House seems to be a magnet for the lowest class of society. Highlights from their search page include:
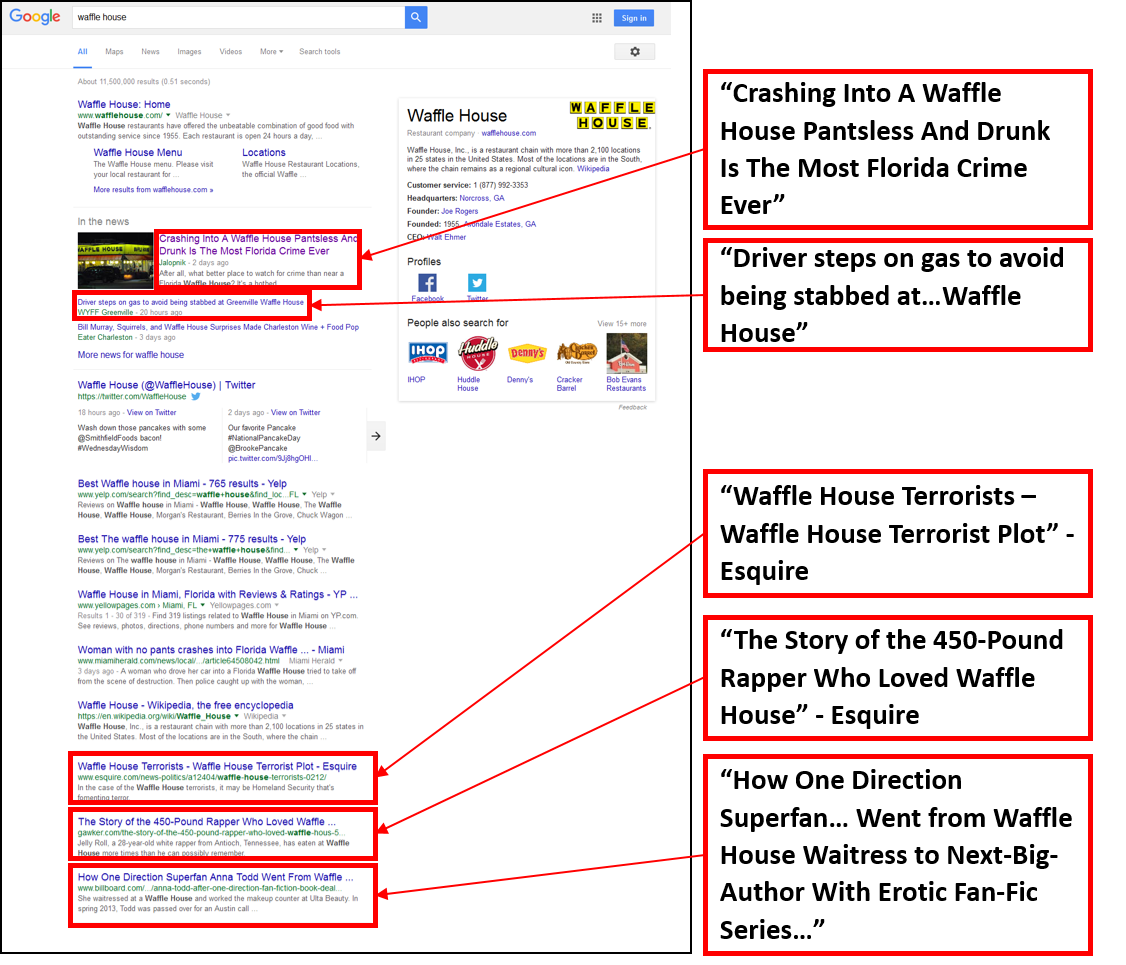
As an SEO researcher, I am particularly intrigued by the in-depth articles Google’s algorithm selected for inclusion here. In-depth articles often appear in search results for a known entity, such as a person, company, brand, or concept. They appear as a group of three articles and are typically long form journalistic coverage of the searched term. Often, their coverage has a negative slant. For example, one of Apple’s in-depth articles is “iPhone Killer: The Secret History of the Apple Watch.” For Uber, we find “The Inside Story of Uber’s Radical Rebranding.”
But these in-depth articles aren’t about Waffle House at all. They are stories about people, some crazy people, whose lives happened to intersect with Waffle House. Is that really what people searching for Waffle House are interested in finding? More than anything, they create a highly unfavorable impression of Waffle House, even though these stories have little to do with the brand itself.
Yes, these articles all mention Waffle House and yes, they are all long form journalistic coverage. In that sense, Google’s algorithm got it right. But I think nature abhors a vacuum and Google abhors one even more. In the absence of any other in-depth article-worthy coverage of Waffle House itself – positive or negative – Google’s algorithm scraped the bottom of the barrel and came up with these.
Ultimately this is one big fail for Google’s algorithm that leads to an even bigger fail for the Waffle House brand. Google is probably the best place to go when you want to size up an individual, company or brand. You are quickly exposed to a variety of sources and types of information: corporate website, social media, news, YouTube, Wikipedia etc. But when Google gets it wrong – as they do in this Waffle House example – the cost can be very high for the brand, with stakeholders getting a negative and undeserved impression of the brand.
Wikipedia Page Visits – Have You Measured Your Mobile Visits Lately?
A good way to gauge the popularity of a topic is to look at traffic to that topic’s Wikipedia page. Traffic to the page is a quantifiable measure that is easily understood and easily compared across topics.
This is particularly interesting for a company or famous person. When a CEO says or does something notable or a company experiences a crisis, Wikipedia article traffic reveals a spike in interest.
Each Wikipedia article includes a link to view these traffic statistics, although the link itself is somewhat difficult to find. For this reason, we at Five Blocks bring this valuable data to the forefront and share it with our clients. We include it in our reporting and we feature a graph of this data on our automated monitoring tool.
On January 21, 2016, the Wikipedia traffic statistics page stopped updating. It turned out this was the beginning of a migration to a new Wiki traffic measurement site. By the first week in February, the reporting was back from a new source. It improved on the old source, by allowing for viewing statistics for flexible date ranges. It even allowed a user to slice the data by traffic source (desktop vs. mobile). But that’s when we realized something was off. The traffic numbers from this tool were quite a bit higher than they were on the old one.
A bit of checking revealed the answer: the old tool was only reporting article visits from people using a computer, while the new tool included computer users and those on mobile devices. We were happy to learn that the reporting from the new data source was more comprehensive. But this had significant implications for our reporting until that point. Reporting from the old source actually understated the actual number of visitors to the wiki article.
For example, Mark Zuckerberg’s traffic as reported on the old tool would look like this:
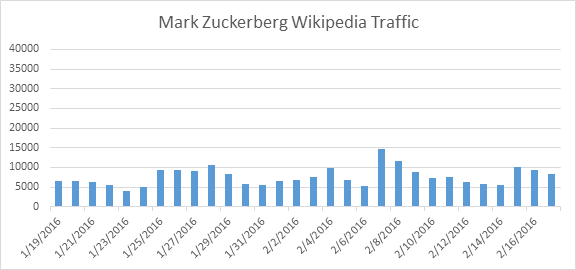
This shows average daily traffic around 7700 visits with a peak on Feb. 7.
But the more complete picture includes mobile traffic as well. It looks like this:
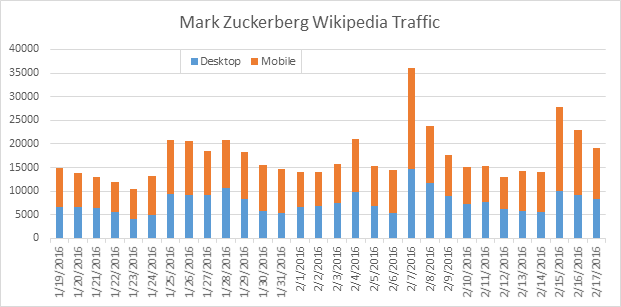
Average daily visits are actually 17,300. And the spike on Feb. 7 is now quite pronounced. (That’s when Zuckerberg wished the world a Happy Lunar New Year in Mandarin and announced his baby daughter’s Chinese name.)
Ignoring the mobile traffic here omits over half the visits to the page, totally under-representing actual interest in Mark Zuckerberg. Note a similar pattern with Royal Caribbean, which experienced its own crisis on Feb. 9 with news of its ship getting damaged in rough seas.
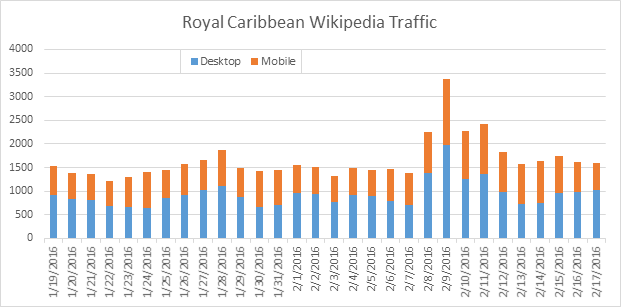
With the new data source only retroactive to August 2015, any historical data (from the old source) will require a big asterisk to remind us that we are not seeing the full picture. While the old data will still be useful to search for trends, patterns, and spikes in Wiki article views, it comes with the important caveat that the numbers themselves fall short of actual traffic. Certainly, new data should not be compared with old data given the different basis for measurement.
Obviously, the proportion of mobile traffic to a Wiki article will vary depending on how relevant that topic is to a mobile audience. But this point is clear: mobile traffic to wiki is significant. And omitting it means a significant under-representation of the popular interest in a topic, particularly during a reputation crisis.
How to Change Your Logo in Google Knowledge Graph
Many of our clients are B2B and B2C brands. Their ability to control how their logo appears in Google search results is really important to them. Google has helped these, and other, brands by including their logo as a central element in the Google Knowledge Graph. The ability to dictate exactly which version of the logo is used can be crucial to having the best impact on searchers.
This is how you do it:
- Use your preferred logo as the logo for your brand’s official Google+ profile (use verified name and link to your main website).
- If there is a Wikipedia page for your brand, make sure the logo image is your preferred version.
- Use Schema.org’s organization markup to indicate to Google the preferred logo. Google has said they will honor that (presumably in the absence of a Google+ logo).
FedEx and Fun with Knowledge Graph Logos
Fedex decided to change their logo to a holiday logo version. On or before Dec 11th, they changed the FedEx logo on their Google+ page to the holiday version.
Shortly thereafter, their knowledge graph logo changed as well.
Before:
After:
Meanwhile – FedEx has changed their logo in Google+ back to the standard logo:

But the Google knowledge graph still has the holiday logo on it.
In SEO, they often say “If you don’t like your results, wait five minutes.”
In this case, I would recommend that FedEx also uses Schema.org’s organization markup on their homepage to indicate to Google the preferred logo.
They can also go back into Google+ and change the logo to a new file in the hopes that Google will detect the change and update the knowledge graph image.
Wikidata Meets the Google Knowledge Graph
Five Blocks’ Noam Shapiro, discusses the connections between Wikidata and the Knowledge Graph. Read more at Search Engine Journal.
Twitter Firehose is Open to Google… Again!
Executive Summary:
- On February 5th 2015 Google and Twitter announced a renewed partnership enabling Google to utilize Twitter data.
- This is one of the biggest indicators that Google is serious about Real-Time search.
- More volatility is expected within search results as it begins reflecting the real world more correctly.
- Companies will be forced to interact through real-time social media such as Twitter.
- For companies whose search was fairly stable, this presents new risks.
- For companies willing to engage, this presents new opportunities.
- Companies need to claim ownership and begin minimum activity on Twitter to establish a presence.
Why is it Called “The Firehose”?
The recent partnership between Twitter and Google provides API access – what is commonly referred to as “access to the Twitter Firehose” – to Google. This is an attempt to bring more real-time data into the search giant, providing a seamless and timelier experience for the user.
When Google crawls a site, it “visits” each and every page, ordinarily requiring minimal effort. However, when this happens too often, the site’s servers become over-burdened. For example, if Google were to crawl Twitter’s 6,000 tweets a second and nearly 500 million tweets a day, Twitter would crash.
At this point, studies show that only 7% of all tweets get indexed within Google. The Firehose is a real-time feed designed to allow Google to absorb the vast quantity of data using an API.
History of the Relationship
This is not the first time we have seen this relationship between Google and Twitter.
- In October 2009, Google signed a deal with Twitter to utilize the data from the “firehose.”
- Two months later, Google revealed its “Real Time Search,” with another information box consolidating tweets into the organic results.
- After less than two years, in July 2011, Google and Twitter were unable to renew the terms of the deal. They parted ways and Google stopped showing real-time search as a result. At one point, among friction, Twitter entirely blocked Google’s bots from crawling the site, later explaining it was a mistake and unintentional.
The Real-Time Web is Growing as the Firehose Opens
In a world of fast moving technology, real-time data has become more important than ever, escalating the expectation of the average user.
- Google does an incredible job at indexing global data, but there is often a delay in how quickly it can unearth the latest news.
- Twitter on the other hand – better than any other platform – often breaks stories and is the source of real-time news consumption. Aside from that, Twitter could generally go unnoticed once mainstream media catches up.
What has become clear is that both platforms alone do not tell the full story online. With this alliance, users will get real time updates into the most comprehensive source of information substantially increasing retrieval time.
Five Blocks’ Predictions
While it is still unclear how the relationship will ultimately materialize, there is some speculation based on some of the previous history:
Prediction 1
Google will NOT create a custom section in the results page for Tweets as they did last time. That being said, this doesn’t make it any less important, and could add a new layer of complexity and turbulence to search results.
Prediction 2
Hashtag result pages will become very influential. In November 2014, Twitter began building out more “SEO friendly” pages for their hashtags. Google will find a way to leverage this rich, timely, and trending content.
Prediction 3
Google will begin incorporating social metrics into search results, similar to the way Schema markup will work. Bing has recently rolled this out which indicates authority.
Preparing for all Eventualities
For brands willing to engage on social media, there is a tremendous opportunity to gain additional control during a real-time crisis situation.
While there are no certainties on the exact execution of this relationship, the need to be prepared is indisputable. When Google “flips the switch,” it will likely cause many immediate changes to search results, especially if timely information is being shared.
In order to be prepared, we recommend:
- Claim your Twitter handle – If you already own your brand’s name, great! If not, this could mean taking over an account that is currently owned by someone else.
- Optimize Images and Descriptions – Add your logo, include a nice description, background image and appropriate link back to the company website.
- Verify the account – In this process, brands and prominent individuals register with Twitter, authenticating their Twitter account ownership.
- Start Tweeting – Begin investing small amounts of time in Twitter and – at a minimum – automating tweets which include company news, press releases, statements, or other positive relatable content.
- Create an emergency response plan for when news begins to trend.
Conclusion
Time will tell how this relationship will evolve, but the most important thing is to have all assets in place. This is likely the beginning of Google integrating real-time content into search results and we can expect to see more social impact, markup, and social media as ranking signals and measure of influence.
For more information on Twitter and Google partnership, visit the resources below:
- Launch Announcement:
http://www.bloomberg.com/news/articles/2015-02-05/twitter-said-to-reach-deal-for-tweets-in-google-search-results - FAQ with Danny Sullivan:
http://marketingland.com/twitter-google-search-deal-faq-117463 - Google Index Study:
https://blogs.perficient.com/2015/02/10/how-does-google-index-tweets-today-how-the-new-twitter-deal-will-impact-seo/
For more information about Five Blocks, visit us at https://www.fiveblocks.com or contact Aaron Friedman at aaronf@fiveblocks.com or 847-877-85174 with any inquiries how we can help.
Five Blocks Sponsors the Global PR Summit, Miami 2014
Five Blocks is very excited this week to be sponsoring the Global PR Summit in Miami! With over 350 attendees representing many of the largest and most influential PR firms in the US, we expect this conference to be a great event for Five Blocks!
Paul Holmes has been kind enough to set up a session where we will explore Digital Crisis Management – specifically what PR firms and communications team can do to handle the online fallout of real-world crisis situations.
Five Blocks works with some of the largest PR firms represented in the Holmes 250 as well as many smaller independent PR firms.
We focus on translating the PR Team’s efforts so that they are fully reflected online. We also work to remove incorrect information and de-emphasize content that is libelous or otherwise unfavorable to our clients.
If you are here in Miami – we would love to meet with you!
Find us, email, or call to set up some time:
Sam Michelson
samm@fiveblocks.com
(646) 801.8669
Manage Your Identity: Impersonator Accounts on Social Media

Digital reputation management requires vigilance and initiative, on many fronts. Search engine result pages, social media, SEO, PR, and Wikipedia are all realms of one’s online presence that must be actively managed in order to ensure an accurate and favorable representation. One aspect of social media that can be particularly damaging to high profile individuals or brands is the prevalence of false, and often malicious, impersonators.
The anonymity of the internet affords people the opportunity to create fake social media accounts using names of high profile individuals and brands. Often, these fake accounts are inactive; these profiles rarely post any new updates, and they may never be seen by users of the particular social media platform in question. However, these accounts can be damaging regarding search engine results. Search engines may mistakenly identify a phony profile with the actual individual, and then display this result to a user who is searching that name.
Some of these fake accounts are barely fleshed out and clearly nonsensical, but even accounts of this sort can be misleading or confusing for both search engines and real users. Other fake accounts can be more pernicious. These profiles may carry unfavorable images, nasty taglines, or other fields that mock or criticize an individual or a brand.
It is thus imperative for people and companies interested in controlling their online identity to keep an eye on major social media channels for impersonators. Fortunately, the major social media platforms are aware of this problem, and they do offer the opportunity to report false accounts and to request their removal. Note that you may be asked to provide a copy of some form of identity verification, such as a valid driver’s license. With your awareness of this digital reputation threat and by taking active steps in response to any specific incidents, these fake accounts can often be eliminated.
Here are some helpful URL’s which outline steps you can take in each of the major social media channels in order to file a report of impersonation with a request for profile deletion:
http://help.linkedin.com/app/answers/detail/a_id/30200/kw/fake+profile
https://www.facebook.com/help/www/174210519303259
https://support.twitter.com/forms/impersonation
https://support.google.com/plus/troubleshooter/1715140?hl=en
https://help.instagram.com/446663175382270/
In-Depth Articles…but Shallow Market Penetration?
Followers of this blog know that we have been eyeing for months the phenomenon of in-depth articles and their potential impact on reputations of companies and individuals online. First, we watched their appearance last August, then their tentative migration up the results page from their original placement at the bottom and now their wild disappearing and reappearing act.
Through the beginning of this year, things were pretty steady with about 10% of the companies in the Fortune 500 showing results that included in-depth articles. Just at the end of February, however, the fluctuations began, with nearly 20 companies losing their in-depth articles one day, and then some bouncing around.
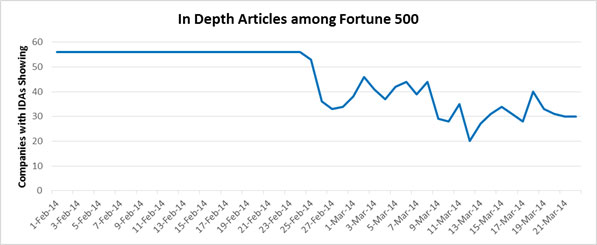
At the lowest point, nearing mid-March, only 20 companies had in-depth articles, a drop-off of 64% from the 56 that began February!
For now, it looks like Google’s in-depth article experiment is still in progress and it remains unclear where this moving target will land. And while we cannot claim to be in Google’s head to explain what’s going on, we can hazard a guess.
On the theory that Google’s aim is to make search results ever more useful for searchers, we have to wonder how useful these in-depth articles have been. Unlike news results, which can change daily, reflecting changes in the world, or profiles and background pieces (e.g. Wikipedia) useful for reference, we suggest that in-depth articles – lengthy and often with a slant – may not be seeing repeat visits. Moreover, their length makes them time consuming to read, making it difficult for the average searcher to get in, get the gist, and get on to something else.
For all the companies with unfavorable in-depth articles, a shift away from them would be a good turn. Ultimately, though, whether this experimentation means in-depth articles are approaching their sunset – or if something else is on the horizon – is anyone’s guess. Meanwhile, we will continue to monitor the course of Google’s current lab work.
In-Depth Articles Rising From the Depths
It looks as though Google just couldn’t wait to celebrate the six month anniversary of one of its newest search results feature, In-Depth Articles. In the last few days, there has been a subtle but important change regarding the placement of in-depth articles in the Google search results.
Rather than appearing as the bottommost group of results as they have since their introduction on August 7th last year, in-depth articles for a handful of companies (including Dell and Ford, shown below) have been promoted, with some of the organic results now appearing below them.
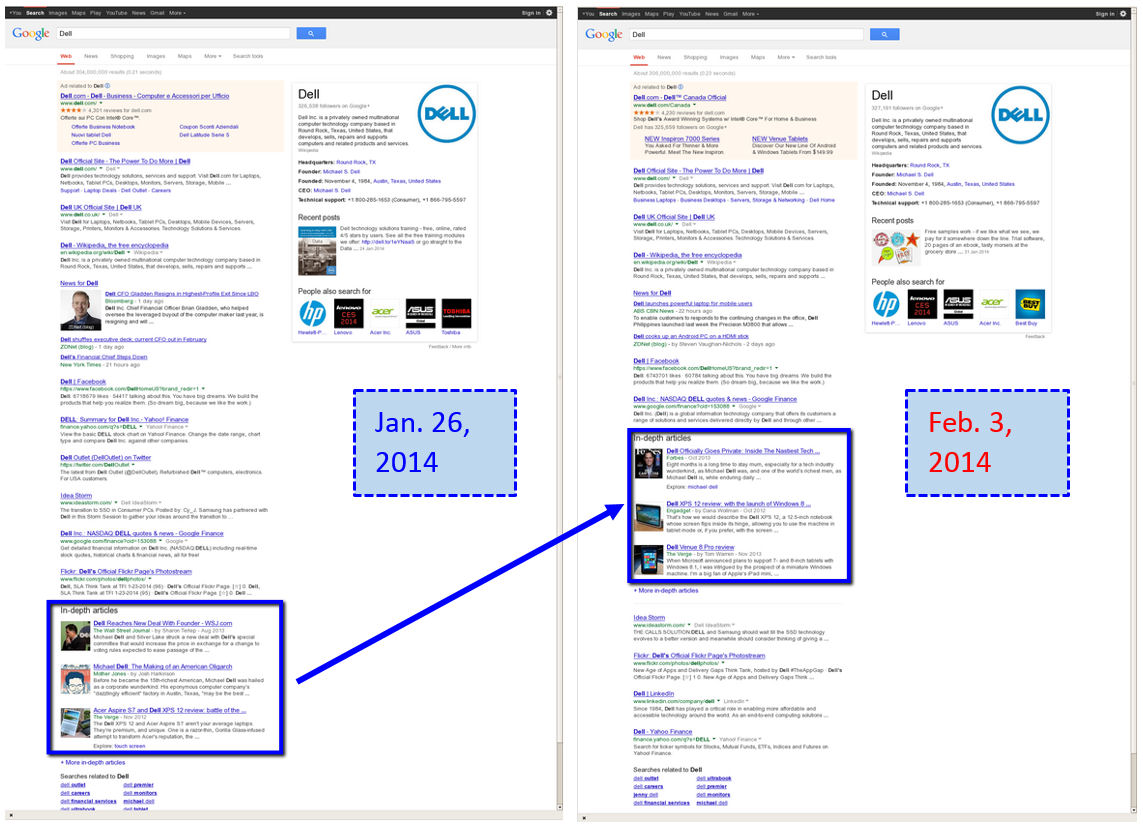
That’s the subtle part. But why is that important?
The in-depth article box is Google’s way of highlighting long-form journalism and ensuring articles of this type persist in first page results for the increasing list of companies for which they appear.
While the depth of their content makes them relevant long beyond the always-changing news landscape, by and large they are unfavorable portrayals of the companies they’re about. As digital branding consultants, Five Blocks has been closely following in-depth articles for the past six months. For our clients, as well as many of their competitors, in-depth articles are a force to be reckoned with, specifically because they (and their mostly unflattering content) stick around even as other search results on the page come and go.
This latest move by Google to start inching in-depth articles up the page, placing them above some of the organic results, suggests even greater popularity for this type of search result. It also underscores the importance of careful strategic planning to ensure a favorable online brand image. Like it or not, Google’s inclusion and promotion of the in-depth articles means they are an integral part of a brand’s online story. It’s no longer enough to tell your story on your own sites, be socially active, and make the news. The brand story will need to be told by engaging magazines and other long form publications to utilize the opportunity afforded by in-depth articles rather than becoming a victim of them.
PR professionals and corporate communications specialists know that these stories usually take several months to write and photograph, so the path involves planting seeds ahead of time and being willing to own up to missteps as well as successes. For more about the potential impact of in-depth articles on PR and Digital Marketing firms, click here. It follows that the long form article will not be 100 percent positive. Companies need to take a strategic approach and realize that if they warrant one long form article, there will likely be more to follow. Brands should look for opportunities to proactively pitch and place these coveted long form articles with the goal of ‘owning’ at least part of the in-depth conversation about their brand.
Digital Reputation Management: It’s Not All About Burying Results

I posted the following on Business Insider in response to a post that focused on the underbelly of the Digital Reputation Management industry.
Many companies and individuals who have online reputation issues are not trying to bury negative reviews or articles. Instead, they are working to make sure that people searching for them online find what they are looking for. This need often arises when the brand or individual has not made any effort to create an online presence (think either a minimal website or none at all, no participation in social media, no business profiles, no YouTube channel, etc.)
Take for example a financial services firm which mostly arranges M&A’s. An article on a popular business news website portrays a potential upcoming deal for the company in a negative light – probably due to the author’s view of the industry in which the company is involved. The financial services company isn’t active online. They have a one-page website that does not appear prominently in searches online. Most of the prominent mentions of the firm seen in a Google search contain contact information, SEC documents and occasional mentions on investor portals.
The goal of an online or digital reputation management program for this client (and many like it) is to help the client present their brand appropriately online. There really is no need to subvert any search engine algorithm or bury any results.
The Digital Reputation Management program would consist of elements such as:
- Building out the current website so that it is technically sounds and contains content that will help it rank well in search engines.
- Creating company and individual profiles on sites like: LinkedIn, CrunchBase, and others.
- Working with Wikipedia editors to correct any incorrect information appearing in Wikipedia – including providing sources to editors that they can quote.
- Registering the brand and key individuals on social media websites that may be appropriate to use in the future (Twitter, Google+, etc.).
- Working with the client’s communications team (or their external PR firm) on opportunities for publishing thought leadership materials in one or more relevant media outlets.
In short, there are many tools at the disposal of digital band management professionals that, rather than being exercises in removing negativity, are proper digital branding and communication efforts. Rather than focusing on fooling the algorithm (in the long term Google will beat you!), serious companies should be considering digital reputation management strategies and tactics that take advantage of Google’s algorithm and its ability to detect relevant, authoritative content from a variety of sources.
Betting Your Reputation on an Algorithm
![]() In today’s hyper-competitive business environment, it is challenging for traders and advisors to maintain an edge. Many wealth managers divide their time with conducting industry research, prospecting, managing their clients’ diverse holdings and exploring new opportunities.
In today’s hyper-competitive business environment, it is challenging for traders and advisors to maintain an edge. Many wealth managers divide their time with conducting industry research, prospecting, managing their clients’ diverse holdings and exploring new opportunities.
In the digital age, a new skill has an increasingly forceful impact on their business: digital branding. Brokers and traders need an online presence that communicates their business story.
What is an ‘online presence’? Read More …
Hedge Fund Leadership Succession
Situation: When investing with a hedge fund, investors want to know and trust the name behind the firm. The managing partner of a leading hedge fund – the face of the company in the press – left the firm for a political appointment. The hedge fund was left with a new managing partner who had a limited public and online presence. The hedge fund turned to Five Blocks to increase, and then manage, the presence of the incoming partner.
Challenges: While the departing executive had a strong public and online presence, the succeeding partner’s online presence was confusing and disjointed. Rather than a corporate bio and other expected search results, a search for his name resulted in Facebook pages and images of other people with the same name. The firm was understandably concerned that these results would damage investor confidence.
Solutions: To establish the managing partner’s presence, Five Blocks executed a program which included:
- Enhancing Digital Presence: Coordinating changes to the firm’s corporate website and ensuring the managing partner’s prominence in search engine queries.
- Wikipedia Efforts: Working with Wikipedia editors, Five Blocks helped to create and submit a Wikipedia page with appropriately sourced content and a professional image. This content was subsequently used by the media.
- Optimizing Content: Ensuring that relevant links appeared when stakeholders queried the managing partner on a search engine.
Results: Within a few months of Five Blocks working with the hedge fund, results included:
- The succeeding partner appeared far more prominently in queries for the fund.
- The managing partner was featured in a list of the most powerful people on Wall Street in a leading business publication. All of the content about the managing partner was sourced from their Wikipedia page initiated by Five Blocks.
- The managing partner earned a Google Knowledge Graph (see below) which presented him as a recognized entity online.
- The managing partner told Five Blocks that their efforts helped build trust with current and potential investors.
So, You’re Working on Digital Brand Alignment for a COUNTRY!
We have had opportunities to work with governments, NGO’s and organizations of all types.
Before we can advise a client on the steps they should be taking, we need to understand the context. When working with a country, it is important to ascertain what results are normal for a country.
Clients will usually say something like, “CIA Fact Book?! Why is the entry for CIA Fact Book coming up so high for us? Does Google consider our (banana?) republic a terrorist state?”
To answer these and other questions we start by looking at the expected results for countries.
Below is a chart for Dec 17, 2012 showing the most frequently appearing domains for countries searched in Google. This table considers the first page of Google as seen in the US only. Note that results in any specific location may vary, so that searching in Google.fr (France) would be expected to yield more sites that pertain to that location.
Numbers on the chart indicate the number of countries displaying this domain in their first page Google results.
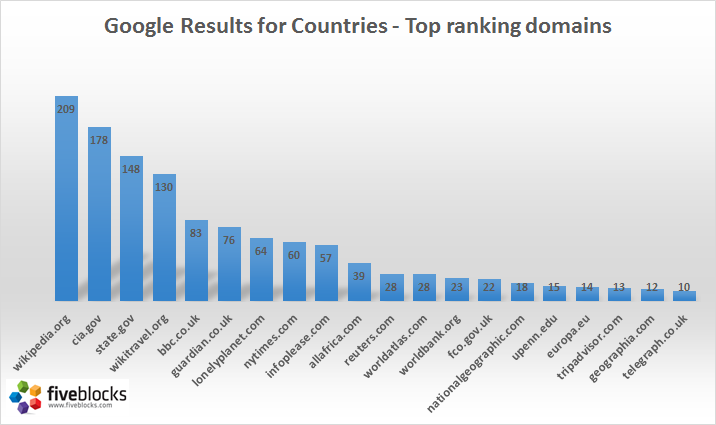
It is interesting to note that cia.gov and state.gov dominate the results along with the ubiquitous Wikipedia. If you are responsible for the branding of a country, this table serves as some initial context. Any site here that also appears for your country should not be a shock.
One of the surprises for me was a site called infoplease.com (by Pearson Education) which ranks for 57 countries* even though it is of lower quality! I’m actually not sure what to make of it – it may well appear in situations where a country has not done even a basic job of creating or curating web content that can outrank this low quality scraper search site. (*In case you want to dig deeper, the complete list is at the bottom of this post.)
Also – the role of community-generated content for country results should not be underestimated – Wikipedia and Wikitravel each serve as top domain results for most countries. This certainly suggests that ignoring community content would be unwise.
So what’s your strategy?
In general, your goal should be to design the ultimate branding and focus. Perhaps you would prefer results focused more on industry rather than tourism or political news? With that in hand, you’ll develop strategies to achieve these goals.
If you have questions or comments or would like to dig deeper into the data with us – feel free to drop us a line.
*Countries for which infoplease.com ranks in the top page of Google results:
1. Algeria
2. Andorra
3. Angola
4. Argentina
5. Armenia
6. Bahamas
7. Bangladesh
8. Bosnia and Herzegovina
9. Burundi
10. Cambodia
11. Cameroon
12. Cape Verde
13. Chile
14. Colombia
15. Cuba
16. Denmark
17. El Salvador
18. Equatorial Guinea
19. Ethiopia
20. France
21. Gabon
22. Guatemala
23. Guyana
24. Haiti
25. Honduras
26. Hungary
27. Indonesia
28. Italy
29. Kyrgyzstan
30. Laos
31. Lithuania
32. Malawi
33. Malaysia
34. Mali
35. Marshall Islands
36. Micronesia
37. Monaco
38. Mongolia
39. Morocco
40. The Netherlands
41. Nicaragua
42. Nigeria
43. Papua New Guinea
44. Peru
45. Poland
46. Portugal
47. Romania
48. São Tomé and Príncipe
49. Senegal
50. Spain
51. Uganda
52. Ukraine
53. United Kingdom
54. Uruguay
55. Uzbekistan
56. Venezuela
57. Yemen
Brand Reputation for the FTSE 100 vs. the Fortune 100
Before we can start work aligning a brand’s online reputation to match their corporate objectives, we need to understand something about the playing field.
We need to understand what types of results are typical for brands in the same market. Many of our clients are Fortune 100 and Fortune 500 companies, so we have done extensive research into this market.
Below is a table depicting the frequency with which we find various sites as top ten results in Google’s natural search results. (Data is from Nov 9, 2012).
The number above each bar represents the number of company search results in which each website appears.
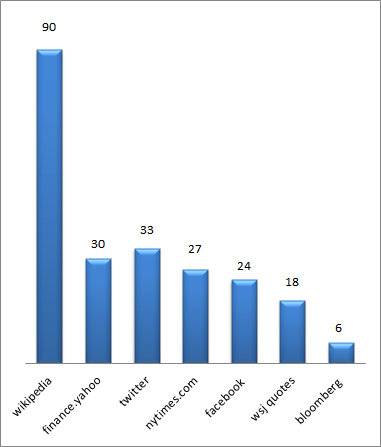
As you can see from this chart, the most prevalent result for companies in the Fortune 100 is Wikipedia – appearing in 90% of page one results for Fortune 100 companies.
It’s interesting to note that Facebook and Twitter are each appearing in F100 first page Google results about 25% of the time.
Also interesting is that Yahoo Finance continues to be an important finance site as compared to Google Finance – which does not show up in the top ten.
A takeaway for companies in the space would be to look at the frequently occurring websites and determine if your brand should also have similar results. Knowing that Google tends to “like” showing a specific type of result seems to make it low-hanging fruit – an easy win if it’s something that will help your online reputation.
What about the FTSE 100?
In preparation for a week of meetings in London, we decided to compare the same type of data as seen in Google.co.uk results for the FTSE 100.
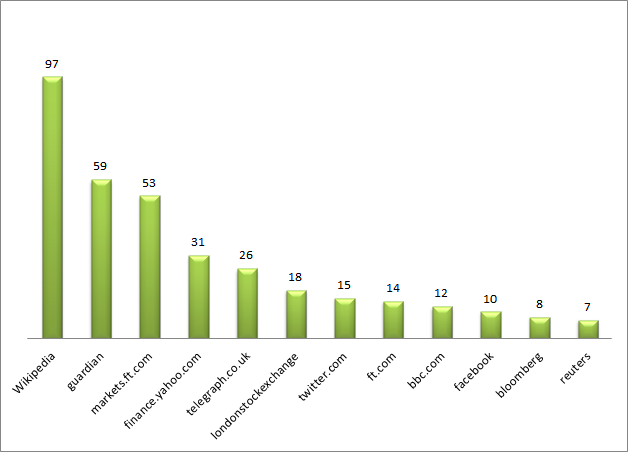
In the UK, Wikipedia is even more prevalent. Only 3 FTSE 100 companies have no Wikipedia page appearing in their Google page 1 results! Also noteworthy is the strength of The Guardian as a result shown in the first page Google results for 59% of all FTSE 100 companies! (Note to PR department – The Guardian is more likely to impact online reputation than the BBC, The Telegraph and Reuters combined!). In the UK Markets.ft.com outranks Yahoo Finance in prevalence by a significant margin, with Yahoo Finance still maintaining a significant foothold.
On the social media front, Twitter and Facebook are less than half as likely to be in the Google first page search results for a FTSE 100 company – as compared to a Fortune 100 company.
Notable as well is that neither group has video results coming up with any frequency. Image results show up in 6 of the FTSE 100 search results, but in only 2 of the Fortune 100 first page results.
With this knowledge, we are better prepared to look at FTSE 100 companies – and indeed at company results for other companies in the UK with a better understanding of which sites play significant roles in online reputation. When we approach a client program, we then take the additional step of doing a more exact comparison of the peer group – the companies or individuals that are most similar to the client. This offers further insight as to the way in which Google treats those keywords within the local search market.
How Agencies Can Help In-House SEO’s
At Five Blocks, we focus on Digital Brand Management and Reputation Management – which require a lot of the same knowledge as SEO. Clients who engage with us for Digital Brand Management often have SEO needs as well – and this is a service we offer. Interestingly, even clients who have their own SEO teams benefit from our services.
A few reasons why in-house SEO teams benefit by working with an agency.
1) When I started optimizing my first website in 2003, it was reasonable for one or two people to take on all of the responsibilities of optimization. Since then, there has been an explosion of different angles that should be addressed: Webmaster Tools, sitemaps, landing page optimization, new search engines, video optimization, etc.
2) Because we service tens of clients, we can afford to maintain a team of writers and many web assets on a variety of topics. We can provide SEO services to these clients without having to create completely new assets or hire new writers.
3) We are exposed to clients in many industries – and are challenged every day across tens of clients. As we meet each challenge, we are able to apply the lessons to additional client programs. In-house SEOs are not typically exposed to too many clients at any given time.
Taken together, it is reasonable for a company to have one or more in-house SEOs and for those SEOs to work with an external team who can help achieve measurable results by leveraging the agency’s resources, tools, and knowledge.
The Five Blocks Logo
A little nostalgia…
These were some of the designs from which we had to choose when we designed the Five Blocks logo!
![]()
‘Disgusting Dominos’ Tops Dominos Searches
One of the great things about Online Reputation Management is that it includes more than just creating some blogs or generating links. It’s a lot about the perception of searchers. How do they view your company? What frame of mind are they in? What can you do to change impressions? The variety of tactics we utilize in repairing online reputations is constantly evolving. Eighteen months ago we hardly touched Twitter; now it’s a staple. Google’s personalized profiles are also a new development – allowing any user to grab the profile page for their name (which shows up instantly just below the Google top ten with a picture).
In this fast-paced environment, we make sure to see and evaluate what happens a week or more after a crisis.
The Domino’s Test
On April 21, 2009 our company decided to run Google Ads in order to gauge the longer-term effects of negative publicity from Domino’s Pizza’s now infamous “disgusting video.” Our test took place more than a week after the release of the famous employees YouTube video.
Aside from over 25,000 impressions, coming primarily from ads appearing on YouTube, we measured over 3,000 searches for the broad term ‘disgusting dominos.’
Domino’s themselves evidently realized that this would be the ‘best’ keyword to capture the crisis and decided to make their YouTube response title: “Disgusting Dominos People – Domino’s Responds”. This was probably at the urging of their SEO expert. While the best way to rank a YouTube video for a keyword is to start the title of the video with your keyword, I would argue that the negative aspect of having the CEO’s picture under the title “Disgusting Dominos” is a reason to veer away from this tactic. Instead, I would have recommendeded “Dominos CEO responds to Disgusting Dominos People Video.” The actual video file should probably have been called “Disgusting Dominos” as we have seen empirically the effects of the file name itself outweighing the video title. Using the keyword as the title of the video file is very helpful in making sure the video shows up in YouTube for your keyword.
Disgusting Domino’s – the Top Keyword for the Domino’s Crisis in Reputation Management

We noted that throughout our test, Domino’s Pizza themselves did not seem to be running any Google Ads – possibly a missed opportunity to reassure searchers that Domino’s is aware of the issue and is proactively dealing with it.
Note: Domino’s is a trademark of Domino’s Pizza. This site is not related to Domino’s in any way.
Domino’s Pizza Retrospective: Why PR Must Own the “Google Top Ten” in Today’s Era of Online Reputation Management
This piece was written by David Goldman and originally appeared in the Daily Dog on April 27, 2009.
![]()
PR firms are responsible for their client or company’s reputations. Similar to the Domino’s fiasco, if a negative video or blog reaches into the top ten of Google search results for a client’s brand name, it’s called a “PR problem.” So why aren’t PR firms called on more often to fix the problem with their client’s online reputation?
One answer is that most people assume that Google search results are like the weather. We have the tools to measure them and possibly predict them, but we can’t change them. Fortunately, the situation isn’t that bad. Experienced online reputation management (ORM) firms working in tandem with PR firms can control a client’s search profile. The best way to get rid of negative results on Google is to take control of your reputation online. Another answer is that online reputation management should belong to the client’s SEO firm. This is a missed opportunity for PR and oftentimes untrue.
Progressive agencies are taking ORM seriously, partnering with firms or making internal hires to accommodate the growing need for bridging their traditional and even online efforts to ORM services. They realize that PR firms are competing with SEO companies to provide these services and understand the strategic as well as the financial sense in getting there first. Agencies should understand that they are often creating the message and image of the brand while SEO firms are technology people.
The Domino’s Case Study—Timely ORM Tips to Consider
Just over a week after the Domino’s “PR Nightmare,” many communications professionals are asking two questions: What can the brand do to salvage its reputation after the fact? And what can we do to prevent our clients from a similar crisis? Here is how our firm would work with Domino’s PR to clean up the mess:
There are at least three things that Domino’s Pizza should be doing now to clean up their online reputation. Although the buzz around the infamous video will continue to wane, the postings and marketing articles about the incident have the potential to linger for months, possibly years, unless the brand takes action. If you’re Domino’s, here’s what you need to do today:
1. Tweet to a stronger presence online. A company that is such an important part of American culture should be actively creating positive buzz online. Domino’s didn’t even have a Twitter account until after the crisis broke.
Pizza Hut recently posted a job offer for a summer intern to work on their Twitter account (see the posting here: http://news.cnet.com/8301-17852_3-10223100-71.html). That’s the type of planning that helps soften a social media crisis when it arises. With 125,000 employees at their disposal, Domino’s could easily distribute an internal memo advocating that employees open Twitter accounts and post positive comments about the work environment and the company. Twitter is one of the fastest ways to have a positive impact on a brand. Domino’s employees have a real interest in making their brand popular and keeping it strong. This will not only help supplant the negative content from the top search results in time, but help prevent a future crisis as well.
2. Develop and execute a video strategy. Currently, most of the videos that appear on YouTube and video-sharing websites for the keyword “dominos” are not about Domino’s Pizza. Had Domino’s occupied the top ten spots on YouTube for the keyword “dominos,” the effects of a rogue negative video would have been greatly mitigated. There was a lost opportunity as the millions of searchers for the keyword “dominos” could have also been exposed to positive messages from the brand in the form of videos.
In addition, the brand’s TV commercials should be systematically re-posted and optimized so they occupy the top spots for video searches of the word “dominos.” Management should also ask employees to create YouTube videos promoting the brand, empowering the employees to feel like they are part of the solution, not only the problem.
3. Go “deep”—leverage mini-sites. Domino’s probably thought that by having a consumer-focused website and a corporate homepage they had their bases covered. In truth, their web presence is shallow.
Creating mini-sites on a few important topics can garner excellent PR while protecting the brand’s online reputation. Some topics Domino’s could consider for mini-sites: a) Passion for Pizza (The Internet is the perfect medium for expressing the passion you have for your product or service.), b) Domino’s and the Environment (focusing on recycling or other green initiatives), and c) Domino’s Scholarships (or Domino’s Community Projects). Each of these mini-sites can occupy a top spot in the Google results if created and optimized by ORM experts.
The Bigger Picture—Why PR Must Own ORM
All of these suggestions are facets of a full-service online reputation management program. When ideas like these are implemented together with a program of reputation management focused on positive articles and links, a negative situation can be transformed into a reputation-building opportunity.
Although Online Reputation Management (ORM) has existed for several years, today the need for this service is more relevant than ever. It isn’t a question of whether companies need and seek this type of service anymore. The real question is: To whom will they turn?
We have met with many PR firms in the U.S. who offer a “blogging strategy,” creating and maintaining an optimized corporate blog for their clients. While this is an excellent first step, online reputation management requires much more than one well-run blog. These firms often subscribe to outside services in order to track their client’s reputation online, but rarely do they offer a solid measurable solution.
So what is the better model?
Answer: Stop offering blogs and start offering “search profile optimization.” A search profile is essentially what someone sees when they search for your client’s brand or product name; it’s the “Holy Grail of Search;” it’s the Google top ten. Today, there are several ORM firms with whom agencies and consultants can partner—offering a white-label solution to their clients to improve their search profiles. The ORM firm provides charts and graphs that track the progress of their work for the PR firm to merchandise back to the client with their ‘look and feel.’
There are methods (especially for clients who are vulnerable to the “Domino’s Effect”) that can greatly reduce the collateral damage of a scandal before it takes place. By “owning” the Google top ten before a crisis breaks out, PR firms can effectively prevent a catastrophe. On a brand’s marketing team, only the PR firm knows when the bad news is coming. Whether it’s layoffs, a poor earnings report or a discrimination lawsuit, this knowledge can be used to minimize damage to the brand by securing the Google top ten in advance of the negative announcement.
Providing ORM services for clients is a way for PR firms and crisis communications professionals to stay vital to their clients and gives clients another reason to stick with their agencies. In this uncertain economy, every PR professional should be finding new ways to increase revenues and retain their clients. Offering ORM services allows PR firms to do both.